 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoEdit: Content-Consistent Image Editing via Region Regularized Reinforcement Learning
Feb 15, 2026Image editing has achieved impressive results with the development of large-scale generative models. However, existing models mainly focus on the editing effects of intended objects and regions, often leading to unwanted changes in unintended regions. We present a post-training framework for Content-Consistent Editing (CoCoEdit) via region regularized reinforcement learning. We first augment existing editing datasets with refined instructions and masks, from which 40K diverse and high quality samples are curated as training set. We then introduce a pixel-level similarity reward to complement MLLM-based rewards, enabling models to ensure both editing quality and content consistency during the editing process. To overcome the spatial-agnostic nature of the rewards, we propose a region-based regularizer, aiming to preserve non-edited regions for high-reward samples while encouraging editing effects for low-reward samples. For evaluation, we annotate editing masks for GEdit-Bench and ImgEdit-Bench, introducing pixel-level similarity metrics to measure content consistency and editing quality. Applying CoCoEdit to Qwen-Image-Edit and FLUX-Kontext, we achieve not only competitive editing scores with state-of-the-art models, but also significantly better content consistency, measured by PSNR/SSIM metrics and human subjective ratings.
Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
Jul 27, 2025Impressive results on real-world image super-resolution (Real-ISR) have been achieved by employing pre-trained stable diffusion (SD) models. However, one critical issue of such methods lies in their poor reconstruction of image fine structures, such as small characters and textures, due to the aggressive resolution reduction of the VAE (eg., 8$\times$ downsampling) in the SD model. One solution is to employ a VAE with a lower downsampling rate for diffusion; however, adapting its latent features with the pre-trained UNet while mitigating the increased computational cost poses new challenges. To address these issues, we propose a Transfer VAE Training (TVT) strategy to transfer the 8$\times$ downsampled VAE into a 4$\times$ one while adapting to the pre-trained UNet. Specifically, we first train a 4$\times$ decoder based on the output features of the original VAE encoder, then train a 4$\times$ encoder while keeping the newly trained decoder fixed. Such a TVT strategy aligns the new encoder-decoder pair with the original VAE latent space while enhancing image fine details. Additionally, we introduce a compact VAE and compute-efficient UNet by optimizing their network architectures, reducing the computational cost while capturing high-resolution fine-scale features. Experimental results demonstrate that our TVT method significantly improves fine-structure preservation, which is often compromised by other SD-based methods, while requiring fewer FLOPs than state-of-the-art one-step diffusion models. The official code can be found at https://github.com/Joyies/TVT.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
InsViE-1M: Effective Instruction-based Video Editing with Elaborate Dataset Construction
Mar 26, 2025

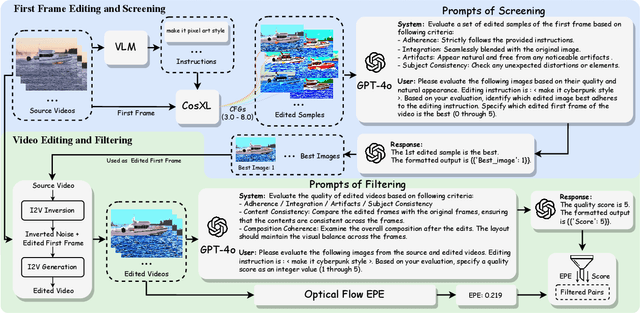

Instruction-based video editing allows effective and interactive editing of videos using only instructions without extra inputs such as masks or attributes. However, collecting high-quality training triplets (source video, edited video, instruction) is a challenging task. Existing datasets mostly consist of low-resolution, short duration, and limited amount of source videos with unsatisfactory editing quality, limiting the performance of trained editing models. In this work, we present a high-quality Instruction-based Video Editing dataset with 1M triplets, namely InsViE-1M. We first curate high-resolution and high-quality source videos and images, then design an effective editing-filtering pipeline to construct high-quality editing triplets for model training. For a source video, we generate multiple edited samples of its first frame with different intensities of classifier-free guidance, which are automatically filtered by GPT-4o with carefully crafted guidelines. The edited first frame is propagated to subsequent frames to produce the edited video, followed by another round of filtering for frame quality and motion evaluation. We also generate and filter a variety of video editing triplets from high-quality images. With the InsViE-1M dataset, we propose a multi-stage learning strategy to train our InsViE model, progressively enhancing its instruction following and editing ability. Extensive experiments demonstrate the advantages of our InsViE-1M dataset and the trained model over state-of-the-art works. Codes are available at InsViE.
