 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
OOD-HOI: Text-Driven 3D Whole-Body Human-Object Interactions Generation Beyond Training Domains
Nov 27, 2024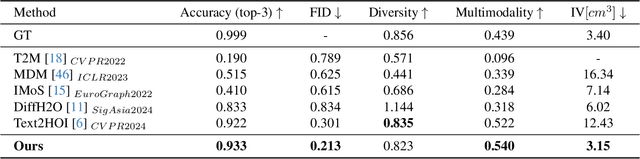
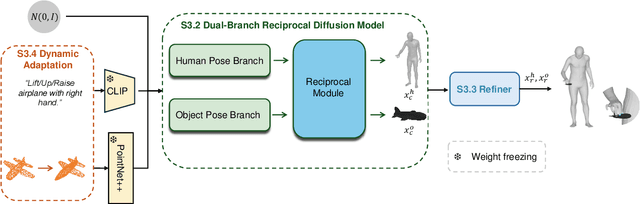
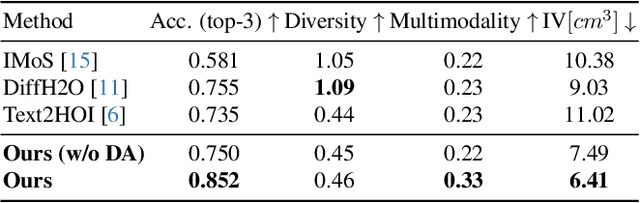
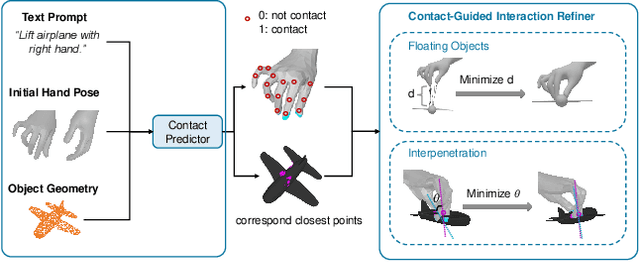
Generating realistic 3D human-object interactions (HOIs) from text descriptions is a active research topic with potential applications in virtual and augmented reality, robotics, and animation. However, creating high-quality 3D HOIs remains challenging due to the lack of large-scale interaction data and the difficulty of ensuring physical plausibility, especially in out-of-domain (OOD) scenarios. Current methods tend to focus either on the body or the hands, which limits their ability to produce cohesive and realistic interactions. In this paper, we propose OOD-HOI, a text-driven framework for generating whole-body human-object interactions that generalize well to new objects and actions. Our approach integrates a dual-branch reciprocal diffusion model to synthesize initial interaction poses, a contact-guided interaction refiner to improve physical accuracy based on predicted contact areas, and a dynamic adaptation mechanism which includes semantic adjustment and geometry deformation to improve robustness. Experimental results demonstrate that our OOD-HOI could generate more realistic and physically plausible 3D interaction pose in OOD scenarios compared to existing methods.
CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes
Nov 01, 2024



Recently, 3D Gaussian Splatting (3DGS) has revolutionized radiance field reconstruction, manifesting efficient and high-fidelity novel view synthesis. However, accurately representing surfaces, especially in large and complex scenarios, remains a significant challenge due to the unstructured nature of 3DGS. In this paper, we present CityGaussianV2, a novel approach for large-scale scene reconstruction that addresses critical challenges related to geometric accuracy and efficiency. Building on the favorable generalization capabilities of 2D Gaussian Splatting (2DGS), we address its convergence and scalability issues. Specifically, we implement a decomposed-gradient-based densification and depth regression technique to eliminate blurry artifacts and accelerate convergence. To scale up, we introduce an elongation filter that mitigates Gaussian count explosion caused by 2DGS degeneration. Furthermore, we optimize the CityGaussian pipeline for parallel training, achieving up to 10$\times$ compression, at least 25% savings in training time, and a 50% decrease in memory usage. We also established standard geometry benchmarks under large-scale scenes. Experimental results demonstrate that our method strikes a promising balance between visual quality, geometric accuracy, as well as storage and training costs. The project page is available at https://dekuliutesla.github.io/CityGaussianV2/.
