 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMP-AR: Granularity Message Passing and Adaptive Reconciliation for Temporal Hierarchy Forecasting
Jun 18, 2024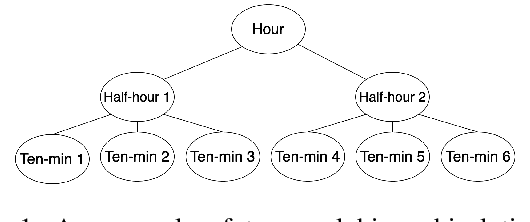
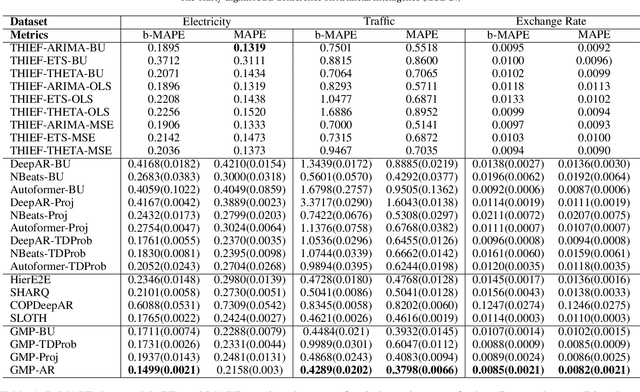
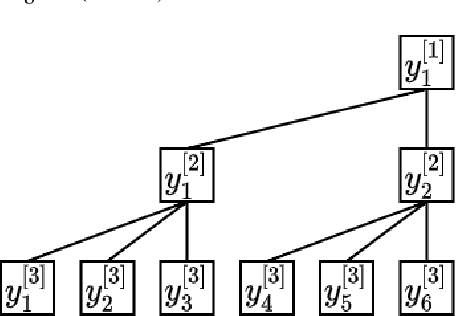
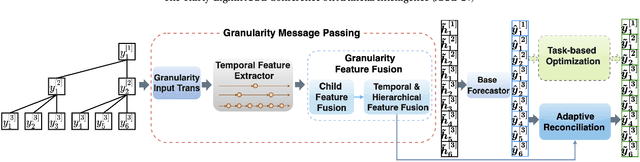
Time series forecasts of different temporal granularity are widely used in real-world applications, e.g., sales prediction in days and weeks for making different inventory plans. However, these tasks are usually solved separately without ensuring coherence, which is crucial for aligning downstream decisions. Previous works mainly focus on ensuring coherence with some straightforward methods, e.g., aggregation from the forecasts of fine granularity to the coarse ones, and allocation from the coarse granularity to the fine ones. These methods merely take the temporal hierarchical structure to maintain coherence without improving the forecasting accuracy. In this paper, we propose a novel granularity message-passing mechanism (GMP) that leverages temporal hierarchy information to improve forecasting performance and also utilizes an adaptive reconciliation (AR) strategy to maintain coherence without performance loss. Furthermore, we introduce an optimization module to achieve task-based targets while adhering to more real-world constraints. Experiments on real-world datasets demonstrate that our framework (GMP-AR) achieves superior performances on temporal hierarchical forecasting tasks compared to state-of-the-art methods. In addition, our framework has been successfully applied to a real-world task of payment traffic management in Alipay by integrating with the task-based optimization module.
Deep Optimal Timing Strategies for Time Series
Oct 09, 2023



Deciding the best future execution time is a critical task in many business activities while evolving time series forecasting, and optimal timing strategy provides such a solution, which is driven by observed data. This solution has plenty of valuable applications to reduce the operation costs. In this paper, we propose a mechanism that combines a probabilistic time series forecasting task and an optimal timing decision task as a first systematic attempt to tackle these practical problems with both solid theoretical foundation and real-world flexibility. Specifically, it generates the future paths of the underlying time series via probabilistic forecasting algorithms, which does not need a sophisticated mathematical dynamic model relying on strong prior knowledge as most other common practices. In order to find the optimal execution time, we formulate the decision task as an optimal stopping problem, and employ a recurrent neural network structure (RNN) to approximate the optimal times. Github repository: \url{github.com/ChenPopper/optimal_timing_TSF}.
