 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Preserved Distribution Matching Distillation for Fast Visual Synthesis
Feb 03, 2026Distribution matching distillation (DMD) aligns a multi-step generator with its few-step counterpart to enable high-quality generation under low inference cost. However, DMD tends to suffer from mode collapse, as its reverse-KL formulation inherently encourages mode-seeking behavior, for which existing remedies typically rely on perceptual or adversarial regularization, thereby incurring substantial computational overhead and training instability. In this work, we propose a role-separated distillation framework that explicitly disentangles the roles of distilled steps: the first step is dedicated to preserving sample diversity via a target-prediction (e.g., v-prediction) objective, while subsequent steps focus on quality refinement under the standard DMD loss, with gradients from the DMD objective blocked at the first step. We term this approach Diversity-Preserved DMD (DP-DMD), which, despite its simplicity -- no perceptual backbone, no discriminator, no auxiliary networks, and no additional ground-truth images -- preserves sample diversity while maintaining visual quality on par with state-of-the-art methods in extensive text-to-image experiments.
Beyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
Jan 12, 2026Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.
Visual Perturbation and Adaptive Hard Negative Contrastive Learning for Compositional Reasoning in Vision-Language Models
May 21, 2025Vision-Language Models (VLMs) are essential for multimodal tasks, especially compositional reasoning (CR) tasks, which require distinguishing fine-grained semantic differences between visual and textual embeddings. However, existing methods primarily fine-tune the model by generating text-based hard negative samples, neglecting the importance of image-based negative samples, which results in insufficient training of the visual encoder and ultimately impacts the overall performance of the model. Moreover, negative samples are typically treated uniformly, without considering their difficulty levels, and the alignment of positive samples is insufficient, which leads to challenges in aligning difficult sample pairs. To address these issues, we propose Adaptive Hard Negative Perturbation Learning (AHNPL). AHNPL translates text-based hard negatives into the visual domain to generate semantically disturbed image-based negatives for training the model, thereby enhancing its overall performance. AHNPL also introduces a contrastive learning approach using a multimodal hard negative loss to improve the model's discrimination of hard negatives within each modality and a dynamic margin loss that adjusts the contrastive margin according to sample difficulty to enhance the distinction of challenging sample pairs. Experiments on three public datasets demonstrate that our method effectively boosts VLMs' performance on complex CR tasks. The source code is available at https://github.com/nynu-BDAI/AHNPL.
InsViE-1M: Effective Instruction-based Video Editing with Elaborate Dataset Construction
Mar 26, 2025

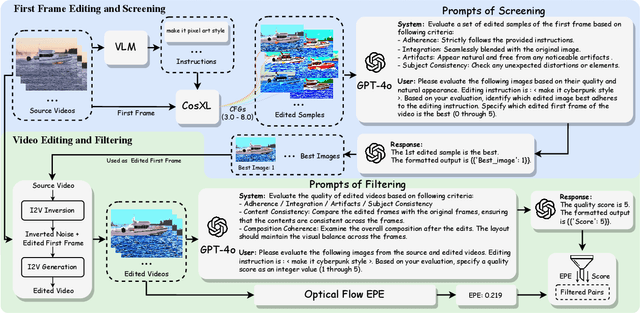

Instruction-based video editing allows effective and interactive editing of videos using only instructions without extra inputs such as masks or attributes. However, collecting high-quality training triplets (source video, edited video, instruction) is a challenging task. Existing datasets mostly consist of low-resolution, short duration, and limited amount of source videos with unsatisfactory editing quality, limiting the performance of trained editing models. In this work, we present a high-quality Instruction-based Video Editing dataset with 1M triplets, namely InsViE-1M. We first curate high-resolution and high-quality source videos and images, then design an effective editing-filtering pipeline to construct high-quality editing triplets for model training. For a source video, we generate multiple edited samples of its first frame with different intensities of classifier-free guidance, which are automatically filtered by GPT-4o with carefully crafted guidelines. The edited first frame is propagated to subsequent frames to produce the edited video, followed by another round of filtering for frame quality and motion evaluation. We also generate and filter a variety of video editing triplets from high-quality images. With the InsViE-1M dataset, we propose a multi-stage learning strategy to train our InsViE model, progressively enhancing its instruction following and editing ability. Extensive experiments demonstrate the advantages of our InsViE-1M dataset and the trained model over state-of-the-art works. Codes are available at InsViE.
