 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Jan 01, 2026In this paper, we propose NeoVerse, a versatile 4D world model that is capable of 4D reconstruction, novel-trajectory video generation, and rich downstream applications. We first identify a common limitation of scalability in current 4D world modeling methods, caused either by expensive and specialized multi-view 4D data or by cumbersome training pre-processing. In contrast, our NeoVerse is built upon a core philosophy that makes the full pipeline scalable to diverse in-the-wild monocular videos. Specifically, NeoVerse features pose-free feed-forward 4D reconstruction, online monocular degradation pattern simulation, and other well-aligned techniques. These designs empower NeoVerse with versatility and generalization to various domains. Meanwhile, NeoVerse achieves state-of-the-art performance in standard reconstruction and generation benchmarks. Our project page is available at https://neoverse-4d.github.io
TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
EmoDiffusion: Enhancing Emotional 3D Facial Animation with Latent Diffusion Models
Mar 14, 2025Speech-driven 3D facial animation seeks to produce lifelike facial expressions that are synchronized with the speech content and its emotional nuances, finding applications in various multimedia fields. However, previous methods often overlook emotional facial expressions or fail to disentangle them effectively from the speech content. To address these challenges, we present EmoDiffusion, a novel approach that disentangles different emotions in speech to generate rich 3D emotional facial expressions. Specifically, our method employs two Variational Autoencoders (VAEs) to separately generate the upper face region and mouth region, thereby learning a more refined representation of the facial sequence. Unlike traditional methods that use diffusion models to connect facial expression sequences with audio inputs, we perform the diffusion process in the latent space. Furthermore, we introduce an Emotion Adapter to evaluate upper face movements accurately. Given the paucity of 3D emotional talking face data in the animation industry, we capture facial expressions under the guidance of animation experts using LiveLinkFace on an iPhone. This effort results in the creation of an innovative 3D blendshape emotional talking face dataset (3D-BEF) used to train our network. Extensive experiments and perceptual evaluations validate the effectiveness of our approach, confirming its superiority in generating realistic and emotionally rich facial animations.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
OOD-HOI: Text-Driven 3D Whole-Body Human-Object Interactions Generation Beyond Training Domains
Nov 27, 2024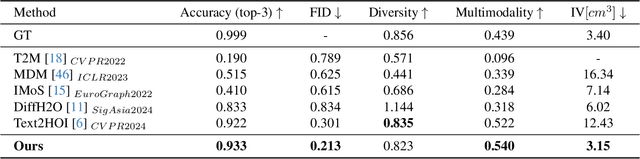
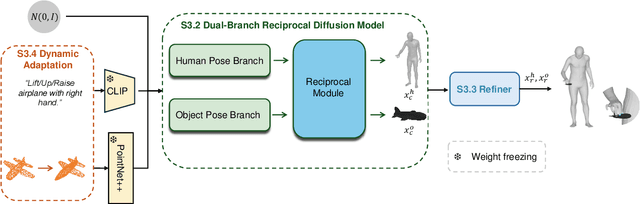
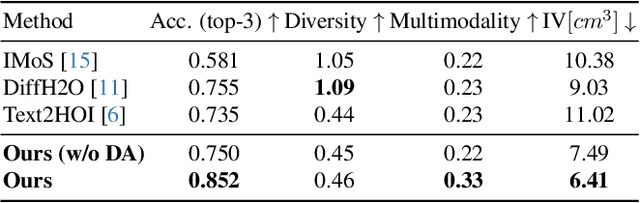
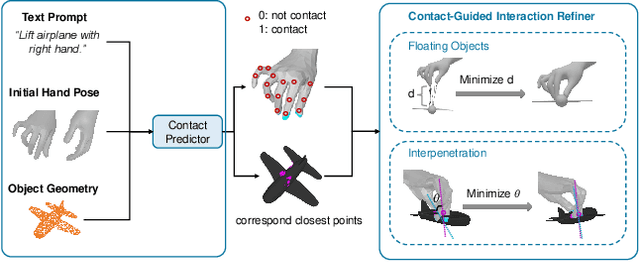
Generating realistic 3D human-object interactions (HOIs) from text descriptions is a active research topic with potential applications in virtual and augmented reality, robotics, and animation. However, creating high-quality 3D HOIs remains challenging due to the lack of large-scale interaction data and the difficulty of ensuring physical plausibility, especially in out-of-domain (OOD) scenarios. Current methods tend to focus either on the body or the hands, which limits their ability to produce cohesive and realistic interactions. In this paper, we propose OOD-HOI, a text-driven framework for generating whole-body human-object interactions that generalize well to new objects and actions. Our approach integrates a dual-branch reciprocal diffusion model to synthesize initial interaction poses, a contact-guided interaction refiner to improve physical accuracy based on predicted contact areas, and a dynamic adaptation mechanism which includes semantic adjustment and geometry deformation to improve robustness. Experimental results demonstrate that our OOD-HOI could generate more realistic and physically plausible 3D interaction pose in OOD scenarios compared to existing methods.
CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes
Nov 01, 2024



Recently, 3D Gaussian Splatting (3DGS) has revolutionized radiance field reconstruction, manifesting efficient and high-fidelity novel view synthesis. However, accurately representing surfaces, especially in large and complex scenarios, remains a significant challenge due to the unstructured nature of 3DGS. In this paper, we present CityGaussianV2, a novel approach for large-scale scene reconstruction that addresses critical challenges related to geometric accuracy and efficiency. Building on the favorable generalization capabilities of 2D Gaussian Splatting (2DGS), we address its convergence and scalability issues. Specifically, we implement a decomposed-gradient-based densification and depth regression technique to eliminate blurry artifacts and accelerate convergence. To scale up, we introduce an elongation filter that mitigates Gaussian count explosion caused by 2DGS degeneration. Furthermore, we optimize the CityGaussian pipeline for parallel training, achieving up to 10$\times$ compression, at least 25% savings in training time, and a 50% decrease in memory usage. We also established standard geometry benchmarks under large-scale scenes. Experimental results demonstrate that our method strikes a promising balance between visual quality, geometric accuracy, as well as storage and training costs. The project page is available at https://dekuliutesla.github.io/CityGaussianV2/.
MTU-Bench: A Multi-granularity Tool-Use Benchmark for Large Language Models
Oct 15, 2024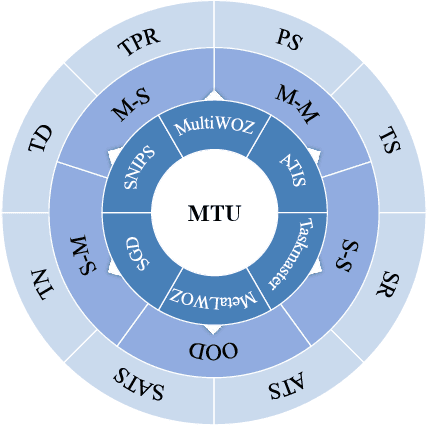
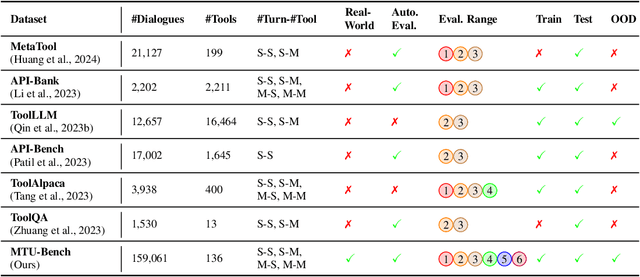
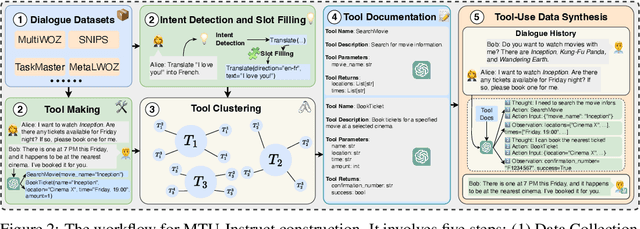
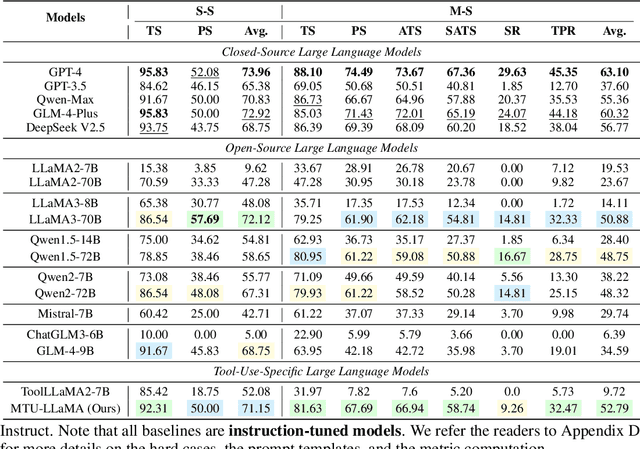
Large Language Models (LLMs) have displayed massive improvements in reasoning and decision-making skills and can hold natural conversations with users. Recently, many tool-use benchmark datasets have been proposed. However, existing datasets have the following limitations: (1). Insufficient evaluation scenarios (e.g., only cover limited tool-use scenes). (2). Extensive evaluation costs (e.g., GPT API costs). To address these limitations, in this