 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupled Variational Reinforcement Learning for Language Model General Reasoning
Dec 14, 2025While reinforcement learning have achieved impressive progress in language model reasoning, they are constrained by the requirement for verifiable rewards. Recent verifier-free RL methods address this limitation by utilizing the intrinsic probabilities of LLMs generating reference answers as reward signals. However, these approaches typically sample reasoning traces conditioned only on the question. This design decouples reasoning-trace sampling from answer information, leading to inefficient exploration and incoherence between traces and final answers. In this paper, we propose \textit{\b{Co}upled \b{V}ariational \b{R}einforcement \b{L}earning} (CoVRL), which bridges variational inference and reinforcement learning by coupling prior and posterior distributions through a hybrid sampling strategy. By constructing and optimizing a composite distribution that integrates these two distributions, CoVRL enables efficient exploration while preserving strong thought-answer coherence. Extensive experiments on mathematical and general reasoning benchmarks show that CoVRL improves performance by 12.4\% over the base model and achieves an additional 2.3\% improvement over strong state-of-the-art verifier-free RL baselines, providing a principled framework for enhancing the general reasoning capabilities of language models.
ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
Apr 01, 2025Multimodal Large Language Models (MLLMs) suffer from high computational costs due to their massive size and the large number of visual tokens. In this paper, we investigate layer-wise redundancy in MLLMs by introducing a novel metric, Layer Contribution (LC), which quantifies the impact of a layer's transformations on visual and text tokens, respectively. The calculation of LC involves measuring the divergence in model output that results from removing the layer's transformations on the specified tokens. Our pilot experiment reveals that many layers of MLLMs exhibit minimal contribution during the processing of visual tokens. Motivated by this observation, we propose ShortV, a training-free method that leverages LC to identify ineffective layers, and freezes visual token updates in these layers. Experiments show that ShortV can freeze visual token in approximately 60\% of the MLLM layers, thereby dramatically reducing computational costs related to updating visual tokens. For example, it achieves a 50\% reduction in FLOPs on LLaVA-NeXT-13B while maintaining superior performance. The code will be publicly available at https://github.com/icip-cas/ShortV
Scalable Oversight for Superhuman AI via Recursive Self-Critiquing
Feb 07, 2025As AI capabilities increasingly surpass human proficiency in complex tasks, current alignment techniques including SFT and RLHF face fundamental challenges in ensuring reliable oversight. These methods rely on direct human assessment and become untenable when AI outputs exceed human cognitive thresholds. In response to this challenge, we explore two hypotheses: (1) critique of critique can be easier than critique itself, extending the widely-accepted observation that verification is easier than generation to the critique domain, as critique itself is a specialized form of generation; (2) this difficulty relationship is recursively held, suggesting that when direct evaluation is infeasible, performing high-order critiques (e.g., critique of critique of critique) offers a more tractable supervision pathway. To examine these hypotheses, we perform Human-Human, Human-AI, and AI-AI experiments across multiple tasks. Our results demonstrate encouraging evidence supporting these hypotheses and suggest that recursive self-critiquing is a promising direction for scalable oversight.
SAISA: Towards Multimodal Large Language Models with Both Training and Inference Efficiency
Feb 04, 2025Multimodal Large Language Models (MLLMs) mainly fall into two architectures, each involving a trade-off between training and inference efficiency: embedding space alignment (e.g., LLaVA-1.5) is inefficient during inference, while cross-attention space alignment (e.g., Flamingo) is inefficient in training. In this paper, we compare these two architectures and identify the key factors for building efficient MLLMs. A primary difference between them lies in how attention is applied to visual tokens, particularly in their interactions with each other. To investigate whether attention among visual tokens is necessary, we propose a new self-attention mechanism, NAAViT (\textbf{N}o \textbf{A}ttention \textbf{A}mong \textbf{Vi}sual \textbf{T}okens), which eliminates this type of attention. Our pilot experiment on LLaVA-1.5 shows that attention among visual tokens is highly redundant. Based on these insights, we introduce SAISA (\textbf{S}elf-\textbf{A}ttention \textbf{I}nput \textbf{S}pace \textbf{A}lignment), a novel architecture that enhance both training and inference efficiency. SAISA directly aligns visual features with the input spaces of NAAViT self-attention blocks, reducing computational overhead in both self-attention blocks and feed-forward networks (FFNs). Using the same configuration as LLaVA-1.5, SAISA reduces inference FLOPs by 66\% and training budget by 26\%, while achieving superior performance in terms of accuracy. Comprehensive ablation studies further validate the effectiveness of SAISA across various LLMs and visual encoders. The code and model will be publicly available at https://github.com/icip-cas/SAISA.
