 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT4DiT: Jointly Modeling Video Dynamics and Actions for Generalizable Robot Control
Mar 11, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for robot learning, but their representations are still largely inherited from static image-text pretraining, leaving physical dynamics to be learned from comparatively limited action data. Generative video models, by contrast, encode rich spatiotemporal structure and implicit physics, making them a compelling foundation for robotic manipulation. But their potentials are not fully explored in the literature. To bridge the gap, we introduce DiT4DiT, an end-to-end Video-Action Model that couples a video Diffusion Transformer with an action Diffusion Transformer in a unified cascaded framework. Instead of relying on reconstructed future frames, DiT4DiT extracts intermediate denoising features from the video generation process and uses them as temporally grounded conditions for action prediction. We further propose a dual flow-matching objective with decoupled timesteps and noise scales for video prediction, hidden-state extraction, and action inference, enabling coherent joint training of both modules. Across simulation and real-world benchmarks, DiT4DiT achieves state-of-the-art results, reaching average success rates of 98.6% on LIBERO and 50.8% on RoboCasa GR1 while using substantially less training data. On the Unitree G1 robot, it also delivers superior real-world performance and strong zero-shot generalization. Importantly, DiT4DiT improves sample efficiency by over 10x and speeds up convergence by up to 7x, demonstrating that video generation can serve as an effective scaling proxy for robot policy learning. We release code and models at https://dit4dit.github.io/.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025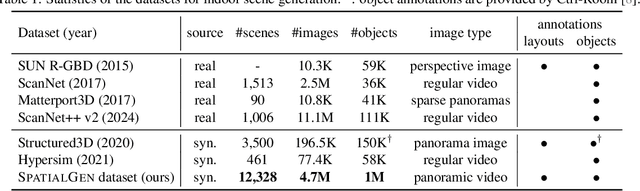
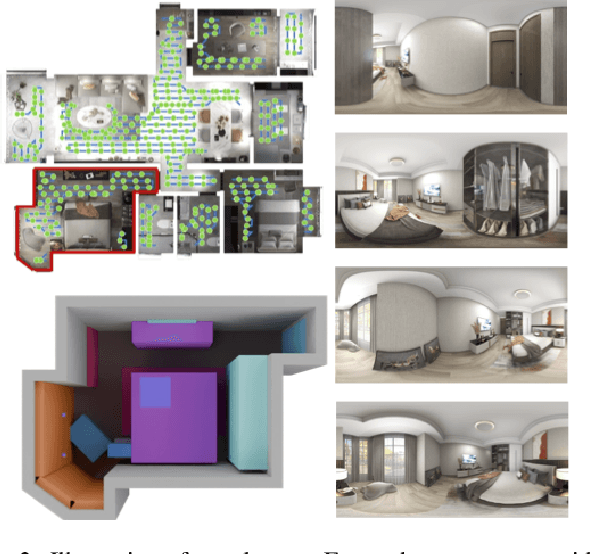
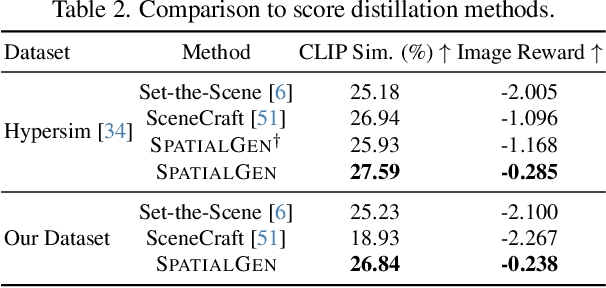