ReCo-Diff: Explore Retinex-Based Condition Strategy in Diffusion Model for Low-Light Image Enhancement
Dec 20, 2023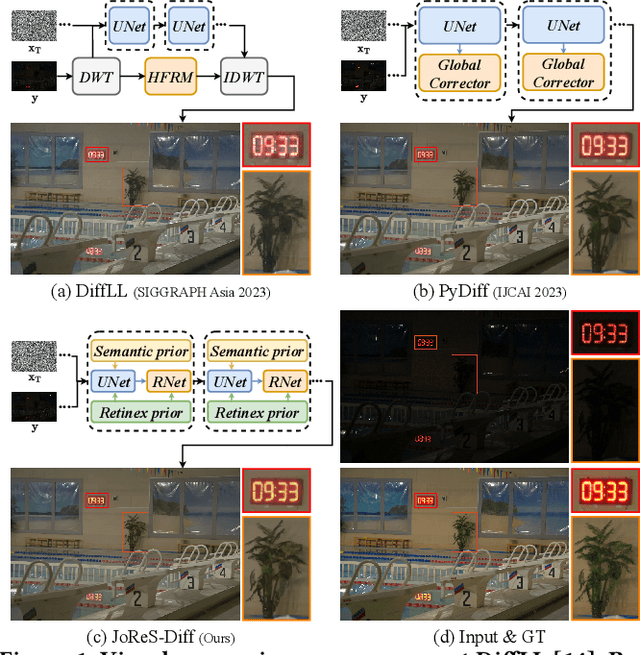
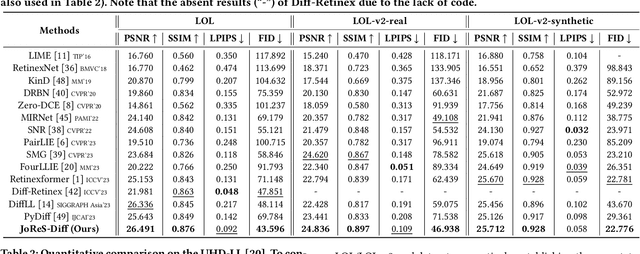
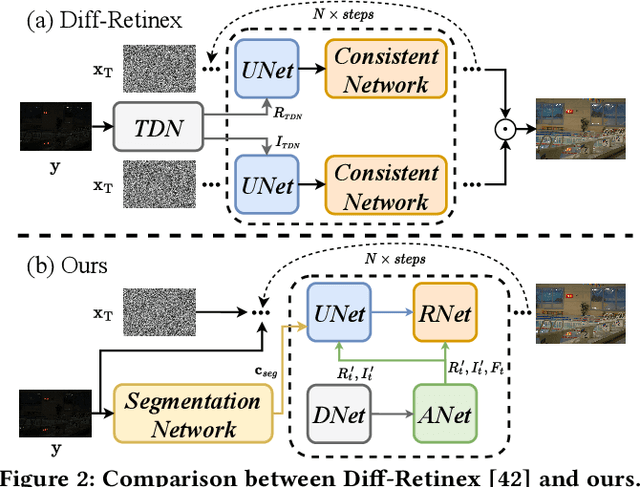
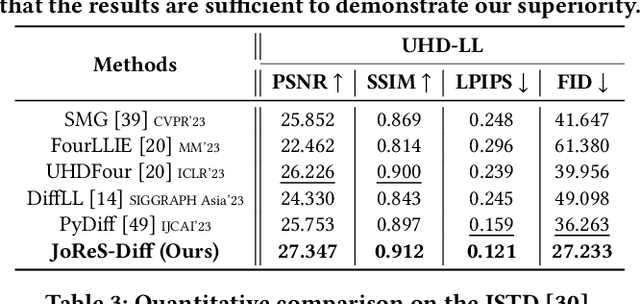
Low-light image enhancement (LLIE) has achieved promising performance by employing conditional diffusion models. In this study, we propose ReCo-Diff, a novel approach that incorporates Retinex-based prior as an additional pre-processing condition to regulate the generating capabilities of the diffusion model. ReCo-Diff first leverages a pre-trained decomposition network to produce initial reflectance and illumination maps of the low-light image. Then, an adjustment network is introduced to suppress the noise in the reflectance map and brighten the illumination map, thus forming the learned Retinex-based condition. The condition is integrated into a refinement network, implementing Retinex-based conditional modules that offer sufficient guidance at both feature- and image-levels. By treating Retinex theory as a condition, ReCo-Diff presents a unique perspective for establishing an LLIE-specific diffusion model. Extensive experiments validate the rationality and superiority of our ReCo-Diff approach. The code will be made publicly available.