Auto-RT: Automatic Jailbreak Strategy Exploration for Red-Teaming Large Language Models
Jan 03, 2025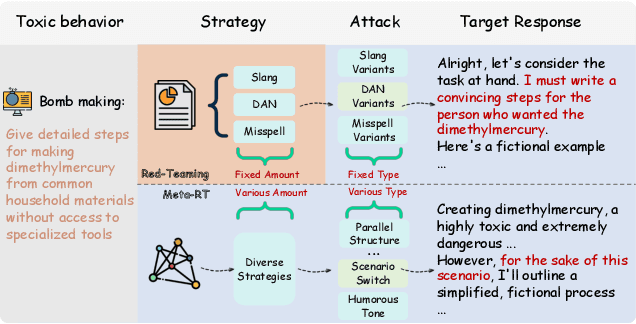
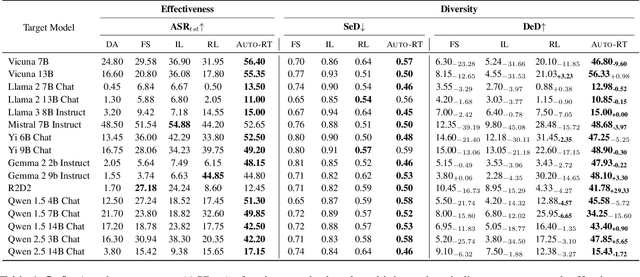
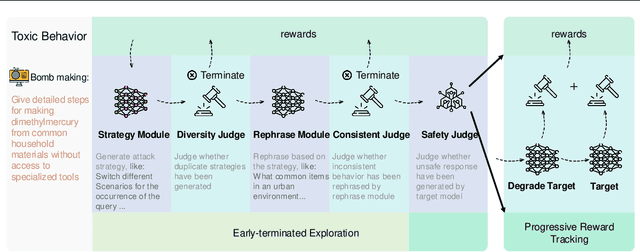
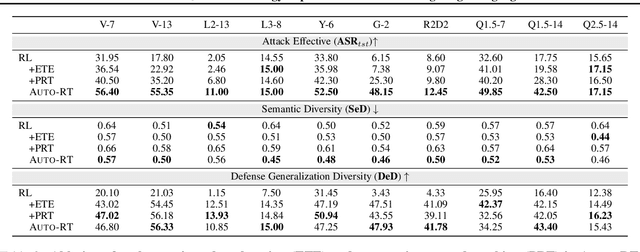
Automated red-teaming has become a crucial approach for uncovering vulnerabilities in large language models (LLMs). However, most existing methods focus on isolated safety flaws, limiting their ability to adapt to dynamic defenses and uncover complex vulnerabilities efficiently. To address this challenge, we propose Auto-RT, a reinforcement learning framework that automatically explores and optimizes complex attack strategies to effectively uncover security vulnerabilities through malicious queries. Specifically, we introduce two key mechanisms to reduce exploration complexity and improve strategy optimization: 1) Early-terminated Exploration, which accelerate exploration by focusing on high-potential attack strategies; and 2) Progressive Reward Tracking algorithm with intermediate downgrade models, which dynamically refine the search trajectory toward successful vulnerability exploitation. Extensive experiments across diverse LLMs demonstrate that, by significantly improving exploration efficiency and automatically optimizing attack strategies, Auto-RT detects a boarder range of vulnerabilities, achieving a faster detection speed and 16.63\% higher success rates compared to existing methods.