work, we propose a multi-granularity tool-use benchmark for large language models called MTU-Bench. For the "multi-granularity" property, our MTU-Bench covers five tool usage scenes (i.e., single-turn and single-tool, single-turn and multiple-tool, multiple-turn and single-tool, multiple-turn and multiple-tool, and out-of-distribution tasks). Besides, all evaluation metrics of our MTU-Bench are based on the prediction results and the ground truth without using any GPT or human evaluation metrics. Moreover, our MTU-Bench is collected by transforming existing high-quality datasets to simulate real-world tool usage scenarios, and we also propose an instruction dataset called MTU-Instruct data to enhance the tool-use abilities of existing LLMs. Comprehensive experimental results demonstrate the effectiveness of our MTU-Bench. Code and data will be released at https: //github.com/MTU-Bench-Team/MTU-Bench.git.
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
Sep 24, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks (e.g., long-context understanding), and many benchmarks have been proposed. However, we observe that long text generation capabilities are not well investigated. Therefore, we introduce the Hierarchical Long Text Generation Benchmark (HelloBench), a comprehensive, in-the-wild, and open-ended benchmark to evaluate LLMs' performance in generating long text. Based on Bloom's Taxonomy, HelloBench categorizes long text generation tasks into five subtasks: open-ended QA, summarization, chat, text completion, and heuristic text generation. Besides, we propose Hierarchical Long Text Evaluation (HelloEval), a human-aligned evaluation method that significantly reduces the time and effort required for human evaluation while maintaining a high correlation with human evaluation. We have conducted extensive experiments across around 30 mainstream LLMs and observed that the current LLMs lack long text generation capabilities. Specifically, first, regardless of whether the instructions include explicit or implicit length constraints, we observe that most LLMs cannot generate text that is longer than 4000 words. Second, we observe that while