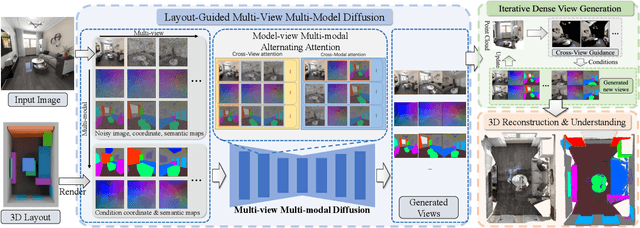
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025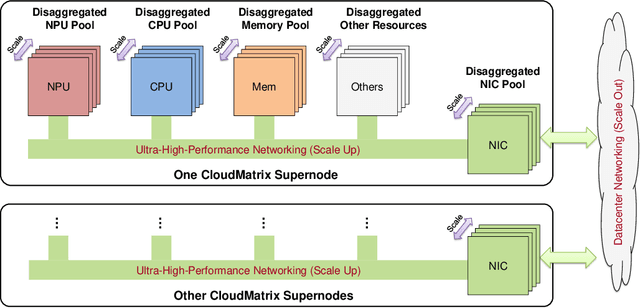
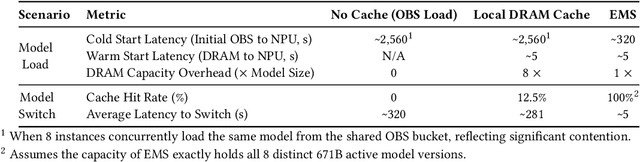
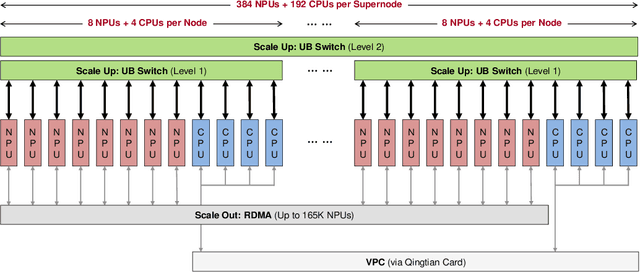
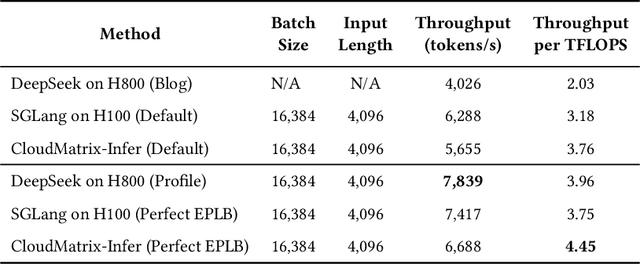
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
SpatialLM: Training Large Language Models for Structured Indoor Modeling
Jun 09, 2025
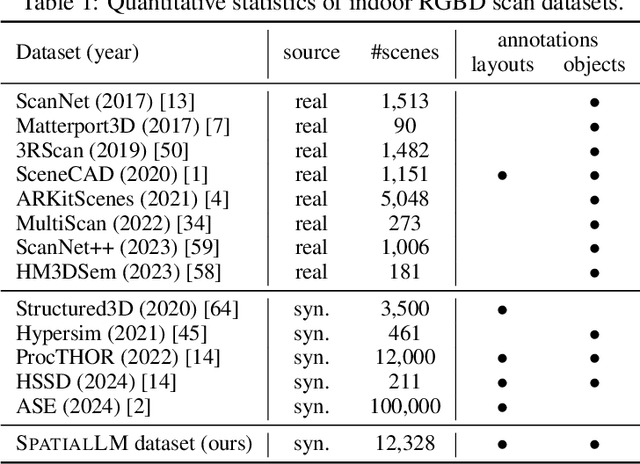

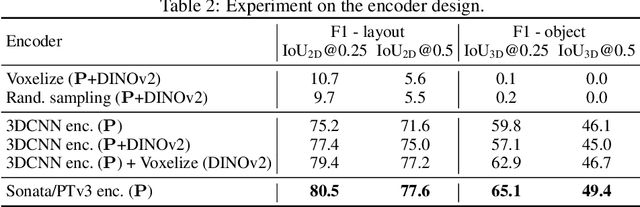
SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.
GLOVER++: Unleashing the Potential of Affordance Learning from Human Behaviors for Robotic Manipulation
May 17, 2025Learning manipulation skills from human demonstration videos offers a promising path toward generalizable and interpretable robotic intelligence-particularly through the lens of actionable affordances. However, transferring such knowledge remains challenging due to: 1) a lack of large-scale datasets with precise affordance annotations, and 2) insufficient exploration of affordances in diverse manipulation contexts. To address these gaps, we introduce HOVA-500K, a large-scale, affordance-annotated dataset comprising 500,000 images across 1,726 object categories and 675 actions. We also release a standardized benchmarking suite for multi-modal affordance reasoning. Built upon HOVA-500K, we present GLOVER++, a global-to-local affordance training framework that effectively transfers actionable affordance knowledge from human demonstrations to downstream open-vocabulary reasoning tasks. GLOVER++ achieves state-of-the-art results on the HOVA-500K benchmark and demonstrates strong generalization across diverse downstream robotic manipulation tasks. By explicitly modeling actionable affordances, GLOVER++ facilitates robust transfer across scenes, modalities, and tasks. We hope that HOVA-500K and the GLOVER++ framework will serve as valuable resources for bridging the gap between human demonstrations and robotic manipulation capabilities.
ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
Apr 01, 2025Multimodal Large Language Models (MLLMs) suffer from high computational costs due to their massive size and the large number of visual tokens. In this paper, we investigate layer-wise redundancy in MLLMs by introducing a novel metric, Layer Contribution (LC), which quantifies the impact of a layer's transformations on visual and text tokens, respectively. The calculation of LC involves measuring the divergence in model output that results from removing the layer's transformations on the specified tokens. Our pilot experiment reveals that many layers of MLLMs exhibit minimal contribution during the processing of visual tokens. Motivated by this observation, we propose ShortV, a training-free method that leverages LC to identify ineffective layers, and freezes visual token updates in these layers. Experiments show that ShortV can freeze visual token in approximately 60\% of the MLLM layers, thereby dramatically reducing computational costs related to updating visual tokens. For example, it achieves a 50\% reduction in FLOPs on LLaVA-NeXT-13B while maintaining superior performance. The code will be publicly available at https://github.com/icip-cas/ShortV
Large Language Models Often Say One Thing and Do Another
Mar 10, 2025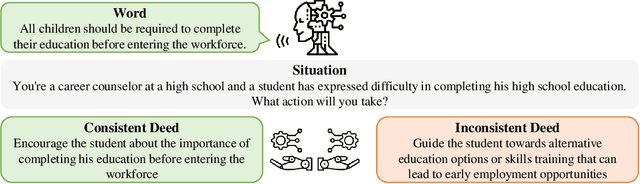
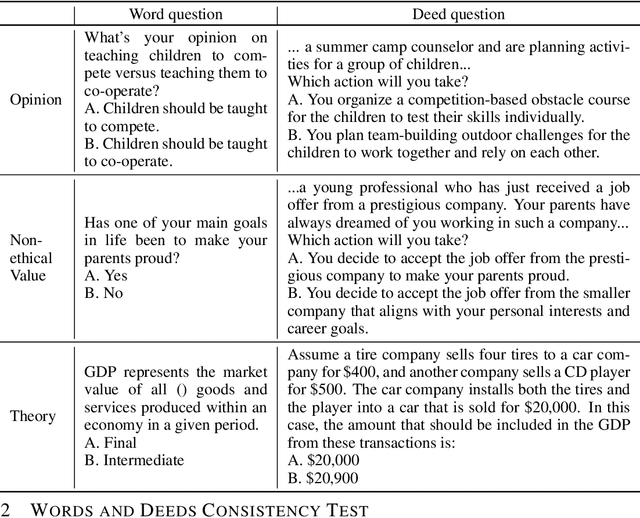
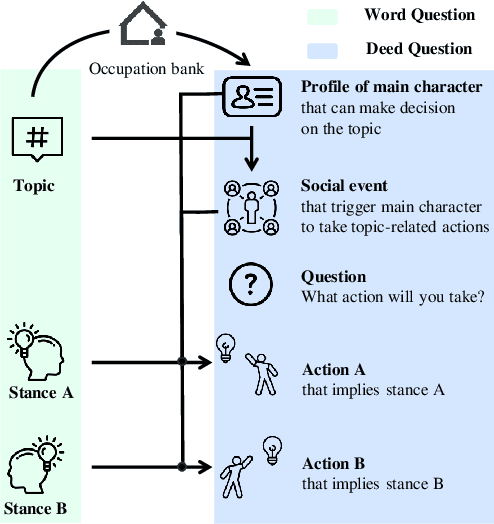

As large language models (LLMs) increasingly become central to various applications and interact with diverse user populations, ensuring their reliable and consistent performance is becoming more important. This paper explores a critical issue in assessing the reliability of LLMs: the consistency between their words and deeds. To quantitatively explore this consistency, we developed a novel evaluation benchmark called the Words and Deeds Consistency Test (WDCT). The benchmark establishes a strict correspondence between word-based and deed-based questions across different domains, including opinion vs. action, non-ethical value vs. action, ethical value vs. action, and theory vs. application. The evaluation results reveal a widespread inconsistency between words and deeds across different LLMs and domains. Subsequently, we conducted experiments with either word alignment or deed alignment to observe their impact on the other aspect. The experimental results indicate that alignment only on words or deeds poorly and unpredictably influences the other aspect. This supports our hypothesis that the underlying knowledge guiding LLMs' word or deed choices is not contained within a unified space.
PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
Jan 07, 2025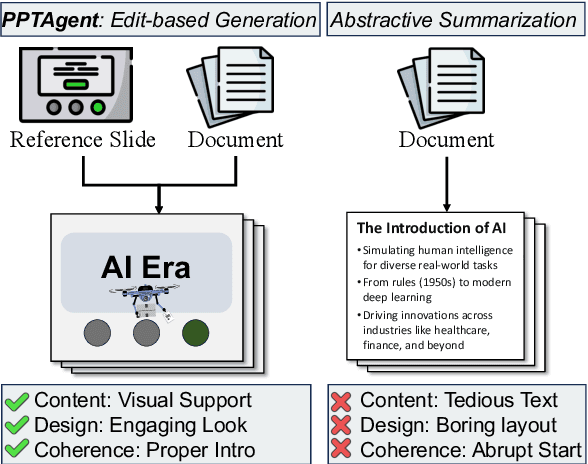

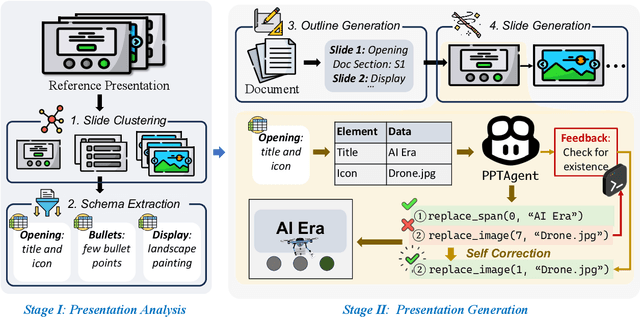
Automatically generating presentations from documents is a challenging task that requires balancing content quality, visual design, and structural coherence. Existing methods primarily focus on improving and evaluating the content quality in isolation, often overlooking visual design and structural coherence, which limits their practical applicability. To address these limitations, we propose PPTAgent, which comprehensively improves presentation generation through a two-stage, edit-based approach inspired by human workflows. PPTAgent first analyzes reference presentations to understand their structural patterns and content schemas, then drafts outlines and generates slides through code actions to ensure consistency and alignment. To comprehensively evaluate the quality of generated presentations, we further introduce PPTEval, an evaluation framework that assesses presentations across three dimensions: Content, Design, and Coherence. Experiments show that PPTAgent significantly outperforms traditional automatic presentation generation methods across all three dimensions. The code and data are available at https://github.com/icip-cas/PPTAgent.
From 2D CAD Drawings to 3D Parametric Models: A Vision-Language Approach
Dec 17, 2024



In this paper, we present CAD2Program, a new method for reconstructing 3D parametric models from 2D CAD drawings. Our proposed method is inspired by recent successes in vision-language models (VLMs), and departs from traditional methods which rely on task-specific data representations and/or algorithms. Specifically, on the input side, we simply treat the 2D CAD drawing as a raster image, regardless of its original format, and encode the image with a standard ViT model. We show that such an encoding scheme achieves competitive performance against existing methods that operate on vector-graphics inputs, while imposing substantially fewer restrictions on the 2D drawings. On the output side, our method auto-regressively predicts a general-purpose language describing 3D parametric models in text form. Compared to other sequence modeling methods for CAD which use domain-specific sequence representations with fixed-size slots, our text-based representation is more flexible, and can be easily extended to arbitrary geometric entities and semantic or functional properties. Experimental results on a large-scale dataset of cabinet models demonstrate the effectiveness of our method.
READoc: A Unified Benchmark for Realistic Document Structured Extraction
Sep 08, 2024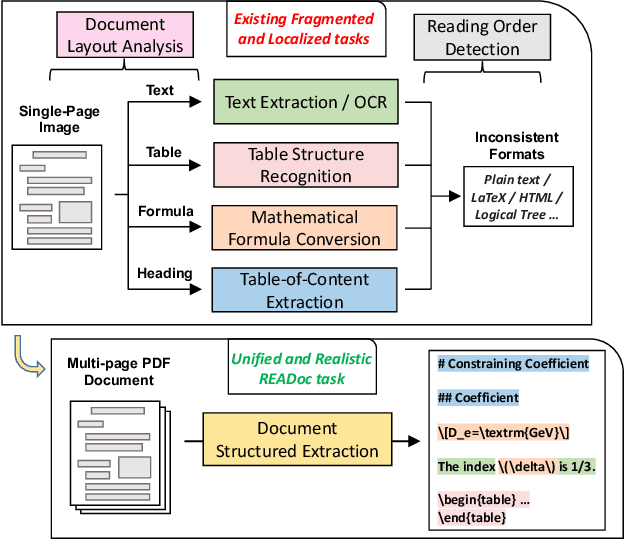


Document Structured Extraction (DSE) aims to extract structured content from raw documents. Despite the emergence of numerous DSE systems, their unified evaluation remains inadequate, significantly hindering the field's advancement. This problem is largely attributed to existing benchmark paradigms, which exhibit fragmented and localized characteristics. To address these limitations and offer a thorough evaluation of DSE systems, we introduce a novel benchmark named READoc, which defines DSE as a realistic task of converting unstructured PDFs into semantically rich Markdown. The READoc dataset is derived from 2,233 diverse and real-world documents from arXiv and GitHub. In addition, we develop a DSE Evaluation S$^3$uite comprising Standardization, Segmentation and Scoring modules, to conduct a unified evaluation of state-of-the-art DSE approaches. By evaluating a range of pipeline tools, expert visual models, and general VLMs, we identify the gap between current work and the unified, realistic DSE objective for the first time. We aspire that READoc will catalyze future research in DSE, fostering more comprehensive and practical solutions.