 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLG: Comprehensive 3D Room Construction via Hierarchical Layout Generation
Aug 25, 2025Realistic 3D indoor scene generation is crucial for virtual reality, interior design, embodied intelligence, and scene understanding. While existing methods have made progress in coarse-scale furniture arrangement, they struggle to capture fine-grained object placements, limiting the realism and utility of generated environments. This gap hinders immersive virtual experiences and detailed scene comprehension for embodied AI applications. To address these issues, we propose Hierarchical Layout Generation (HLG), a novel method for fine-grained 3D scene generation. HLG is the first to adopt a coarse-to-fine hierarchical approach, refining scene layouts from large-scale furniture placement to intricate object arrangements. Specifically, our fine-grained layout alignment module constructs a hierarchical layout through vertical and horizontal decoupling, effectively decomposing complex 3D indoor scenes into multiple levels of granularity. Additionally, our trainable layout optimization network addresses placement issues, such as incorrect positioning, orientation errors, and object intersections, ensuring structurally coherent and physically plausible scene generation. We demonstrate the effectiveness of our approach through extensive experiments, showing superior performance in generating realistic indoor scenes compared to existing methods. This work advances the field of scene generation and opens new possibilities for applications requiring detailed 3D environments. We will release our code upon publication to encourage future research.
Enhancing Sound Source Localization via False Negative Elimination
Aug 29, 2024



Sound source localization aims to localize objects emitting the sound in visual scenes. Recent works obtaining impressive results typically rely on contrastive learning. However, the common practice of randomly sampling negatives in prior arts can lead to the false negative issue, where the sounds semantically similar to visual instance are sampled as negatives and incorrectly pushed away from the visual anchor/query. As a result, this misalignment of audio and visual features could yield inferior performance. To address this issue, we propose a novel audio-visual learning framework which is instantiated with two individual learning schemes: self-supervised predictive learning (SSPL) and semantic-aware contrastive learning (SACL). SSPL explores image-audio positive pairs alone to discover semantically coherent similarities between audio and visual features, while a predictive coding module for feature alignment is introduced to facilitate the positive-only learning. In this regard SSPL acts as a negative-free method to eliminate false negatives. By contrast, SACL is designed to compact visual features and remove false negatives, providing reliable visual anchor and audio negatives for contrast. Different from SSPL, SACL releases the potential of audio-visual contrastive learning, offering an effective alternative to achieve the same goal. Comprehensive experiments demonstrate the superiority of our approach over the state-of-the-arts. Furthermore, we highlight the versatility of the learned representation by extending the approach to audio-visual event classification and object detection tasks. Code and models are available at: https://github.com/zjsong/SACL.
General Geometry-aware Weakly Supervised 3D Object Detection
Jul 18, 2024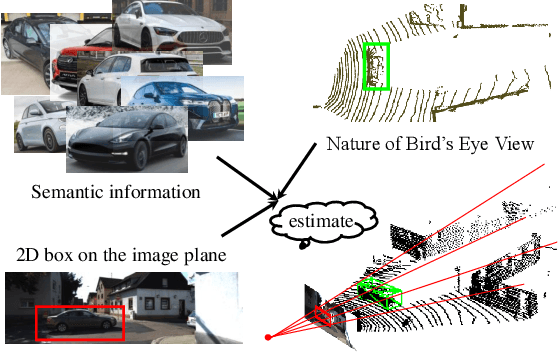
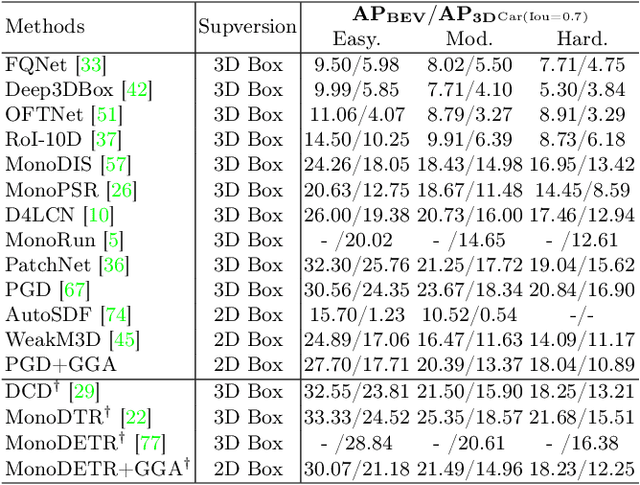