CityX: Controllable Procedural Content Generation for Unbounded 3D Cities
Jul 29, 2024
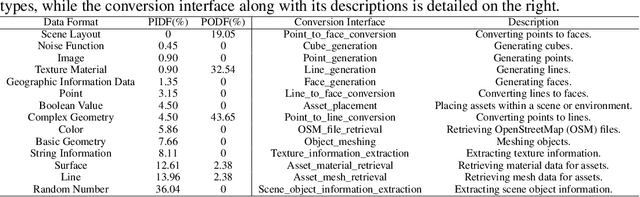
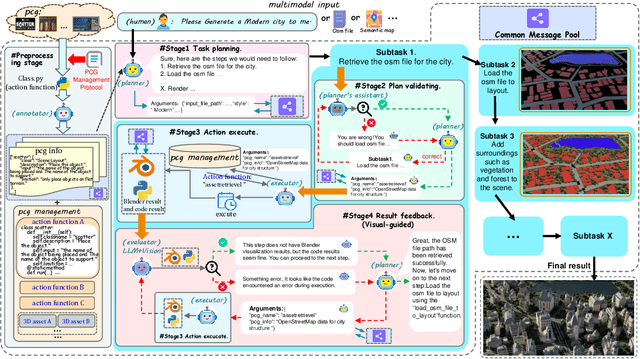
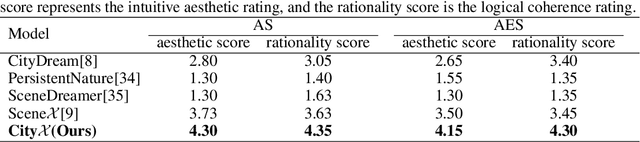
Generating a realistic, large-scale 3D virtual city remains a complex challenge due to the involvement of numerous 3D assets, various city styles, and strict layout constraints. Existing approaches provide promising attempts at procedural content generation to create large-scale scenes using Blender agents. However, they face crucial issues such as difficulties in scaling up generation capability and achieving fine-grained control at the semantic layout level. To address these problems, we propose a novel multi-modal controllable procedural content generation method, named CityX, which enhances realistic, unbounded 3D city generation guided by multiple layout conditions, including OSM, semantic maps, and satellite images. Specifically, the proposed method contains a general protocol for integrating various PCG plugins and a multi-agent framework for transforming instructions into executable Blender actions. Through this effective framework, CityX shows the potential to build an innovative ecosystem for 3D scene generation by bridging the gap between the quality of generated assets and industrial requirements. Extensive experiments have demonstrated the effectiveness of our method in creating high-quality, diverse, and unbounded cities guided by multi-modal conditions. Our project page: https://cityx-lab.github.io.
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
May 09, 2024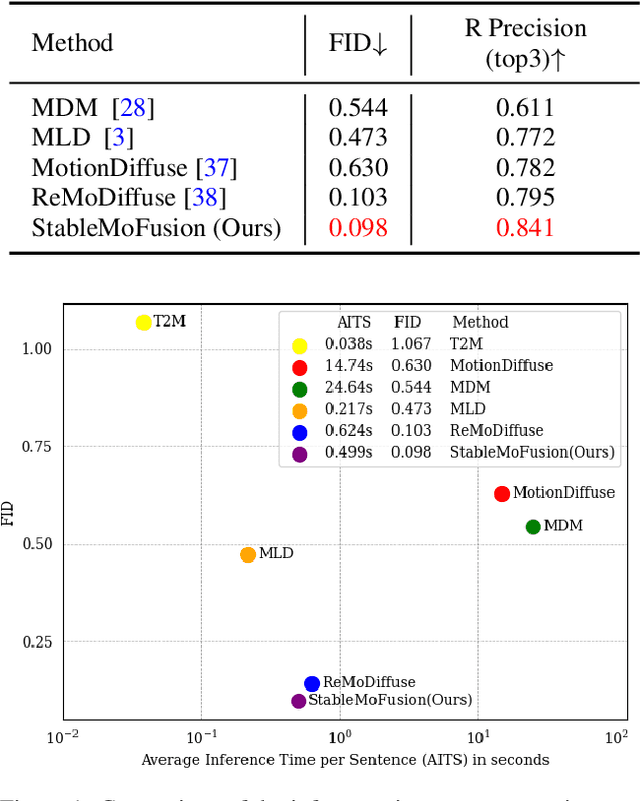
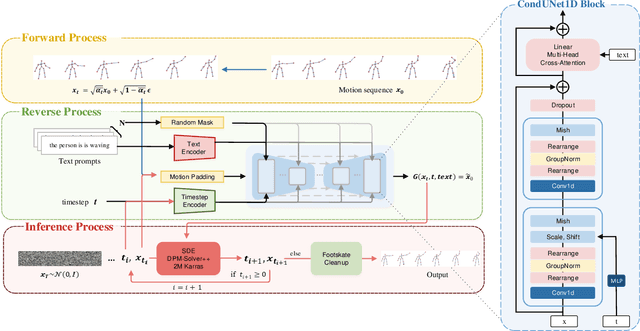
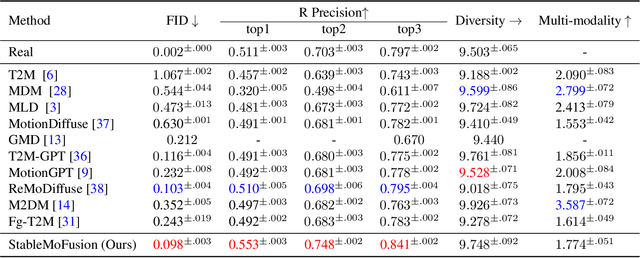
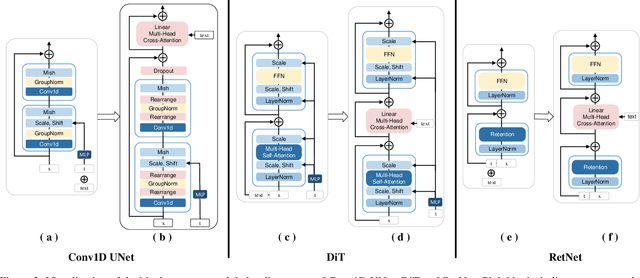
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
MaterialSeg3D: Segmenting Dense Materials from 2D Priors for 3D Assets
Apr 24, 2024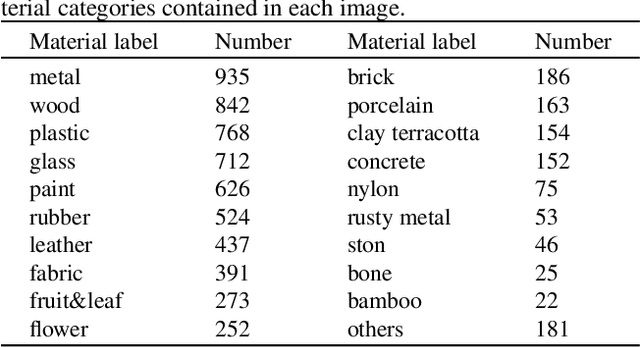
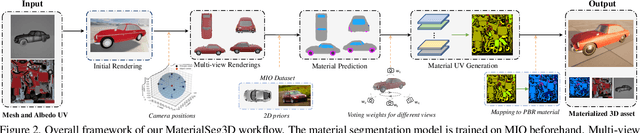
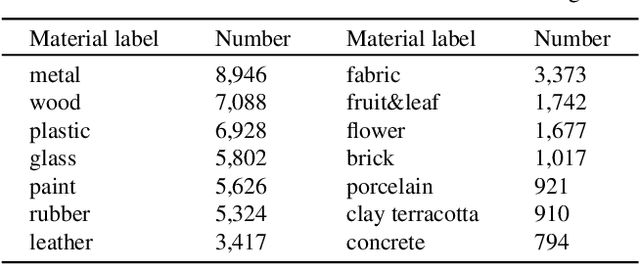

