 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOD-HOI: Text-Driven 3D Whole-Body Human-Object Interactions Generation Beyond Training Domains
Paper and Code
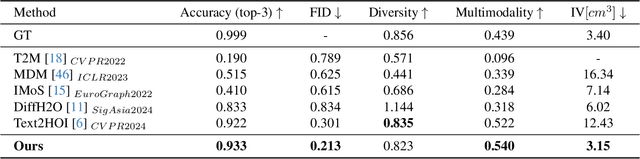
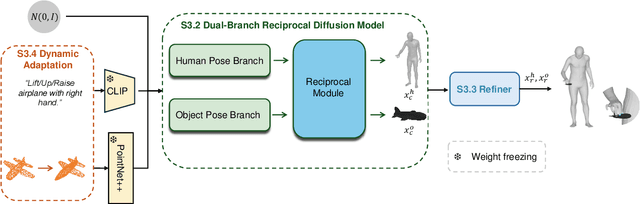
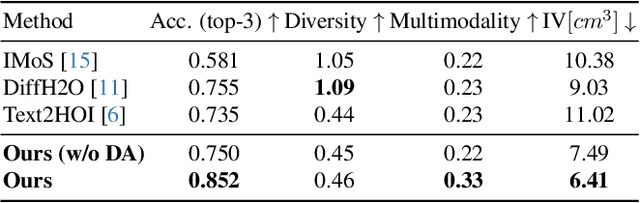
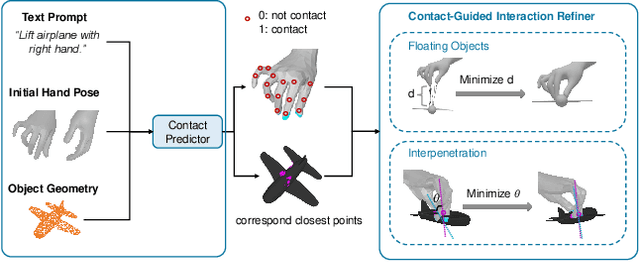
Generating realistic 3D human-object interactions (HOIs) from text descriptions is a active research topic with potential applications in virtual and augmented reality, robotics, and animation. However, creating high-quality 3D HOIs remains challenging due to the lack of large-scale interaction data and the difficulty of ensuring physical plausibility, especially in out-of-domain (OOD) scenarios. Current methods tend to focus either on the body or the hands, which limits their ability to produce cohesive and realistic interactions. In this paper, we propose OOD-HOI, a text-driven framework for generating whole-body human-object interactions that generalize well to new objects and actions. Our approach integrates a dual-branch reciprocal diffusion model to synthesize initial interaction poses, a contact-guided interaction refiner to improve physical accuracy based on predicted contact areas, and a dynamic adaptation mechanism which includes semantic adjustment and geometry deformation to improve robustness. Experimental results demonstrate that our OOD-HOI could generate more realistic and physically plausible 3D interaction pose in OOD scenarios compared to existing methods.