Constrained Gaussian Wasserstein Optimal Transport with Commutative Covariance Matrices
Mar 05, 2025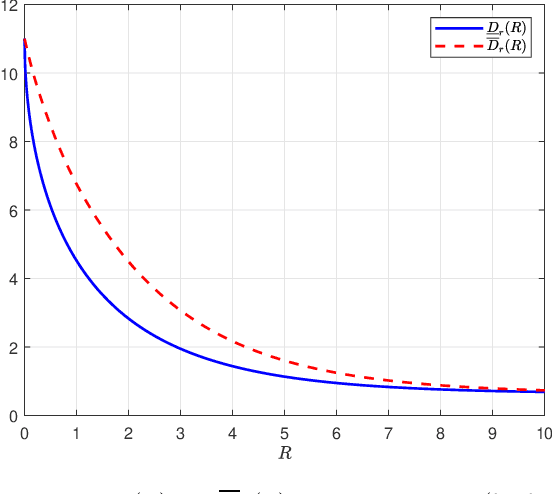
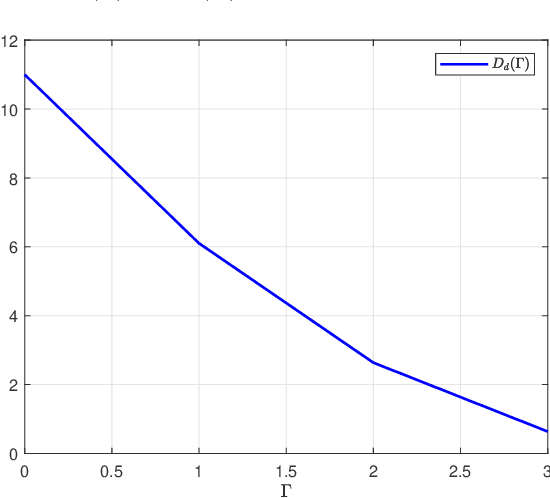
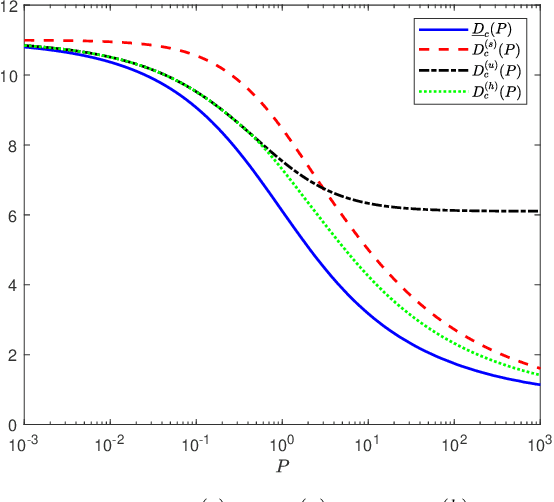
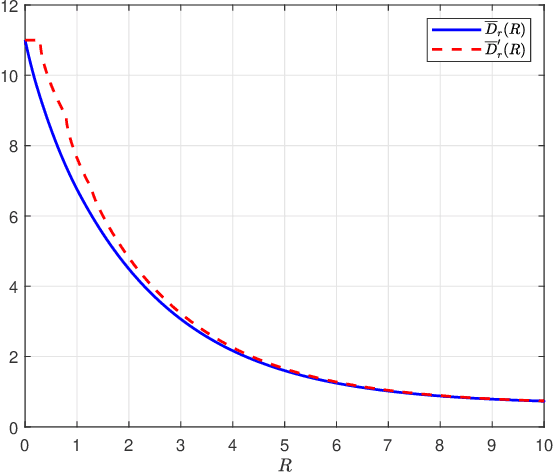
Optimal transport has found widespread applications in signal processing and machine learning. Among its many equivalent formulations, optimal transport seeks to reconstruct a random variable/vector with a prescribed distribution at the destination while minimizing the expected distortion relative to a given random variable/vector at the source. However, in practice, certain constraints may render the optimal transport plan infeasible. In this work, we consider three types of constraints: rate constraints, dimension constraints, and channel constraints, motivated by perception-aware lossy compression, generative principal component analysis, and deep joint source-channel coding, respectively. Special attenion is given to the setting termed Gaussian Wasserstein optimal transport, where both the source and reconstruction variables are multivariate Gaussian, and the end-to-end distortion is measured by the mean squared error. We derive explicit results for the minimum achievable mean squared error under the three aforementioned constraints when the covariance matrices of the source and reconstruction variables commute.