Driven by powerful image diffusion models, recent research has achieved the automatic creation of 3D objects from textual or visual guidance. By performing score distillation sampling (SDS) iteratively across different views, these methods succeed in lifting 2D generative prior to the 3D space. However, such a 2D generative image prior bakes the effect of illumination and shadow into the texture. As a result, material maps optimized by SDS inevitably involve spurious correlated components. The absence of precise material definition makes it infeasible to relight the generated assets reasonably in novel scenes, which limits their application in downstream scenarios. In contrast, humans can effortlessly circumvent this ambiguity by deducing the material of the object from its appearance and semantics. Motivated by this insight, we propose MaterialSeg3D, a 3D asset material generation framework to infer underlying material from the 2D semantic prior. Based on such a prior model, we devise a mechanism to parse material in 3D space. We maintain a UV stack, each map of which is unprojected from a specific viewpoint. After traversing all viewpoints, we fuse the stack through a weighted voting scheme and then employ region unification to ensure the coherence of the object parts. To fuel the learning of semantics prior, we collect a material dataset, named Materialized Individual Objects (MIO), which features abundant images, diverse categories, and accurate annotations. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method.
CityGaussian: Real-time High-quality Large-Scale Scene Rendering with Gaussians
Apr 07, 2024



The advancement of real-time 3D scene reconstruction and novel view synthesis has been significantly propelled by 3D Gaussian Splatting (3DGS). However, effectively training large-scale 3DGS and rendering it in real-time across various scales remains challenging. This paper introduces CityGaussian (CityGS), which employs a novel divide-and-conquer training approach and Level-of-Detail (LoD) strategy for efficient large-scale 3DGS training and rendering. Specifically, the global scene prior and adaptive training data selection enables efficient training and seamless fusion. Based on fused Gaussian primitives, we generate different detail levels through compression, and realize fast rendering across various scales through the proposed block-wise detail levels selection and aggregation strategy. Extensive experimental results on large-scale scenes demonstrate that our approach attains state-of-theart rendering quality, enabling consistent real-time rendering of largescale scenes across vastly different scales. Our project page is available at https://dekuliutesla.github.io/citygs/.