EasyTPP: Towards Open Benchmarking the Temporal Point Processes
Jul 16, 2023Continuous-time event sequences play a vital role in real-world domains such as healthcare, finance, online shopping, social networks, and so on. To model such data, temporal point processes (TPPs) have emerged as the most advanced generative models, making a significant impact in both academic and application communities. Despite the emergence of many powerful models in recent years, there is still no comprehensive benchmark to evaluate them. This lack of standardization impedes researchers and practitioners from comparing methods and reproducing results, potentially slowing down progress in this field. In this paper, we present EasyTPP, which aims to establish a central benchmark for evaluating TPPs. Compared to previous work that also contributed datasets, our EasyTPP has three unique contributions to the community: (i) a comprehensive implementation of eight highly cited neural TPPs with the integration of commonly used evaluation metrics and datasets; (ii) a standardized benchmarking pipeline for a transparent and thorough comparison of different methods on different datasets; (iii) a universal framework supporting multiple ML libraries (e.g., PyTorch and TensorFlow) as well as custom implementations. Our benchmark is open-sourced: all the data and implementation can be found at this \href{https://github.com/ant-research/EasyTemporalPointProcess}{\textcolor{blue}{Github repository}}\footnote{\url{https://github.com/ant-research/EasyTemporalPointProcess}.}. We will actively maintain this benchmark and welcome contributions from other researchers and practitioners. Our benchmark will help promote reproducible research in this field, thus accelerating research progress as well as making more significant real-world impacts.
Automatic Deduction Path Learning via Reinforcement Learning with Environmental Correction
Jun 16, 2023

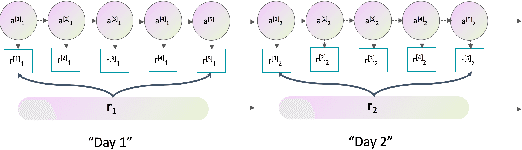

Automatic bill payment is an important part of business operations in fintech companies. The practice of deduction was mainly based on the total amount or heuristic search by dividing the bill into smaller parts to deduct as much as possible. This article proposes an end-to-end approach of automatically learning the optimal deduction paths (deduction amount in order), which reduces the cost of manual path design and maximizes the amount of successful deduction. Specifically, in view of the large search space of the paths and the extreme sparsity of historical successful deduction records, we propose a deep hierarchical reinforcement learning approach which abstracts the action into a two-level hierarchical space: an upper agent that determines the number of steps of deductions each day and a lower agent that decides the amount of deduction at each step. In such a way, the action space is structured via prior knowledge and the exploration space is reduced. Moreover, the inherited information incompleteness of the business makes the environment just partially observable. To be precise, the deducted amounts indicate merely the lower bounds of the available account balance. To this end, we formulate the problem as a partially observable Markov decision problem (POMDP) and employ an environment correction algorithm based on the characteristics of the business. In the world's largest electronic payment business, we have verified the effectiveness of this scheme offline and deployed it online to serve millions of users.
A positive feedback method based on F-measure value for Salient Object Detection
Apr 28, 2023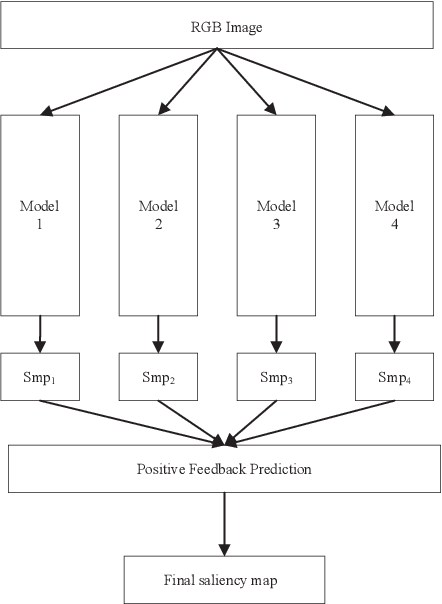


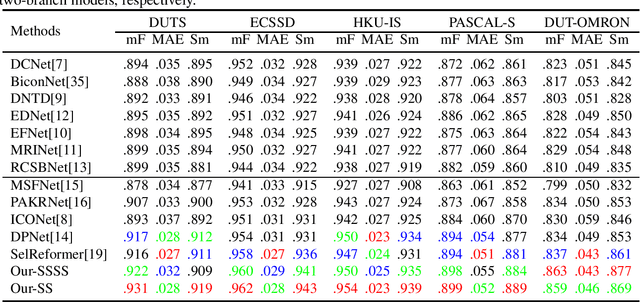
The majority of current salient object detection (SOD) models are focused on designing a series of decoders based on fully convolutional networks (FCNs) or Transformer architectures and integrating them in a skillful manner. These models have achieved remarkable high performance and made significant contributions to the development of SOD. Their primary research objective is to develop novel algorithms that can outperform state-of-the-art models, a task that is extremely difficult and time-consuming. In contrast, this paper proposes a positive feedback method based on F-measure value for SOD, aiming to improve the accuracy of saliency prediction using existing methods. Specifically, our proposed method takes an image to be detected and inputs it into several existing models to obtain their respective prediction maps. These prediction maps are then fed into our positive feedback method to generate the final prediction result, without the need for careful decoder design or model training. Moreover, our method is adaptive and can be implemented based on existing models without any restrictions. Experimental results on five publicly available datasets show that our proposed positive feedback method outperforms the latest 12 methods in five evaluation metrics for saliency map prediction. Additionally, we conducted a robustness experiment, which shows that when at least one good prediction result exists in the selected existing model, our proposed approach can ensure that the prediction result is not worse. Our approach achieves a prediction speed of 20 frames per second (FPS) when evaluated on a low configuration host and after removing the prediction time overhead of inserted models. These results highlight the effectiveness, efficiency, and robustness of our proposed approach for salient object detection.