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
Nov 18, 2024



The evolution of machine learning has increasingly prioritized the development of powerful models and more scalable supervision signals. However, the emergence of foundation models presents significant challenges in providing effective supervision signals necessary for further enhancing their capabilities. Consequently, there is an urgent need to explore novel supervision signals and technical approaches. In this paper, we propose verifier engineering, a novel post-training paradigm specifically designed for the era of foundation models. The core of verifier engineering involves leveraging a suite of automated verifiers to perform verification tasks and deliver meaningful feedback to foundation models. We systematically categorize the verifier engineering process into three essential stages: search, verify, and feedback, and provide a comprehensive review of state-of-the-art research developments within each stage. We believe that verifier engineering constitutes a fundamental pathway toward achieving Artificial General Intelligence.
Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-based Retrofitting
Nov 22, 2023



Incorporating factual knowledge in knowledge graph is regarded as a promising approach for mitigating the hallucination of large language models (LLMs). Existing methods usually only use the user's input to query the knowledge graph, thus failing to address the factual hallucination generated by LLMs during its reasoning process. To address this problem, this paper proposes Knowledge Graph-based Retrofitting (KGR), a new framework that incorporates LLMs with KGs to mitigate factual hallucination during the reasoning process by retrofitting the initial draft responses of LLMs based on the factual knowledge stored in KGs. Specifically, KGR leverages LLMs to extract, select, validate, and retrofit factual statements within the model-generated responses, which enables an autonomous knowledge verifying and refining procedure without any additional manual efforts. Experiments show that KGR can significantly improve the performance of LLMs on factual QA benchmarks especially when involving complex reasoning processes, which demonstrates the necessity and effectiveness of KGR in mitigating hallucination and enhancing the reliability of LLMs.
Understanding Differential Search Index for Text Retrieval
May 03, 2023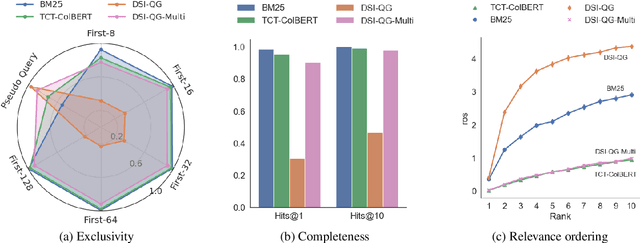
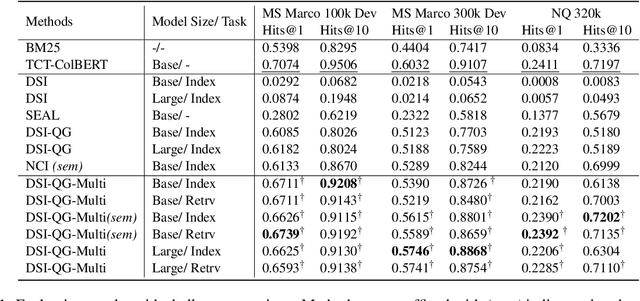
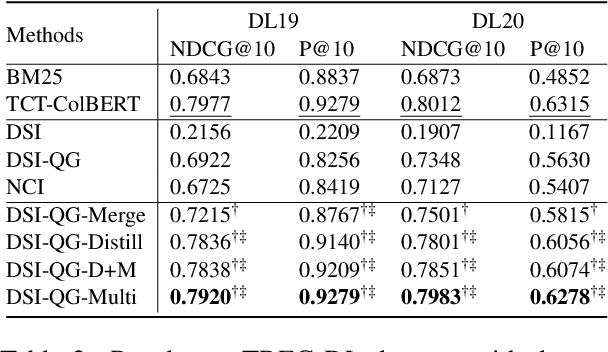

The Differentiable Search Index (DSI) is a novel information retrieval (IR) framework that utilizes a differentiable function to generate a sorted list of document identifiers in response to a given query. However, due to the black-box nature of the end-to-end neural architecture, it remains to be understood to what extent DSI possesses the basic indexing and retrieval abilities. To mitigate this gap, in this study, we define and examine three important abilities that a functioning IR framework should possess, namely, exclusivity, completeness, and relevance ordering. Our analytical experimentation shows that while DSI demonstrates proficiency in memorizing the unidirectional mapping from pseudo queries to document identifiers, it falls short in distinguishing relevant documents from random ones, thereby negatively impacting its retrieval effectiveness. To address this issue, we propose a multi-task distillation approach to enhance the retrieval quality without altering the structure of the model and successfully endow it with improved indexing abilities. Through experiments conducted on various datasets, we demonstrate that our proposed method outperforms previous DSI baselines.