some LLMs can generate longer text, many issues exist (e.g., severe repetition and quality degradation). Third, to demonstrate the effectiveness of HelloEval, we compare HelloEval with traditional metrics (e.g., ROUGE, BLEU, etc.) and LLM-as-a-Judge methods, which show that HelloEval has the highest correlation with human evaluation. We release our code in https://github.com/Quehry/HelloBench.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024
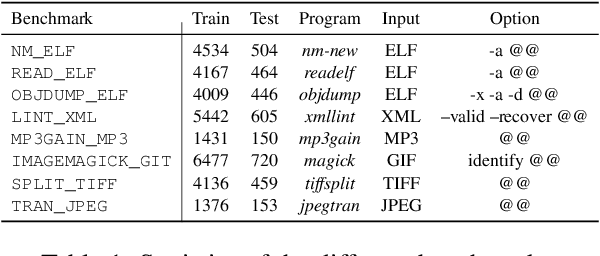
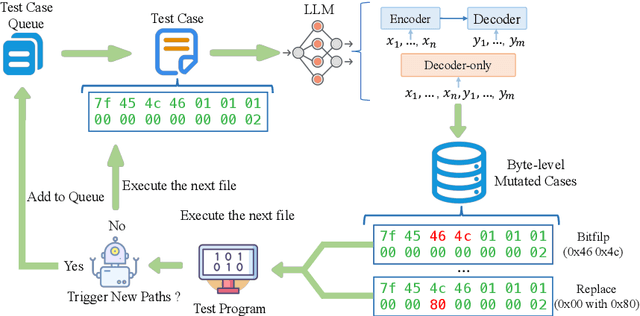
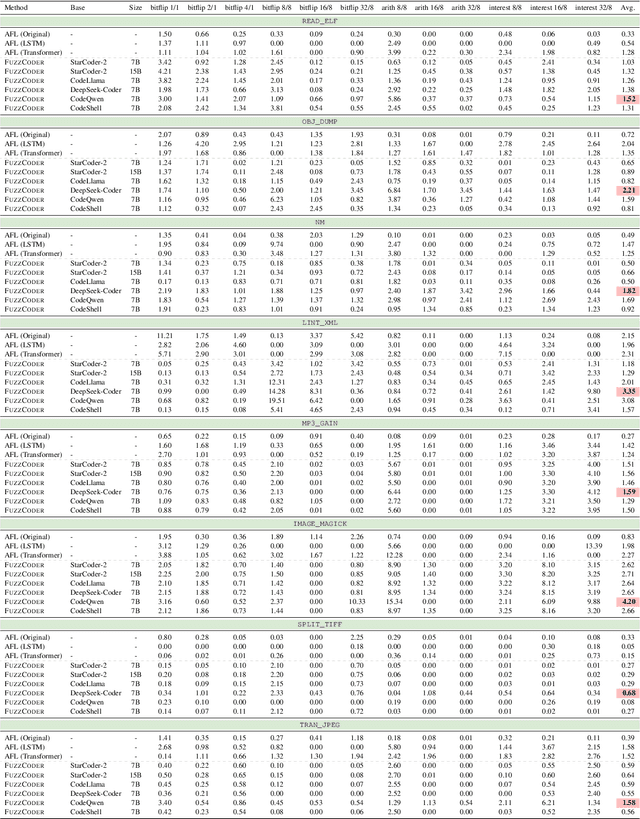
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
CityX: Controllable Procedural Content Generation for Unbounded 3D Cities
Jul 29, 2024
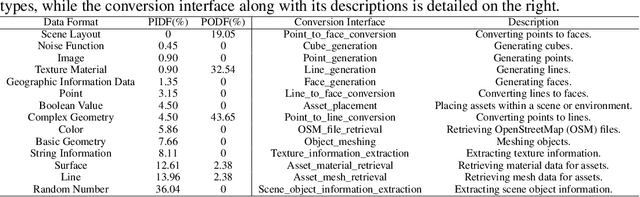
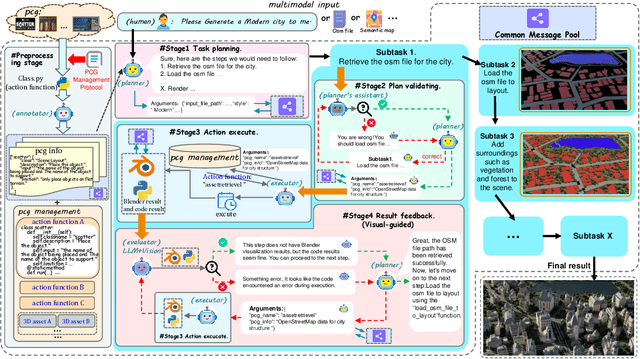
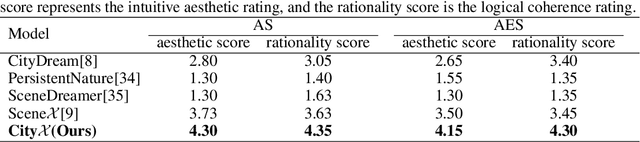
Generating a realistic, large-scale 3D virtual city remains a complex challenge due to the involvement of numerous 3D assets, various city styles, and strict layout constraints. Existing approaches provide promising attempts at procedural content generation to create large-scale scenes using Blender agents. However, they face crucial issues such as difficulties in scaling up generation capability and achieving fine-grained control at the semantic layout level. To address these problems, we propose a novel multi-modal controllable procedural content generation method, named CityX, which enhances realistic, unbounded 3D city generation guided by multiple layout conditions, including OSM, semantic maps, and satellite images. Specifically, the proposed method contains a general protocol for integrating various PCG plugins and a multi-agent framework for transforming instructions into executable Blender actions. Through this effective framework, CityX shows the potential to build an innovative ecosystem for 3D scene generation by bridging the gap between the quality of generated assets and industrial requirements. Extensive experiments have demonstrated the effectiveness of our method in creating high-quality, diverse, and unbounded cities guided by multi-modal conditions. Our project page: https://cityx-lab.github.io.