SceneX:Procedural Controllable Large-scale Scene Generation via Large-language Models
Mar 23, 2024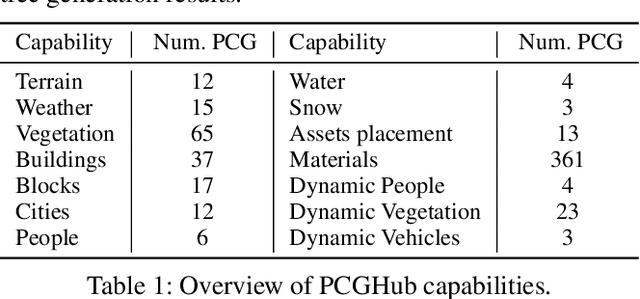

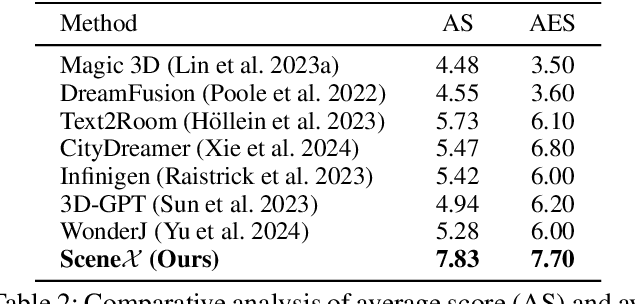

Due to its great application potential, large-scale scene generation has drawn extensive attention in academia and industry. Recent research employs powerful generative models to create desired scenes and achieves promising results. However, most of these methods represent the scene using 3D primitives (e.g. point cloud or radiance field) incompatible with the industrial pipeline, which leads to a substantial gap between academic research and industrial deployment. Procedural Controllable Generation (PCG) is an efficient technique for creating scalable and high-quality assets, but it is unfriendly for ordinary users as it demands profound domain expertise. To address these issues, we resort to using the large language model (LLM) to drive the procedural modeling. In this paper, we introduce a large-scale scene generation framework, SceneX, which can automatically produce high-quality procedural models according to designers' textual descriptions.Specifically, the proposed method comprises two components, PCGBench and PCGPlanner. The former encompasses an extensive collection of accessible procedural assets and thousands of hand-craft API documents. The latter aims to generate executable actions for Blender to produce controllable and precise 3D assets guided by the user's instructions. Our SceneX can generate a city spanning 2.5 km times 2.5 km with delicate layout and geometric structures, drastically reducing the time cost from several weeks for professional PCG engineers to just a few hours for an ordinary user. Extensive experiments demonstrated the capability of our method in controllable large-scale scene generation and editing, including asset placement and season translation.
FurniScene: A Large-scale 3D Room Dataset with Intricate Furnishing Scenes
Jan 07, 2024Indoor scene generation has attracted significant attention recently as it is crucial for applications of gaming, virtual reality, and interior design. Current indoor scene generation methods can produce reasonable room layouts but often lack diversity and realism. This is primarily due to the limited coverage of existing datasets, including only large furniture without tiny furnishings in daily life. To address these challenges, we propose FurniScene, a large-scale 3D room dataset with intricate furnishing scenes from interior design professionals. Specifically, the FurniScene consists of 11,698 rooms and 39,691 unique furniture CAD models with 89 different types, covering things from large beds to small teacups on the coffee table. To better suit fine-grained indoor scene layout generation, we introduce a novel Two-Stage Diffusion Scene Model (TSDSM) and conduct an evaluation benchmark for various indoor scene generation based on FurniScene. Quantitative and qualitative evaluations demonstrate the capability of our method to generate highly realistic indoor scenes. Our dataset and code will be publicly available soon.
Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions
Dec 05, 2023



Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, it remains challenging to generate fine-grained or stylized motions due to the lack of datasets annotated with detailed textual descriptions. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for human motion generation. Specifically, we first parse previous vague textual annotation into fine-grained description of different body parts by leveraging a large language model (GPT-3.5). We then use these fine-grained descriptions to guide a transformer-based diffusion model. FG-MDM can generate fine-grained and stylized motions even outside of the distribution of the training data. Our experimental results demonstrate the superiority of FG-MDM over previous methods, especially the strong generalization capability. We will release our fine-grained textual annotations for HumanML3D and KIT.