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023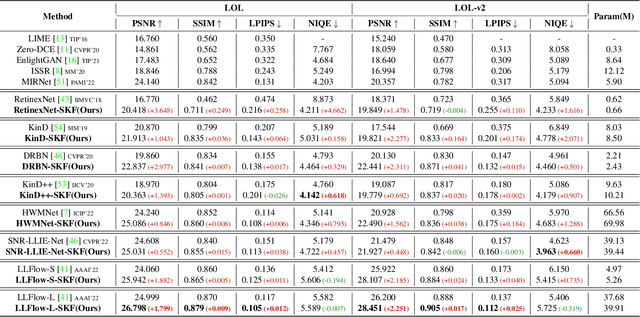
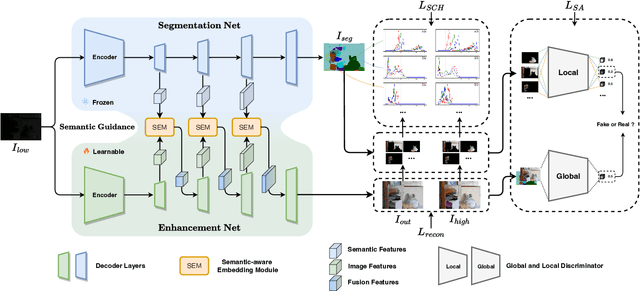
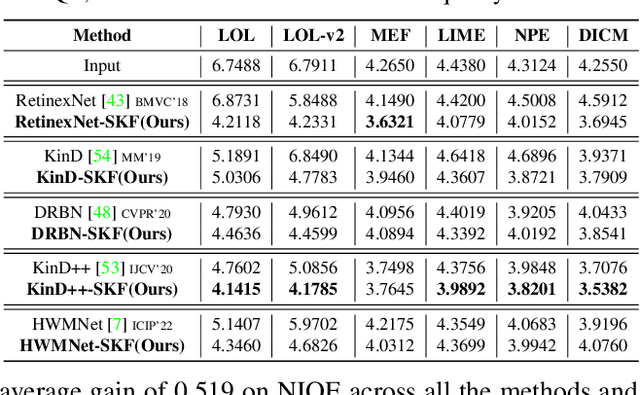
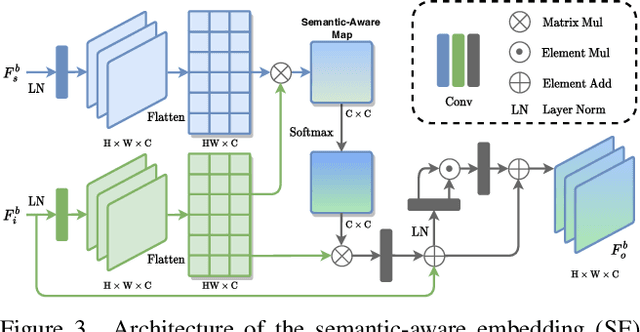
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023
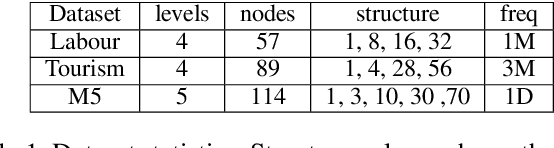
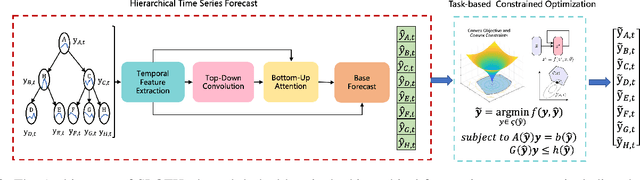
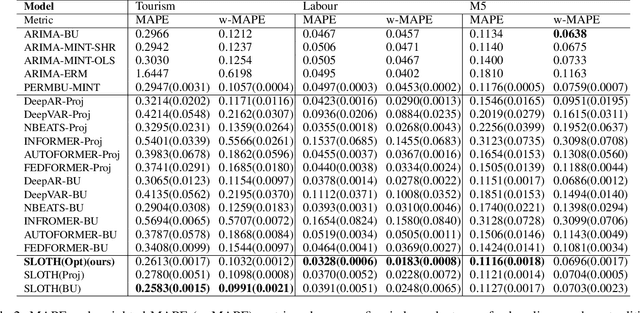
Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints
Enabling Super-Fast Deep Learning on Tiny Energy-Harvesting IoT Devices
Nov 28, 2021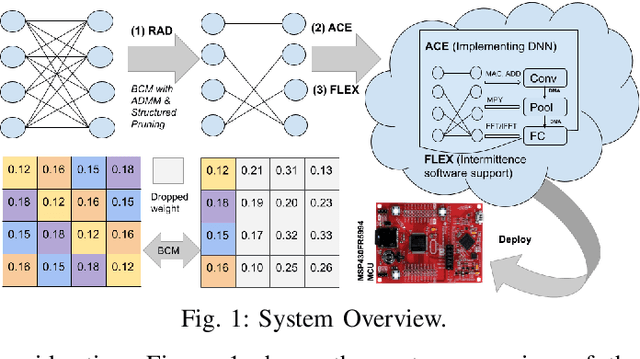
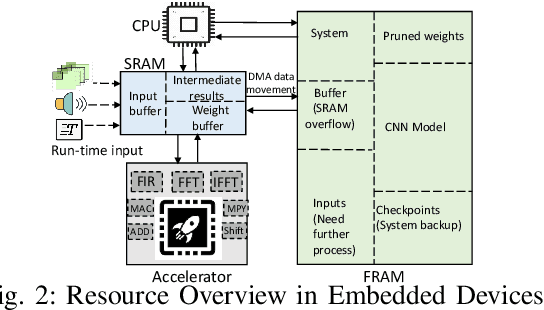
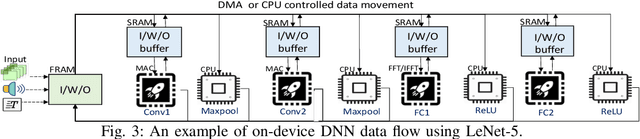
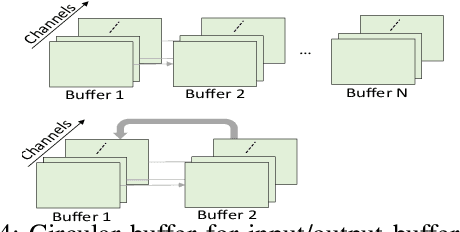
Energy harvesting (EH) IoT devices that operate intermittently without batteries, coupled with advances in deep neural networks (DNNs), have opened up new opportunities for enabling sustainable smart applications. Nevertheless, implementing those computation and memory-intensive intelligent algorithms on EH devices is extremely difficult due to the challenges of limited resources and intermittent power supply that causes frequent failures. To address those challenges, this paper proposes a methodology that enables super-fast deep learning with low-energy accelerators for tiny energy harvesting devices. We first propose RAD, a resource-aware structured DNN training framework, which employs block circulant matrix with ADMM to achieve high compression and model quantization for leveraging the advantage of various vector operation accelerators. A DNN implementation method, ACE, is then proposed that employs low-energy accelerators to profit maximum performance with minor energy consumption. Finally, we further design FLEX, the system support for intermittent computation in energy harvesting situations. Experimental results from three different DNN models demonstrate that RAD, ACE, and FLEX can enable super-fast and correct inference on energy harvesting devices with up to 4.26X runtime reduction, up to 7.7X energy reduction with higher accuracy over the state-of-the-art.