RORem: Training a Robust Object Remover with Human-in-the-Loop
Jan 01, 2025Despite the significant advancements, existing object removal methods struggle with incomplete removal, incorrect content synthesis and blurry synthesized regions, resulting in low success rates. Such issues are mainly caused by the lack of high-quality paired training data, as well as the self-supervised training paradigm adopted in these methods, which forces the model to in-paint the masked regions, leading to ambiguity between synthesizing the masked objects and restoring the background. To address these issues, we propose a semi-supervised learning strategy with human-in-the-loop to create high-quality paired training data, aiming to train a Robust Object Remover (RORem). We first collect 60K training pairs from open-source datasets to train an initial object removal model for generating removal samples, and then utilize human feedback to select a set of high-quality object removal pairs, with which we train a discriminator to automate the following training data generation process. By iterating this process for several rounds, we finally obtain a substantial object removal dataset with over 200K pairs. Fine-tuning the pre-trained stable diffusion model with this dataset, we obtain our RORem, which demonstrates state-of-the-art object removal performance in terms of both reliability and image quality. Particularly, RORem improves the object removal success rate over previous methods by more than 18\%. The dataset, source code and trained model are available at https://github.com/leeruibin/RORem.
Gradient Diffusion: A Perturbation-Resilient Gradient Leakage Attack
Jul 07, 2024Recent years have witnessed the vulnerability of Federated Learning (FL) against gradient leakage attacks, where the private training data can be recovered from the exchanged gradients, making gradient protection a critical issue for the FL training process. Existing solutions often resort to perturbation-based mechanisms, such as differential privacy, where each participating client injects a specific amount of noise into local gradients before aggregating to the server, and the global distribution variation finally conceals the gradient privacy. However, perturbation is not always the panacea for gradient protection since the robustness heavily relies on the injected noise. This intuition raises an interesting question: \textit{is it possible to deactivate existing protection mechanisms by removing the perturbation inside the gradients?} In this paper, we present the answer: \textit{yes} and propose the Perturbation-resilient Gradient Leakage Attack (PGLA), the first attempt to recover the perturbed gradients, without additional access to the original model structure or third-party data. Specifically, we leverage the inherent diffusion property of gradient perturbation protection and construct a novel diffusion-based denoising model to implement PGLA. Our insight is that capturing the disturbance level of perturbation during the diffusion reverse process can release the gradient denoising capability, which promotes the diffusion model to generate approximate gradients as the original clean version through adaptive sampling steps. Extensive experiments demonstrate that PGLA effectively recovers the protected gradients and exposes the FL training process to the threat of gradient leakage, achieving the best quality in gradient denoising and data recovery compared to existing models. We hope to arouse public attention on PGLA and its defense.