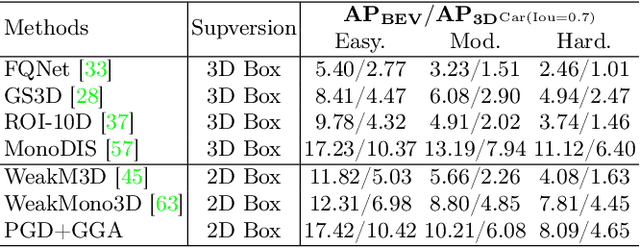
3D object detection is an indispensable component for scene understanding. However, the annotation of large-scale 3D datasets requires significant human effort. To tackle this problem, many methods adopt weakly supervised 3D object detection that estimates 3D boxes by leveraging 2D boxes and scene/class-specific priors. However, these approaches generally depend on sophisticated manual priors, which is hard to generalize to novel categories and scenes. In this paper, we are motivated to propose a general approach, which can be easily adapted to new scenes and/or classes. A unified framework is developed for learning 3D object detectors from RGB images and associated 2D boxes. In specific, we propose three general components: prior injection module to obtain general object geometric priors from LLM model, 2D space projection constraint to minimize the discrepancy between the boundaries of projected 3D boxes and their corresponding 2D boxes on the image plane, and 3D space geometry constraint to build a Point-to-Box alignment loss to further refine the pose of estimated 3D boxes. Experiments on KITTI and SUN-RGBD datasets demonstrate that our method yields surprisingly high-quality 3D bounding boxes with only 2D annotation. The source code is available at https://github.com/gwenzhang/GGA.
Continual Forgetting for Pre-trained Vision Models
Mar 18, 2024



For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on \url{https://github.com/bjzhb666/GS-LoRA}.
Segment Anything in 3D Gaussians
Feb 01, 20243D Gaussian Splatting has emerged as an alternative 3D representation of Neural Radiance Fields (NeRFs), benefiting from its high-quality rendering results and real-time rendering speed. Considering the 3D Gaussian representation remains unparsed, it is necessary first to execute object segmentation within this domain. Subsequently, scene editing and collision detection can be performed, proving vital to a multitude of applications, such as virtual reality (VR), augmented reality (AR), game/movie production, etc. In this paper, we propose a novel approach to achieve object segmentation in 3D Gaussian via an interactive procedure without any training process and learned parameters. We refer to the proposed method as SA-GS, for Segment Anything in 3D Gaussians. Given a set of clicked points in a single input view, SA-GS can generalize SAM to achieve 3D consistent segmentation via the proposed multi-view mask generation and view-wise label assignment methods. We also propose a cross-view label-voting approach to assign labels from different views. In addition, in order to address the boundary roughness issue of segmented objects resulting from the non-negligible spatial sizes of 3D Gaussian located at the boundary, SA-GS incorporates the simple but effective Gaussian Decomposition scheme. Extensive experiments demonstrate that SA-GS achieves high-quality 3D segmentation results, which can also be easily applied for scene editing and collision detection tasks. Codes will be released soon.
Bootstrap Masked Visual Modeling via Hard Patches Mining
Dec 21, 2023Masked visual modeling has attracted much attention due to its promising potential in learning generalizable representations. Typical approaches urge models to predict specific contents of masked tokens, which can be intuitively considered as teaching a student (the model) to solve given problems (predicting masked contents). Under such settings, the performance is highly correlated with mask strategies (the difficulty of provided problems). We argue that it is equally important for the model to stand in the shoes of a teacher to produce challenging problems by itself. Intuitively, patches with high values of reconstruction loss can be regarded as hard samples, and masking those hard patches naturally becomes a demanding reconstruction task. To empower the model as a teacher, we propose Hard Patches Mining (HPM), predicting patch-wise losses and subsequently determining where to mask. Technically, we introduce an auxiliary loss predictor, which is trained with a relative objective to prevent overfitting to exact loss values. Also, to gradually guide the training procedure, we propose an easy-to-hard mask strategy. Empirically, HPM brings significant improvements under both image and video benchmarks. Interestingly, solely incorporating the extra loss prediction objective leads to better representations, verifying the efficacy of determining where is hard to reconstruct. The code is available at https://github.com/Haochen-Wang409/HPM.
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
Sep 22, 2023As it is empirically observed that Vision Transformers (ViTs) are quite insensitive to the order of input tokens, the need for an appropriate self-supervised pretext task that enhances the location awareness of ViTs is becoming evident. To address this, we present DropPos, a novel pretext task designed to reconstruct Dropped Positions. The formulation of DropPos is simple: we first drop a large random subset of positional embeddings and then the model classifies the actual position for each non-overlapping patch among all possible positions solely based on their visual appearance. To avoid trivial solutions, we increase the difficulty of this task by keeping only a subset of patches visible. Additionally, considering there may be different patches with similar visual appearances, we propose position smoothing and attentive reconstruction strategies to relax this classification problem, since it is not necessary to reconstruct their exact positions in these cases. Empirical evaluations of DropPos show strong capabilities. DropPos outperforms supervised pre-training and achieves competitive results compared with state-of-the-art self-supervised alternatives on a wide range of downstream benchmarks. This suggests that explicitly encouraging spatial reasoning abilities, as DropPos does, indeed contributes to the improved location awareness of ViTs. The code is publicly available at https://github.com/Haochen-Wang409/DropPos.
DDG-Net: Discriminability-Driven Graph Network for Weakly-supervised Temporal Action Localization
Aug 07, 2023



