 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
GEWDiff: Geometric Enhanced Wavelet-based Diffusion Model for Hyperspectral Image Super-resolution
Nov 10, 2025Improving the quality of hyperspectral images (HSIs), such as through super-resolution, is a crucial research area. However, generative modeling for HSIs presents several challenges. Due to their high spectral dimensionality, HSIs are too memory-intensive for direct input into conventional diffusion models. Furthermore, general generative models lack an understanding of the topological and geometric structures of ground objects in remote sensing imagery. In addition, most diffusion models optimize loss functions at the noise level, leading to a non-intuitive convergence behavior and suboptimal generation quality for complex data. To address these challenges, we propose a Geometric Enhanced Wavelet-based Diffusion Model (GEWDiff), a novel framework for reconstructing hyperspectral images at 4-times super-resolution. A wavelet-based encoder-decoder is introduced that efficiently compresses HSIs into a latent space while preserving spectral-spatial information. To avoid distortion during generation, we incorporate a geometry-enhanced diffusion process that preserves the geometric features. Furthermore, a multi-level loss function was designed to guide the diffusion process, promoting stable convergence and improved reconstruction fidelity. Our model demonstrated state-of-the-art results across multiple dimensions, including fidelity, spectral accuracy, visual realism, and clarity.
CaSTFormer: Causal Spatio-Temporal Transformer for Driving Intention Prediction
Jul 17, 2025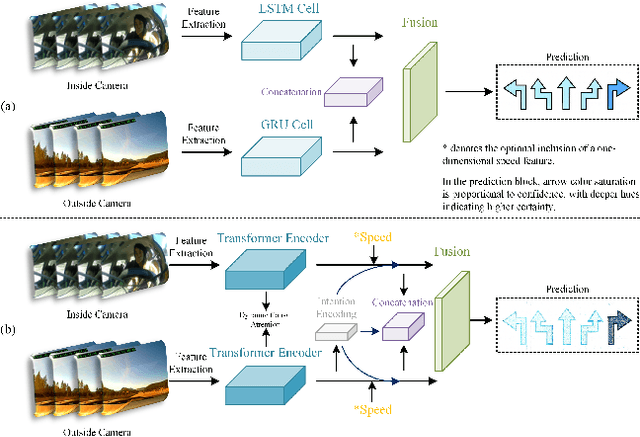



Accurate prediction of driving intention is key to enhancing the safety and interactive efficiency of human-machine co-driving systems. It serves as a cornerstone for achieving high-level autonomous driving. However, current approaches remain inadequate for accurately modeling the complex spatio-temporal interdependencies and the unpredictable variability of human driving behavior. To address these challenges, we propose CaSTFormer, a Causal Spatio-Temporal Transformer to explicitly model causal interactions between driver behavior and environmental context for robust intention prediction. Specifically, CaSTFormer introduces a novel Reciprocal Shift Fusion (RSF) mechanism for precise temporal alignment of internal and external feature streams, a Causal Pattern Extraction (CPE) module that systematically eliminates spurious correlations to reveal authentic causal dependencies, and an innovative Feature Synthesis Network (FSN) that adaptively synthesizes these purified representations into coherent spatio-temporal inferences. We evaluate the proposed CaSTFormer on the public Brain4Cars dataset, and it achieves state-of-the-art performance. It effectively captures complex causal spatio-temporal dependencies and enhances both the accuracy and transparency of driving intention prediction.
