 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamProfileBench: A Benchmark for Fine-Grained User Profile Inference in Real-World Streaming Scenarios
May 26, 2026Large Language Models (LLMs) have reshaped user profiling, yet current evaluations mainly focus on static data snapshots. This paradigm overlooks the reality of personalized systems, where User-Generated Content (UGC) arrives continuously and fine-grained profile evolve rapidly. To bridge this gap, we introduce StreamProfileBench, a large-scale benchmark for fine-grained streaming user profiling. We formalize streaming user profiling as a continuous state maintenance task and curate a highly authentic dataset comprising over 120,000 UGC posts from 7,000+ real users across five diverse platforms. By leveraging the temporal correlation of user interests, we further propose a novel, annotation-free evaluation framework. Extensive experiments across 14 leading LLMs reveal that continuous profile updating remains an open challenge. Models exhibit a systemic conservative bias, over-retaining past interests while failing to recognize interest decay. Ablation experiments further validate the practical utility and necessity of the streaming paradigm.
LifeSim: Long-Horizon User Life Simulator for Personalized Assistant Evaluation
Mar 12, 2026The rapid advancement of large language models (LLMs) has accelerated progress toward universal AI assistants. However, existing benchmarks for personalized assistants remain misaligned with real-world user-assistant interactions, failing to capture the complexity of external contexts and users' cognitive states. To bridge this gap, we propose LifeSim, a user simulator that models user cognition through the Belief-Desire-Intention (BDI) model within physical environments for coherent life trajectories generation, and simulates intention-driven user interactive behaviors. Based on LifeSim, we introduce LifeSim-Eval, a comprehensive benchmark for multi-scenario, long-horizon personalized assistance. LifeSim-Eval covers 8 life domains and 1,200 diverse scenarios, and adopts a multi-turn interactive method to assess models' abilities to complete explicit and implicit intentions, recover user profiles, and produce high-quality responses. Under both single-scenario and long-horizon settings, our experiments reveal that current LLMs face significant limitations in handling implicit intention and long-term user preference modeling.
Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science
Feb 05, 2026Recent advancements in Large Language Models (LLMs) have greatly extended the capabilities of Multi-Agent Systems (MAS), demonstrating significant effectiveness across a wide range of complex and open-ended domains. However, despite this rapid progress, the field still relies heavily on empirical trial-and-error. It lacks a unified and principled scientific framework necessary for systematic optimization and improvement. This bottleneck stems from the ambiguity of attribution: first, the absence of a structured taxonomy of factors leaves researchers restricted to unguided adjustments; second, the lack of a unified metric fails to distinguish genuine collaboration gain from mere resource accumulation. In this paper, we advocate for a transition to design science through an integrated framework. We advocate to establish the collaboration gain metric ($Γ$) as the scientific standard to isolate intrinsic gains from increased budgets. Leveraging $Γ$, we propose a factor attribution paradigm to systematically identify collaboration-driving factors. To support this, we construct a systematic MAS factor library, structuring the design space into control-level presets and information-level dynamics. Ultimately, this framework facilitates the transition from blind experimentation to rigorous science, paving the way towards a true science of Collective AI.
NexViTAD: Few-shot Unsupervised Cross-Domain Defect Detection via Vision Foundation Models and Multi-Task Learning
Jul 10, 2025This paper presents a novel few-shot cross-domain anomaly detection framework, Nexus Vision Transformer for Anomaly Detection (NexViTAD), based on vision foundation models, which effectively addresses domain-shift challenges in industrial anomaly detection through innovative shared subspace projection mechanisms and multi-task learning (MTL) module. The main innovations include: (1) a hierarchical adapter module that adaptively fuses complementary features from Hiera and DINO-v2 pre-trained models, constructing more robust feature representations; (2) a shared subspace projection strategy that enables effective cross-domain knowledge transfer through bottleneck dimension constraints and skip connection mechanisms; (3) a MTL Decoder architecture supports simultaneous processing of multiple source domains, significantly enhancing model generalization capabilities; (4) an anomaly score inference method based on Sinkhorn-K-means clustering, combined with Gaussian filtering and adaptive threshold processing for precise pixel level. Valuated on the MVTec AD dataset, NexViTAD delivers state-of-the-art performance with an AUC of 97.5%, AP of 70.4%, and PRO of 95.2% in the target domains, surpassing other recent models, marking a transformative advance in cross-domain defect detection.
