 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Jan 07, 2026Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
MiMu: Mitigating Multiple Shortcut Learning Behavior of Transformers
Apr 14, 2025Empirical Risk Minimization (ERM) models often rely on spurious correlations between features and labels during the learning process, leading to shortcut learning behavior that undermines robustness generalization performance. Current research mainly targets identifying or mitigating a single shortcut; however, in real-world scenarios, cues within the data are diverse and unknown. In empirical studies, we reveal that the models rely to varying extents on different shortcuts. Compared to weak shortcuts, models depend more heavily on strong shortcuts, resulting in their poor generalization ability. To address these challenges, we propose MiMu, a novel method integrated with Transformer-based ERMs designed to Mitigate Multiple shortcut learning behavior, which incorporates self-calibration strategy and self-improvement strategy. In the source model, we preliminarily propose the self-calibration strategy to prevent the model from relying on shortcuts and make overconfident predictions. Then, we further design self-improvement strategy in target model to reduce the reliance on multiple shortcuts. The random mask strategy involves randomly masking partial attention positions to diversify the focus of target model other than concentrating on a fixed region. Meanwhile, the adaptive attention alignment module facilitates the alignment of attention weights to the calibrated source model, without the need for post-hoc attention maps or supervision. Finally, extensive experiments conducted on Natural Language Processing (NLP) and Computer Vision (CV) demonstrate the effectiveness of MiMu in improving robustness generalization abilities.
InsViE-1M: Effective Instruction-based Video Editing with Elaborate Dataset Construction
Mar 26, 2025

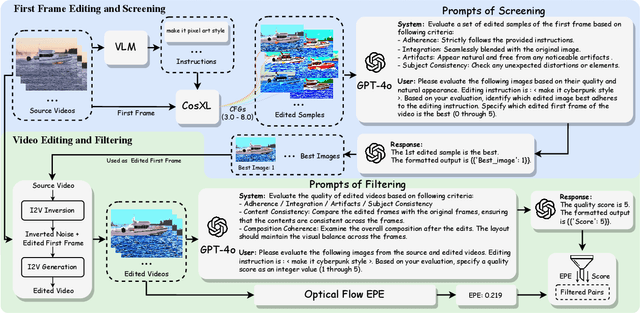

Instruction-based video editing allows effective and interactive editing of videos using only instructions without extra inputs such as masks or attributes. However, collecting high-quality training triplets (source video, edited video, instruction) is a challenging task. Existing datasets mostly consist of low-resolution, short duration, and limited amount of source videos with unsatisfactory editing quality, limiting the performance of trained editing models. In this work, we present a high-quality Instruction-based Video Editing dataset with 1M triplets, namely InsViE-1M. We first curate high-resolution and high-quality source videos and images, then design an effective editing-filtering pipeline to construct high-quality editing triplets for model training. For a source video, we generate multiple edited samples of its first frame with different intensities of classifier-free guidance, which are automatically filtered by GPT-4o with carefully crafted guidelines. The edited first frame is propagated to subsequent frames to produce the edited video, followed by another round of filtering for frame quality and motion evaluation. We also generate and filter a variety of video editing triplets from high-quality images. With the InsViE-1M dataset, we propose a multi-stage learning strategy to train our InsViE model, progressively enhancing its instruction following and editing ability. Extensive experiments demonstrate the advantages of our InsViE-1M dataset and the trained model over state-of-the-art works. Codes are available at InsViE.
Hierarchical Time-Aware Mixture of Experts for Multi-Modal Sequential Recommendation
Jan 24, 2025Multi-modal sequential recommendation (SR) leverages multi-modal data to learn more comprehensive item features and user preferences than traditional SR methods, which has become a critical topic in both academia and industry. Existing methods typically focus on enhancing multi-modal information utility through adaptive modality fusion to capture the evolving of user preference from user-item interaction sequences. However, most of them overlook the interference caused by redundant interest-irrelevant information contained in rich multi-modal data. Additionally, they primarily rely on implicit temporal information based solely on chronological ordering, neglecting explicit temporal signals that could more effectively represent dynamic user interest over time. To address these limitations, we propose a Hierarchical time-aware Mixture of experts for multi-modal Sequential Recommendation (HM4SR) with a two-level Mixture of Experts (MoE) and a multi-task learning strategy. Specifically, the first MoE, named Interactive MoE, extracts essential user interest-related information from the multi-modal data of each item. Then, the second MoE, termed Temporal MoE, captures user dynamic interests by introducing explicit temporal embeddings from timestamps in modality encoding. To further address data sparsity, we propose three auxiliary supervision tasks: sequence-level category prediction (CP) for item feature understanding, contrastive learning on ID (IDCL) to align sequence context with user interests, and placeholder contrastive learning (PCL) to integrate temporal information with modalities for dynamic interest modeling. Extensive experiments on four public datasets verify the effectiveness of HM4SR compared to several state-of-the-art approaches.
Generalized and Efficient 2D Gaussian Splatting for Arbitrary-scale Super-Resolution
Jan 14, 2025