Source Prompt Disentangled Inversion for Boosting Image Editability with Diffusion Models
Mar 17, 2024



Text-driven diffusion models have significantly advanced the image editing performance by using text prompts as inputs. One crucial step in text-driven image editing is to invert the original image into a latent noise code conditioned on the source prompt. While previous methods have achieved promising results by refactoring the image synthesizing process, the inverted latent noise code is tightly coupled with the source prompt, limiting the image editability by target text prompts. To address this issue, we propose a novel method called Source Prompt Disentangled Inversion (SPDInv), which aims at reducing the impact of source prompt, thereby enhancing the text-driven image editing performance by employing diffusion models. To make the inverted noise code be independent of the given source prompt as much as possible, we indicate that the iterative inversion process should satisfy a fixed-point constraint. Consequently, we transform the inversion problem into a searching problem to find the fixed-point solution, and utilize the pre-trained diffusion models to facilitate the searching process. The experimental results show that our proposed SPDInv method can effectively mitigate the conflicts between the target editing prompt and the source prompt, leading to a significant decrease in editing artifacts. In addition to text-driven image editing, with SPDInv we can easily adapt customized image generation models to localized editing tasks and produce promising performance. The source code are available at https://github.com/leeruibin/SPDInv.
FreePIH: Training-Free Painterly Image Harmonization with Diffusion Model
Nov 25, 2023This paper provides an efficient training-free painterly image harmonization (PIH) method, dubbed FreePIH, that leverages only a pre-trained diffusion model to achieve state-of-the-art harmonization results. Unlike existing methods that require either training auxiliary networks or fine-tuning a large pre-trained backbone, or both, to harmonize a foreground object with a painterly-style background image, our FreePIH tames the denoising process as a plug-in module for foreground image style transfer. Specifically, we find that the very last few steps of the denoising (i.e., generation) process strongly correspond to the stylistic information of images, and based on this, we propose to augment the latent features of both the foreground and background images with Gaussians for a direct denoising-based harmonization. To guarantee the fidelity of the harmonized image, we make use of multi-scale features to enforce the consistency of the content and stability of the foreground objects in the latent space, and meanwhile, aligning both fore-/back-grounds with the same style. Moreover, to accommodate the generation with more structural and textural details, we further integrate text prompts to attend to the latent features, hence improving the generation quality. Quantitative and qualitative evaluations on COCO and LAION 5B datasets demonstrate that our method can surpass representative baselines by large margins.
Dissecting Arbitrary-scale Super-resolution Capability from Pre-trained Diffusion Generative Models
Jun 01, 2023



Diffusion-based Generative Models (DGMs) have achieved unparalleled performance in synthesizing high-quality visual content, opening up the opportunity to improve image super-resolution (SR) tasks. Recent solutions for these tasks often train architecture-specific DGMs from scratch, or require iterative fine-tuning and distillation on pre-trained DGMs, both of which take considerable time and hardware investments. More seriously, since the DGMs are established with a discrete pre-defined upsampling scale, they cannot well match the emerging requirements of arbitrary-scale super-resolution (ASSR), where a unified model adapts to arbitrary upsampling scales, instead of preparing a series of distinct models for each case. These limitations beg an intriguing question: can we identify the ASSR capability of existing pre-trained DGMs without the need for distillation or fine-tuning? In this paper, we take a step towards resolving this matter by proposing Diff-SR, a first ASSR attempt based solely on pre-trained DGMs, without additional training efforts. It is motivated by an exciting finding that a simple methodology, which first injects a specific amount of noise into the low-resolution images before invoking a DGM's backward diffusion process, outperforms current leading solutions. The key insight is determining a suitable amount of noise to inject, i.e., small amounts lead to poor low-level fidelity, while over-large amounts degrade the high-level signature. Through a finely-grained theoretical analysis, we propose the Perceptual Recoverable Field (PRF), a metric that achieves the optimal trade-off between these two factors. Extensive experiments verify the effectiveness, flexibility, and adaptability of Diff-SR, demonstrating superior performance to state-of-the-art solutions under diverse ASSR environments.