Enhancing LLMs via High-Knowledge Data Selection
May 20, 2025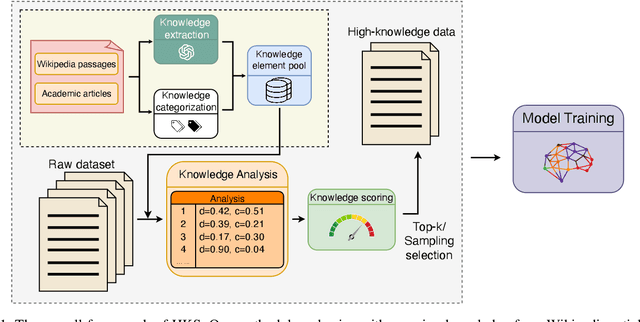
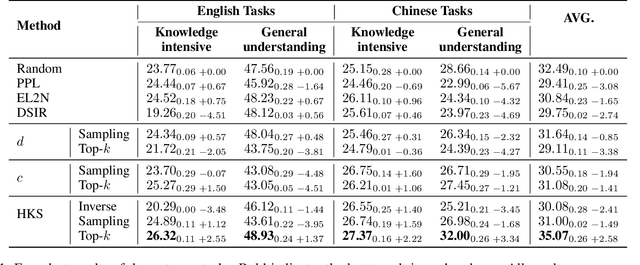
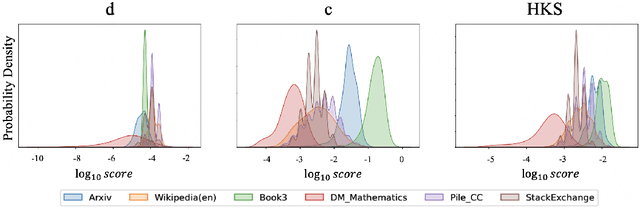
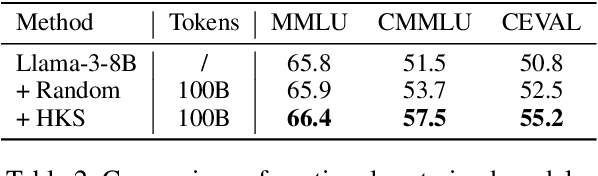
The performance of Large Language Models (LLMs) is intrinsically linked to the quality of its training data. Although several studies have proposed methods for high-quality data selection, they do not consider the importance of knowledge richness in text corpora. In this paper, we propose a novel and gradient-free High-Knowledge Scorer (HKS) to select high-quality data from the dimension of knowledge, to alleviate the problem of knowledge scarcity in the pre-trained corpus. We propose a comprehensive multi-domain knowledge element pool and introduce knowledge density and coverage as metrics to assess the knowledge content of the text. Based on this, we propose a comprehensive knowledge scorer to select data with intensive knowledge, which can also be utilized for domain-specific high-knowledge data selection by restricting knowledge elements to the specific domain. We train models on a high-knowledge bilingual dataset, and experimental results demonstrate that our scorer improves the model's performance in knowledge-intensive and general comprehension tasks, and is effective in enhancing both the generic and domain-specific capabilities of the model.