Enhancing LLMs via High-Knowledge Data Selection
May 20, 2025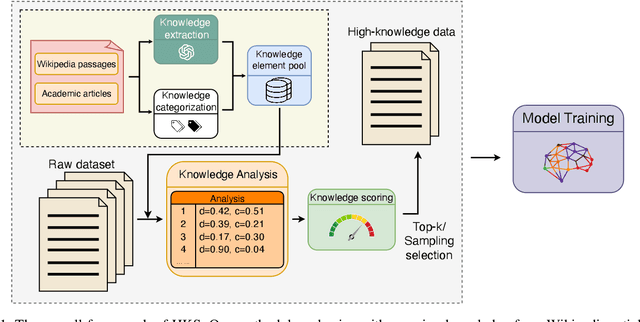
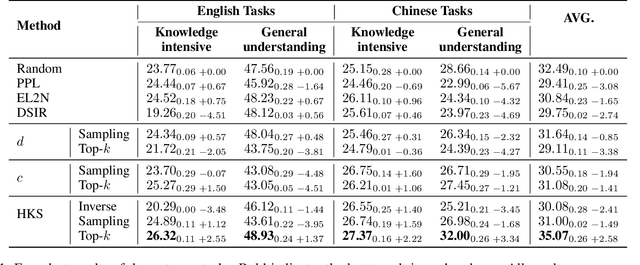
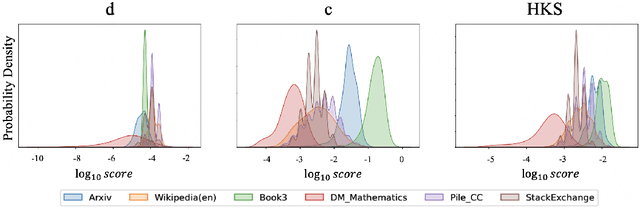
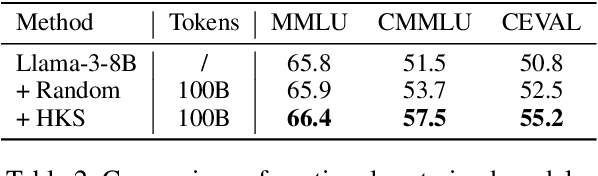
The performance of Large Language Models (LLMs) is intrinsically linked to the quality of its training data. Although several studies have proposed methods for high-quality data selection, they do not consider the importance of knowledge richness in text corpora. In this paper, we propose a novel and gradient-free High-Knowledge Scorer (HKS) to select high-quality data from the dimension of knowledge, to alleviate the problem of knowledge scarcity in the pre-trained corpus. We propose a comprehensive multi-domain knowledge element pool and introduce knowledge density and coverage as metrics to assess the knowledge content of the text. Based on this, we propose a comprehensive knowledge scorer to select data with intensive knowledge, which can also be utilized for domain-specific high-knowledge data selection by restricting knowledge elements to the specific domain. We train models on a high-knowledge bilingual dataset, and experimental results demonstrate that our scorer improves the model's performance in knowledge-intensive and general comprehension tasks, and is effective in enhancing both the generic and domain-specific capabilities of the model.
Feature-Aware Malicious Output Detection and Mitigation
Apr 12, 2025



The rapid advancement of large language models (LLMs) has brought significant benefits to various domains while introducing substantial risks. Despite being fine-tuned through reinforcement learning, LLMs lack the capability to discern malicious content, limiting their defense against jailbreak. To address these safety concerns, we propose a feature-aware method for harmful response rejection (FMM), which detects the presence of malicious features within the model's feature space and adaptively adjusts the model's rejection mechanism. By employing a simple discriminator, we detect potential malicious traits during the decoding phase. Upon detecting features indicative of toxic tokens, FMM regenerates the current token. By employing activation patching, an additional rejection vector is incorporated during the subsequent token generation, steering the model towards a refusal response. Experimental results demonstrate the effectiveness of our approach across multiple language models and diverse attack techniques, while crucially maintaining the models' standard generation capabilities.