Equipped with the continuous representation capability of Multi-Layer Perceptron (MLP), Implicit Neural Representation (INR) has been successfully employed for Arbitrary-scale Super-Resolution (ASR). However, the limited receptive field of the linear layers in MLP restricts the representation capability of INR, while it is computationally expensive to query the MLP numerous times to render each pixel. Recently, Gaussian Splatting (GS) has shown its advantages over INR in both visual quality and rendering speed in 3D tasks, which motivates us to explore whether GS can be employed for the ASR task. However, directly applying GS to ASR is exceptionally challenging because the original GS is an optimization-based method through overfitting each single scene, while in ASR we aim to learn a single model that can generalize to different images and scaling factors. We overcome these challenges by developing two novel techniques. Firstly, to generalize GS for ASR, we elaborately design an architecture to predict the corresponding image-conditioned Gaussians of the input low-resolution image in a feed-forward manner. Secondly, we implement an efficient differentiable 2D GPU/CUDA-based scale-aware rasterization to render super-resolved images by sampling discrete RGB values from the predicted contiguous Gaussians. Via end-to-end training, our optimized network, namely GSASR, can perform ASR for any image and unseen scaling factors. Extensive experiments validate the effectiveness of our proposed method. The project page can be found at \url{https://mt-cly.github.io/GSASR.github.io/}.
SimCMF: A Simple Cross-modal Fine-tuning Strategy from Vision Foundation Models to Any Imaging Modality
Nov 27, 2024



Foundation models like ChatGPT and Sora that are trained on a huge scale of data have made a revolutionary social impact. However, it is extremely challenging for sensors in many different fields to collect similar scales of natural images to train strong foundation models. To this end, this work presents a simple and effective framework, SimCMF, to study an important problem: cross-modal fine-tuning from vision foundation models trained on natural RGB images to other imaging modalities of different physical properties (e.g., polarization). In SimCMF, we conduct a thorough analysis of different basic components from the most naive design and ultimately propose a novel cross-modal alignment module to address the modality misalignment problem. We apply SimCMF to a representative vision foundation model Segment Anything Model (SAM) to support any evaluated new imaging modality. Given the absence of relevant benchmarks, we construct a benchmark for performance evaluation. Our experiments confirm the intriguing potential of transferring vision foundation models in enhancing other sensors' performance. SimCMF can improve the segmentation performance (mIoU) from 22.15% to 53.88% on average for evaluated modalities and consistently outperforms other baselines. The code is available at https://github.com/mt-cly/SimCMF
TokenSelect: Efficient Long-Context Inference and Length Extrapolation for LLMs via Dynamic Token-Level KV Cache Selection
Nov 05, 2024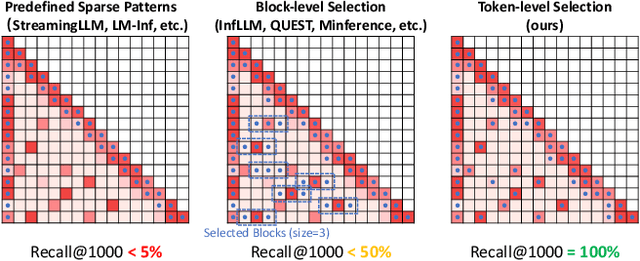
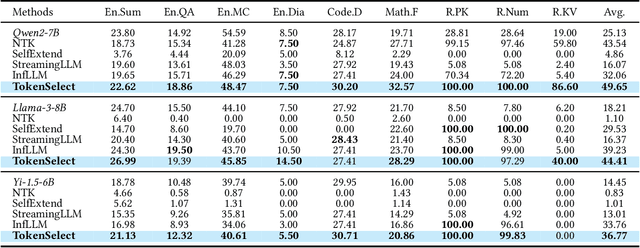
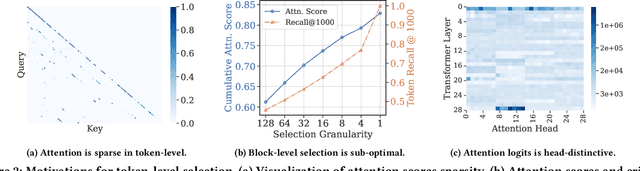
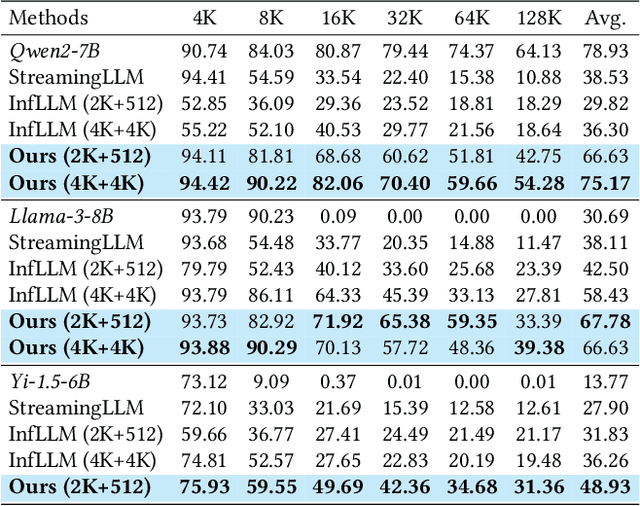
With the development of large language models (LLMs), the ability to handle longer contexts has become a key capability for Web applications such as cross-document understanding and LLM-powered search systems. However, this progress faces two major challenges: performance degradation due to sequence lengths out-of-distribution, and excessively long inference times caused by the quadratic computational complexity of attention. These issues hinder the application of LLMs in long-context scenarios. In this paper, we propose Dynamic Token-Level KV Cache Selection (TokenSelect), a model-agnostic, training-free method for efficient and accurate long-context inference. TokenSelect builds upon the observation of non-contiguous attention sparsity, using Query-Key dot products to measure per-head KV Cache criticality at token-level. By per-head soft voting mechanism, TokenSelect selectively involves a small number of critical KV cache tokens in the attention calculation without sacrificing accuracy. To further accelerate TokenSelect, we designed the Selection Cache based on observations of consecutive Query similarity and implemented efficient dot product kernel, significantly reducing the overhead of token selection. A comprehensive evaluation of TokenSelect demonstrates up to 23.84x speedup in attention computation and up to 2.28x acceleration in end-to-end latency, while providing superior performance compared to state-of-the-art long-context inference methods.
Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs
Oct 31, 2024