FRAMES: Boosting LLMs with A Four-Quadrant Multi-Stage Pretraining Strategy
Feb 08, 2025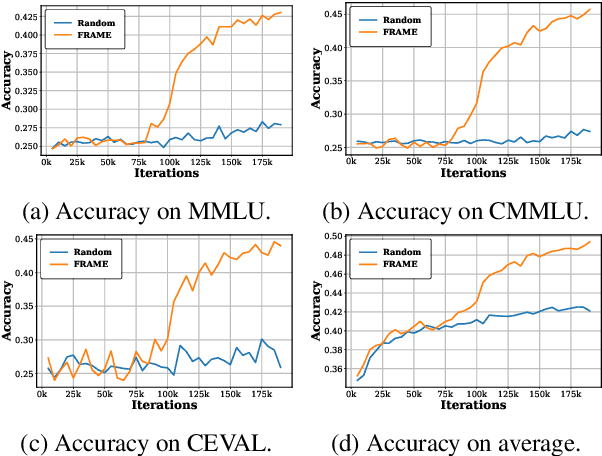
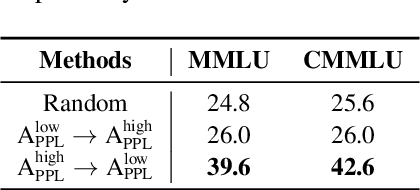
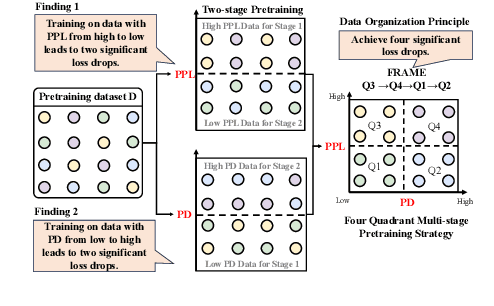
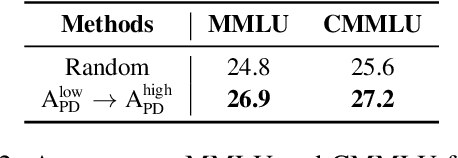
Large language models (LLMs) have significantly advanced human language understanding and generation, with pretraining data quality and organization being crucial to their performance. Multi-stage pretraining is a promising approach, but existing methods often lack quantitative criteria for data partitioning and instead rely on intuitive heuristics. In this paper, we propose the novel Four-quadRAnt Multi-stage prEtraining Strategy (FRAMES), guided by the established principle of organizing the pretraining process into four stages to achieve significant loss reductions four times. This principle is grounded in two key findings: first, training on high Perplexity (PPL) data followed by low PPL data, and second, training on low PPL difference (PD) data followed by high PD data, both causing the loss to drop significantly twice and performance enhancements. By partitioning data into four quadrants and strategically organizing them, FRAMES achieves a remarkable 16.8% average improvement over random sampling across MMLU and CMMLU, effectively boosting LLM performance.
FIRE: Flexible Integration of Data Quality Ratings for Effective Pre-Training
Feb 02, 2025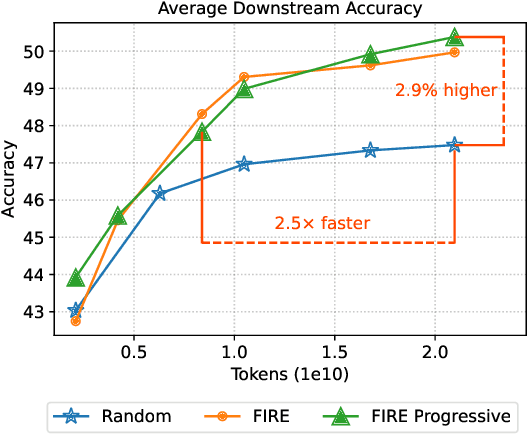
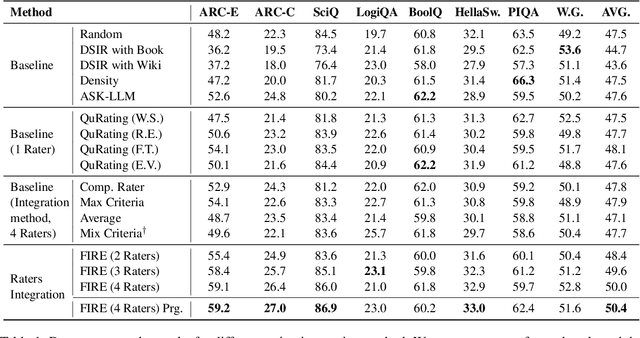
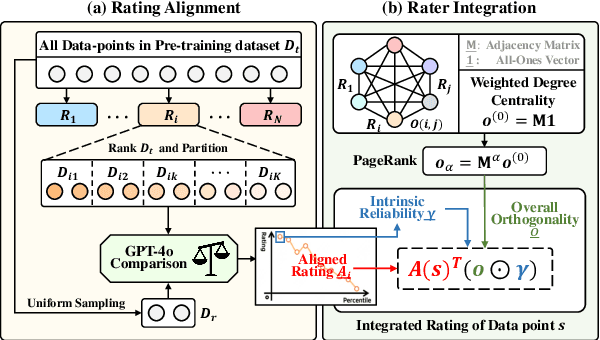

Selecting high-quality data can significantly improve the pre-training efficiency of large language models (LLMs). Existing methods often rely on heuristic techniques and single quality signals, limiting their ability to comprehensively evaluate data quality. In this work, we propose FIRE, a flexible and scalable framework for integrating multiple data quality raters, which allows for a comprehensive assessment of data quality across various dimensions. FIRE aligns multiple quality signals into a unified space, and integrates diverse data quality raters to provide a comprehensive quality signal for each data point. Further, we introduce a progressive data selection scheme based on FIRE that iteratively refines the selection of high-quality data points, balancing computational complexity with the refinement of orthogonality. Experiments on the SlimPajama dataset reveal that FIRE consistently outperforms other selection methods and significantly enhances the pre-trained model across a wide range of downstream tasks, with a 2.9\% average performance boost and reducing the FLOPs necessary to achieve a certain performance level by more than half.
PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness
Oct 09, 2024Large Language Models (LLMs) demonstrate impressive capabilities across various domains, including role-playing, creative writing, mathematical reasoning, and coding. Despite these advancements, LLMs still encounter challenges with length control, frequently failing to adhere to specific length constraints due to their token-level operations and insufficient training on data with strict length limitations. We identify this issue as stemming from a lack of positional awareness and propose novel approaches--PositionID Prompting and PositionID Fine-Tuning--to address it. These methods enhance the model's ability to continuously monitor and manage text length during generation. Additionally, we introduce PositionID CP Prompting to enable LLMs to perform copy and paste operations accurately. Furthermore, we develop two benchmarks for evaluating length control and copy-paste abilities. Our experiments demonstrate that our methods significantly improve the model's adherence to length constraints and copy-paste accuracy without compromising response quality.
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
Sep 24, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks (e.g., long-context understanding), and many benchmarks have been proposed. However, we observe that long text generation capabilities are not well investigated. Therefore, we introduce the Hierarchical Long Text Generation Benchmark (HelloBench), a comprehensive, in-the-wild, and open-ended benchmark to evaluate LLMs' performance in generating long text. Based on Bloom's Taxonomy, HelloBench categorizes long text generation tasks into five subtasks: open-ended QA, summarization, chat, text completion, and heuristic text generation. Besides, we propose Hierarchical Long Text Evaluation (HelloEval), a human-aligned evaluation method that significantly reduces the time and effort required for human evaluation while maintaining a high correlation with human evaluation. We have conducted extensive experiments across around 30 mainstream LLMs and observed that the current LLMs lack long text generation capabilities. Specifically, first, regardless of whether the instructions include explicit or implicit length constraints, we observe that most LLMs cannot generate text that is longer than 4000 words. Second, we observe that while some LLMs can generate longer text, many issues exist (e.g., severe repetition and quality degradation). Third, to demonstrate the effectiveness of HelloEval, we compare HelloEval with traditional metrics (e.g., ROUGE, BLEU, etc.) and LLM-as-a-Judge methods, which show that HelloEval has the highest correlation with human evaluation. We release our code in https://github.com/Quehry/HelloBench.
D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models
Jun 03, 2024



Continual Pre-Training (CPT) on Large Language Models (LLMs) has been widely used to expand the model's fundamental understanding of specific downstream domains (e.g., math and code). For the CPT on domain-specific LLMs, one important question is how to choose the optimal mixture ratio between the general-corpus (e.g., Dolma, Slim-pajama) and the downstream domain-corpus. Existing methods usually adopt laborious human efforts by grid-searching on a set of mixture ratios, which require high GPU training consumption costs. Besides, we cannot guarantee the selected ratio is optimal for the specific domain. To address the limitations of existing methods, inspired by the Scaling Law for performance prediction, we propose to investigate the Scaling Law of the Domain-specific Continual Pre-Training (D-CPT Law) to decide the optimal mixture ratio with acceptable training costs for LLMs of different sizes. Specifically, by fitting the D-CPT Law, we can easily predict the general and downstream performance of arbitrary mixture ratios, model sizes, and dataset sizes using small-scale training costs on limited experiments. Moreover, we also extend our standard D-CPT Law on cross-domain settings and propose the Cross-Domain D-CPT Law to predict the D-CPT law of target domains, where very small training costs (about 1% of the normal training costs) are needed for the target domains. Comprehensive experimental results on six downstream domains demonstrate the effectiveness and generalizability of our proposed D-CPT Law and Cross-Domain D-CPT Law.