Latent Distribution Decoupling: A Probabilistic Framework for Uncertainty-Aware Multimodal Emotion Recognition
Feb 19, 2025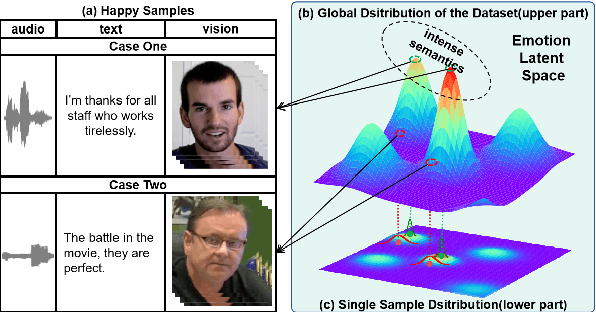
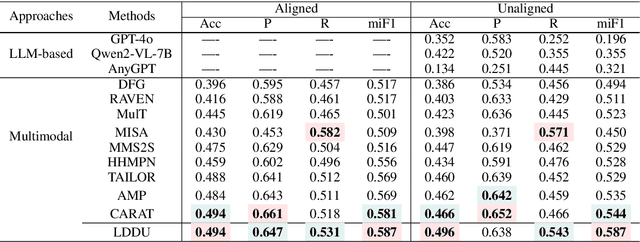
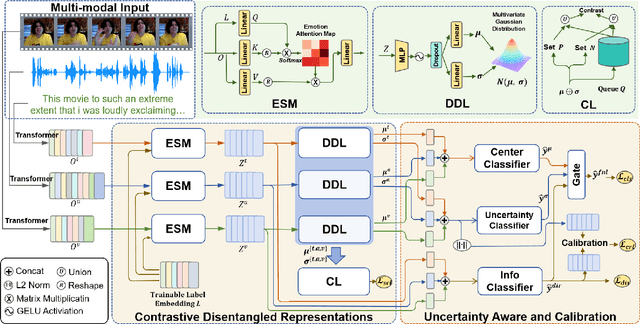
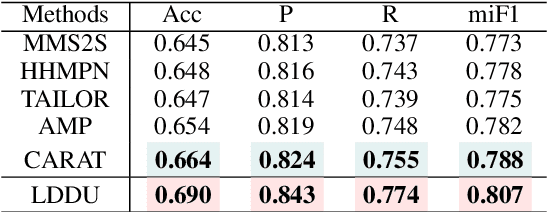
Multimodal multi-label emotion recognition (MMER) aims to identify the concurrent presence of multiple emotions in multimodal data. Existing studies primarily focus on improving fusion strategies and modeling modality-to-label dependencies. However, they often overlook the impact of \textbf{aleatoric uncertainty}, which is the inherent noise in the multimodal data and hinders the effectiveness of modality fusion by introducing ambiguity into feature representations. To address this issue and effectively model aleatoric uncertainty, this paper proposes Latent emotional Distribution Decomposition with Uncertainty perception (LDDU) framework from a novel perspective of latent emotional space probabilistic modeling. Specifically, we introduce a contrastive disentangled distribution mechanism within the emotion space to model the multimodal data, allowing for the extraction of semantic features and uncertainty. Furthermore, we design an uncertainty-aware fusion multimodal method that accounts for the dispersed distribution of uncertainty and integrates distribution information. Experimental results show that LDDU achieves state-of-the-art performance on the CMU-MOSEI and M$^3$ED datasets, highlighting the importance of uncertainty modeling in MMER. Code is available at https://github.com/201983290498/lddu\_mmer.git.
FRAMES: Boosting LLMs with A Four-Quadrant Multi-Stage Pretraining Strategy
Feb 08, 2025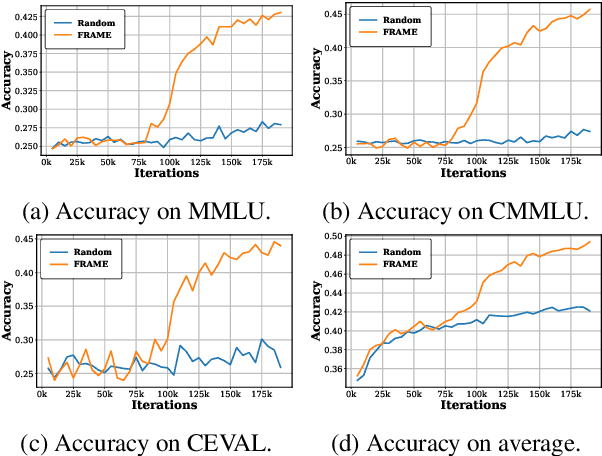
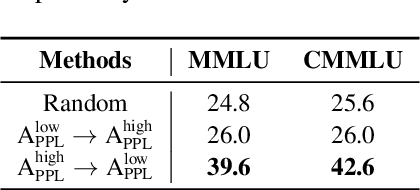
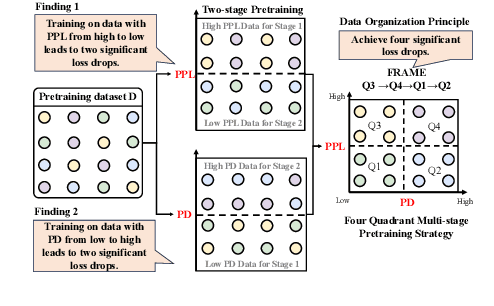
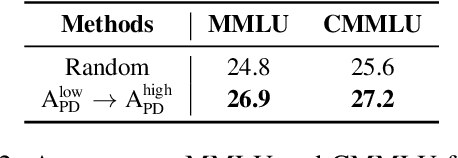
Large language models (LLMs) have significantly advanced human language understanding and generation, with pretraining data quality and organization being crucial to their performance. Multi-stage pretraining is a promising approach, but existing methods often lack quantitative criteria for data partitioning and instead rely on intuitive heuristics. In this paper, we propose the novel Four-quadRAnt Multi-stage prEtraining Strategy (FRAMES), guided by the established principle of organizing the pretraining process into four stages to achieve significant loss reductions four times. This principle is grounded in two key findings: first, training on high Perplexity (PPL) data followed by low PPL data, and second, training on low PPL difference (PD) data followed by high PD data, both causing the loss to drop significantly twice and performance enhancements. By partitioning data into four quadrants and strategically organizing them, FRAMES achieves a remarkable 16.8% average improvement over random sampling across MMLU and CMMLU, effectively boosting LLM performance.