Large Language Models (LLMs) have shown remarkable reasoning capabilities on complex tasks, but they still suffer from out-of-date knowledge, hallucinations, and opaque decision-making. In contrast, Knowledge Graphs (KGs) can provide explicit and editable knowledge for LLMs to alleviate these issues. Existing paradigm of KG-augmented LLM manually predefines the breadth of exploration space and requires flawless navigation in KGs. However, this paradigm cannot adaptively explore reasoning paths in KGs based on the question semantics and self-correct erroneous reasoning paths, resulting in a bottleneck in efficiency and effect. To address these limitations, we propose a novel self-correcting adaptive planning paradigm for KG-augmented LLM named Plan-on-Graph (PoG), which first decomposes the question into several sub-objectives and then repeats the process of adaptively exploring reasoning paths, updating memory, and reflecting on the need to self-correct erroneous reasoning paths until arriving at the answer. Specifically, three important mechanisms of Guidance, Memory, and Reflection are designed to work together, to guarantee the adaptive breadth of self-correcting planning for graph reasoning. Finally, extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of PoG.
Structure-Enhanced Protein Instruction Tuning: Towards General-Purpose Protein Understanding
Oct 04, 2024Proteins, as essential biomolecules, play a central role in biological processes, including metabolic reactions and DNA replication. Accurate prediction of their properties and functions is crucial in biological applications. Recent development of protein language models (pLMs) with supervised fine tuning provides a promising solution to this problem. However, the fine-tuned model is tailored for particular downstream prediction task, and achieving general-purpose protein understanding remains a challenge. In this paper, we introduce Structure-Enhanced Protein Instruction Tuning (SEPIT) framework to bridge this gap. Our approach integrates a noval structure-aware module into pLMs to inform them with structural knowledge, and then connects these enhanced pLMs to large language models (LLMs) to generate understanding of proteins. In this framework, we propose a novel two-stage instruction tuning pipeline that first establishes a basic understanding of proteins through caption-based instructions and then refines this understanding using a mixture of experts (MoEs) to learn more complex properties and functional information with the same amount of activated parameters. Moreover, we construct the largest and most comprehensive protein instruction dataset to date, which allows us to train and evaluate the general-purpose protein understanding model. Extensive experimental results on open-ended generation and closed-set answer tasks demonstrate the superior performance of SEPIT over both closed-source general LLMs and open-source LLMs trained with protein knowledge.
SimMAT: Exploring Transferability from Vision Foundation Models to Any Image Modality
Sep 12, 2024



Foundation models like ChatGPT and Sora that are trained on a huge scale of data have made a revolutionary social impact. However, it is extremely challenging for sensors in many different fields to collect similar scales of natural images to train strong foundation models. To this end, this work presents a simple and effective framework SimMAT to study an open problem: the transferability from vision foundation models trained on natural RGB images to other image modalities of different physical properties (e.g., polarization). SimMAT consists of a modality-agnostic transfer layer (MAT) and a pretrained foundation model. We apply SimMAT to a representative vision foundation model Segment Anything Model (SAM) to support any evaluated new image modality. Given the absence of relevant benchmarks, we construct a new benchmark to evaluate the transfer learning performance. Our experiments confirm the intriguing potential of transferring vision foundation models in enhancing other sensors' performance. Specifically, SimMAT can improve the segmentation performance (mIoU) from 22.15% to 53.88% on average for evaluated modalities and consistently outperforms other baselines. We hope that SimMAT can raise awareness of cross-modal transfer learning and benefit various fields for better results with vision foundation models.