Weakly-supervised temporal action localization (WTAL) is a practical yet challenging task. Due to large-scale datasets, most existing methods use a network pretrained in other datasets to extract features, which are not suitable enough for WTAL. To address this problem, researchers design several modules for feature enhancement, which improve the performance of the localization module, especially modeling the temporal relationship between snippets. However, all of them neglect the adverse effects of ambiguous information, which would reduce the discriminability of others. Considering this phenomenon, we propose Discriminability-Driven Graph Network (DDG-Net), which explicitly models ambiguous snippets and discriminative snippets with well-designed connections, preventing the transmission of ambiguous information and enhancing the discriminability of snippet-level representations. Additionally, we propose feature consistency loss to prevent the assimilation of features and drive the graph convolution network to generate more discriminative representations. Extensive experiments on THUMOS14 and ActivityNet1.2 benchmarks demonstrate the effectiveness of DDG-Net, establishing new state-of-the-art results on both datasets. Source code is available at \url{https://github.com/XiaojunTang22/ICCV2023-DDGNet}.
Using Unreliable Pseudo-Labels for Label-Efficient Semantic Segmentation
Jun 04, 2023The crux of label-efficient semantic segmentation is to produce high-quality pseudo-labels to leverage a large amount of unlabeled or weakly labeled data. A common practice is to select the highly confident predictions as the pseudo-ground-truths for each pixel, but it leads to a problem that most pixels may be left unused due to their unreliability. However, we argue that every pixel matters to the model training, even those unreliable and ambiguous pixels. Intuitively, an unreliable prediction may get confused among the top classes, however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative key to those most unlikely categories. Therefore, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative keys, and manage to train the model with all candidate pixels. Considering the training evolution, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.
Hard Patches Mining for Masked Image Modeling
Apr 12, 2023



Masked image modeling (MIM) has attracted much research attention due to its promising potential for learning scalable visual representations. In typical approaches, models usually focus on predicting specific contents of masked patches, and their performances are highly related to pre-defined mask strategies. Intuitively, this procedure can be considered as training a student (the model) on solving given problems (predict masked patches). However, we argue that the model should not only focus on solving given problems, but also stand in the shoes of a teacher to produce a more challenging problem by itself. To this end, we propose Hard Patches Mining (HPM), a brand-new framework for MIM pre-training. We observe that the reconstruction loss can naturally be the metric of the difficulty of the pre-training task. Therefore, we introduce an auxiliary loss predictor, predicting patch-wise losses first and deciding where to mask next. It adopts a relative relationship learning strategy to prevent overfitting to exact reconstruction loss values. Experiments under various settings demonstrate the effectiveness of HPM in constructing masked images. Furthermore, we empirically find that solely introducing the loss prediction objective leads to powerful representations, verifying the efficacy of the ability to be aware of where is hard to reconstruct.