 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAMES: Boosting LLMs with A Four-Quadrant Multi-Stage Pretraining Strategy
Paper and Code
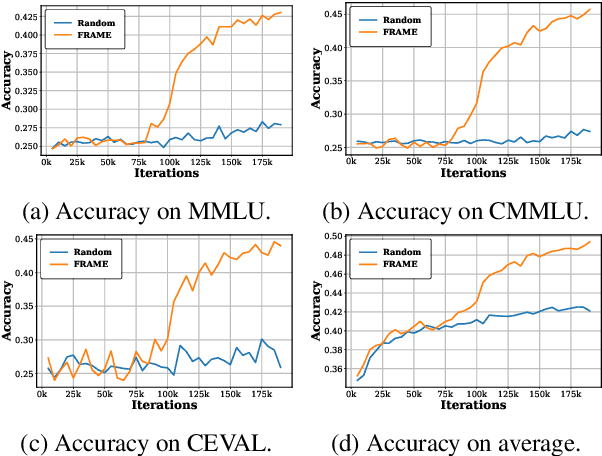
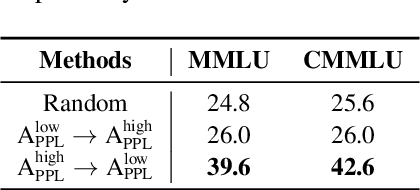
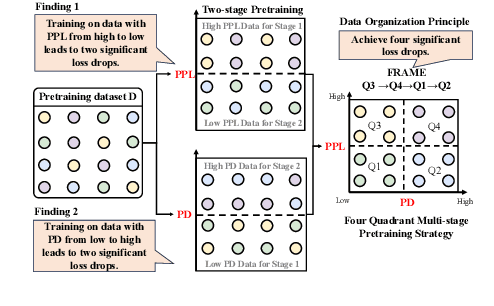
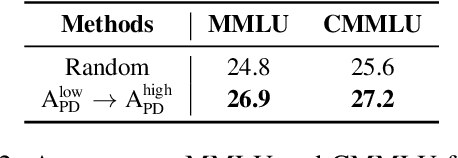
Large language models (LLMs) have significantly advanced human language understanding and generation, with pretraining data quality and organization being crucial to their performance. Multi-stage pretraining is a promising approach, but existing methods often lack quantitative criteria for data partitioning and instead rely on intuitive heuristics. In this paper, we propose the novel Four-quadRAnt Multi-stage prEtraining Strategy (FRAMES), guided by the established principle of organizing the pretraining process into four stages to achieve significant loss reductions four times. This principle is grounded in two key findings: first, training on high Perplexity (PPL) data followed by low PPL data, and second, training on low PPL difference (PD) data followed by high PD data, both causing the loss to drop significantly twice and performance enhancements. By partitioning data into four quadrants and strategically organizing them, FRAMES achieves a remarkable 16.8% average improvement over random sampling across MMLU and CMMLU, effectively boosting LLM performance.