FIRE: Flexible Integration of Data Quality Ratings for Effective Pre-Training
Feb 02, 2025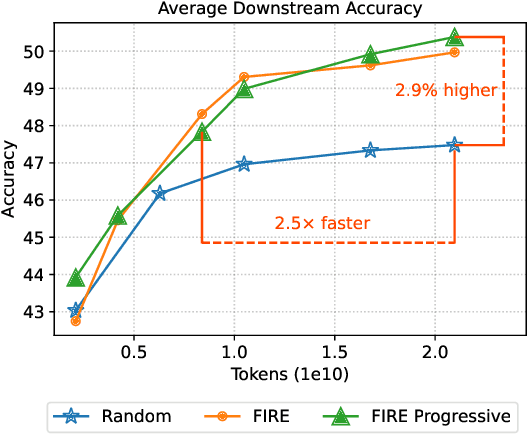
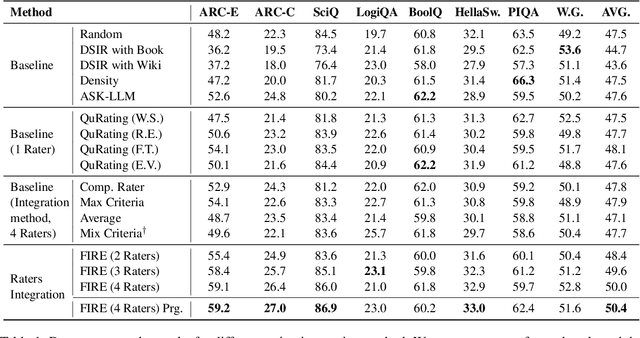
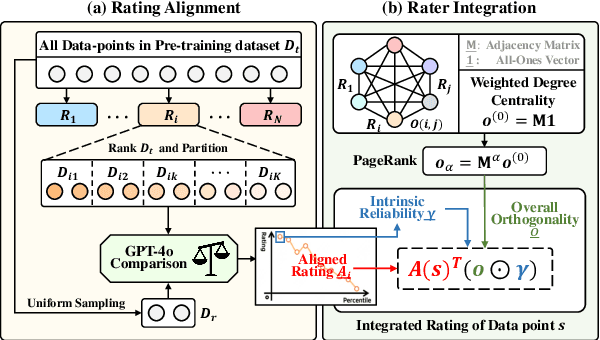

Selecting high-quality data can significantly improve the pre-training efficiency of large language models (LLMs). Existing methods often rely on heuristic techniques and single quality signals, limiting their ability to comprehensively evaluate data quality. In this work, we propose FIRE, a flexible and scalable framework for integrating multiple data quality raters, which allows for a comprehensive assessment of data quality across various dimensions. FIRE aligns multiple quality signals into a unified space, and integrates diverse data quality raters to provide a comprehensive quality signal for each data point. Further, we introduce a progressive data selection scheme based on FIRE that iteratively refines the selection of high-quality data points, balancing computational complexity with the refinement of orthogonality. Experiments on the SlimPajama dataset reveal that FIRE consistently outperforms other selection methods and significantly enhances the pre-trained model across a wide range of downstream tasks, with a 2.9\% average performance boost and reducing the FLOPs necessary to achieve a certain performance level by more than half.