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023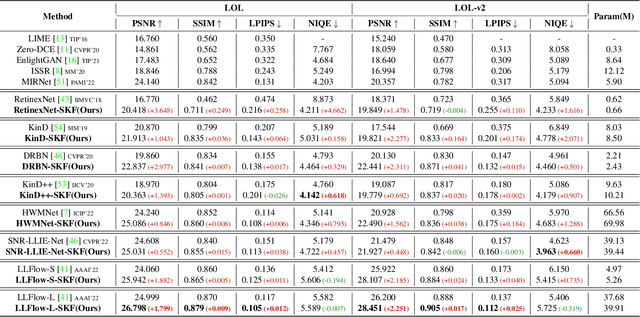
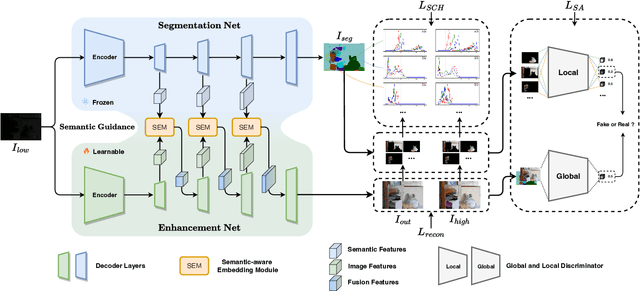
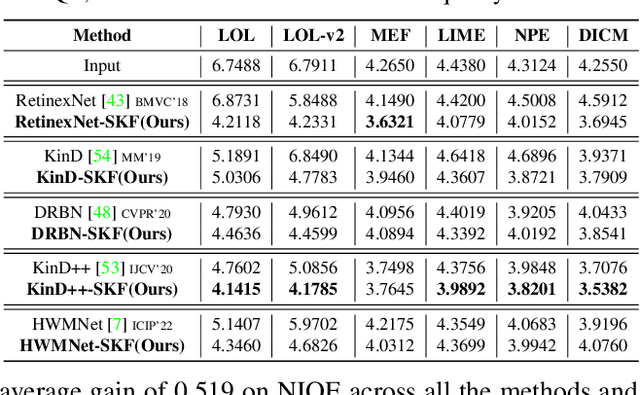
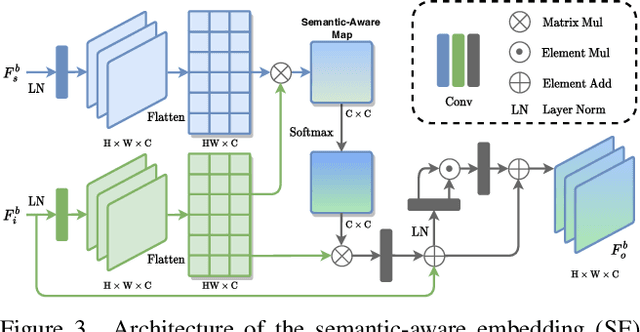
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.
Breaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image Fusion
Nov 22, 2022Infrared and visible image fusion plays a vital role in the field of computer vision. Previous approaches make efforts to design various fusion rules in the loss functions. However, these experimental designed fusion rules make the methods more and more complex. Besides, most of them only focus on boosting the visual effects, thus showing unsatisfactory performance for the follow-up high-level vision tasks. To address these challenges, in this letter, we develop a semantic-level fusion network to sufficiently utilize the semantic guidance, emancipating the experimental designed fusion rules. In addition, to achieve a better semantic understanding of the feature fusion process, a fusion block based on the transformer is presented in a multi-scale manner. Moreover, we devise a regularization loss function, together with a training strategy, to fully use semantic guidance from the high-level vision tasks. Compared with state-of-the-art methods, our method does not depend on the hand-crafted fusion loss function. Still, it achieves superior performance on visual quality along with the follow-up high-level vision tasks.