LLMs Know What They Need: Leveraging a Missing Information Guided Framework to Empower Retrieval-Augmented Generation
Apr 22, 2024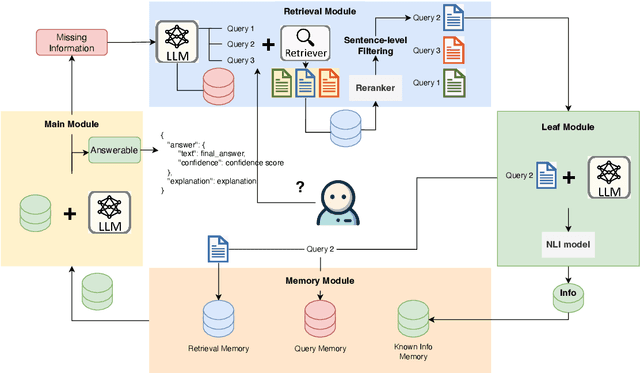
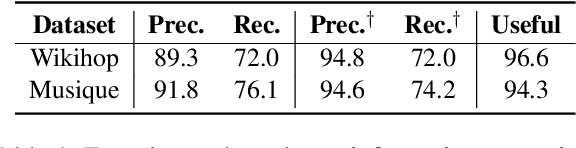
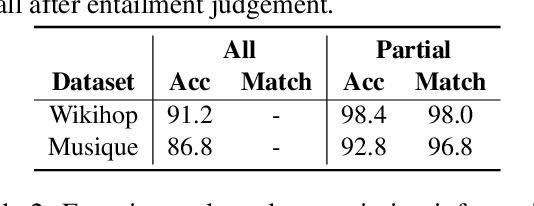
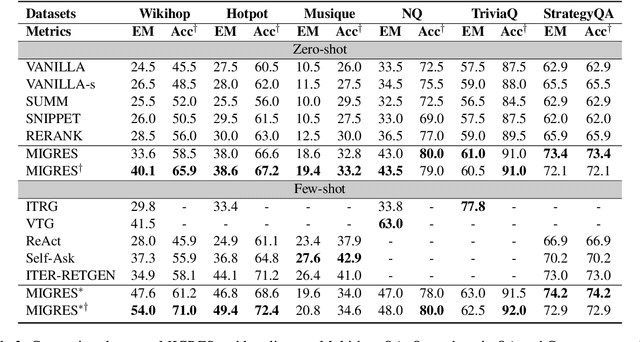
Retrieval-Augmented Generation (RAG) demonstrates great value in alleviating outdated knowledge or hallucination by supplying LLMs with updated and relevant knowledge. However, there are still several difficulties for RAG in understanding complex multi-hop query and retrieving relevant documents, which require LLMs to perform reasoning and retrieve step by step. Inspired by human's reasoning process in which they gradually search for the required information, it is natural to ask whether the LLMs could notice the missing information in each reasoning step. In this work, we first experimentally verified the ability of LLMs to extract information as well as to know the missing. Based on the above discovery, we propose a Missing Information Guided Retrieve-Extraction-Solving paradigm (MIGRES), where we leverage the identification of missing information to generate a targeted query that steers the subsequent knowledge retrieval. Besides, we design a sentence-level re-ranking filtering approach to filter the irrelevant content out from document, along with the information extraction capability of LLMs to extract useful information from cleaned-up documents, which in turn to bolster the overall efficacy of RAG. Extensive experiments conducted on multiple public datasets reveal the superiority of the proposed MIGRES method, and analytical experiments demonstrate the effectiveness of our proposed modules.
Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
Apr 10, 2024The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mitigate hallucinations. However, the existing RAG paradigm inevitably suffers from the impact of flawed information introduced during the retrieval phrase, thereby diminishing the reliability and correctness of the generated outcomes. In this paper, we propose Credibility-aware Generation (CAG), a universally applicable framework designed to mitigate the impact of flawed information in RAG. At its core, CAG aims to equip models with the ability to discern and process information based on its credibility. To this end, we propose an innovative data transformation framework that generates data based on credibility, thereby effectively endowing models with the capability of CAG. Furthermore, to accurately evaluate the models' capabilities of CAG, we construct a comprehensive benchmark covering three critical real-world scenarios. Experimental results demonstrate that our model can effectively understand and utilize credibility for generation, significantly outperform other models with retrieval augmentation, and exhibit resilience against the disruption caused by noisy documents, thereby maintaining robust performance. Moreover, our model supports customized credibility, offering a wide range of potential applications.