 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Long Reasoning Models: An Empirical Study
Jun 05, 2025



Despite recent progress in training long-context reasoning models via reinforcement learning (RL), several open questions and counterintuitive behaviors remain. This work focuses on three key aspects: (1) We systematically analyze the roles of positive and negative samples in RL, revealing that positive samples mainly facilitate data fitting, whereas negative samples significantly enhance generalization and robustness. Interestingly, training solely on negative samples can rival standard RL training performance. (2) We identify substantial data inefficiency in group relative policy optimization, where over half of the samples yield zero advantage. To address this, we explore two straightforward strategies, including relative length rewards and offline sample injection, to better leverage these data and enhance reasoning efficiency and capability. (3) We investigate unstable performance across various reasoning models and benchmarks, attributing instability to uncertain problems with ambiguous outcomes, and demonstrate that multiple evaluation runs mitigate this issue.
DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Feb 03, 2025



Large Language Models (LLMs) have shown remarkable potential in reasoning while they still suffer from severe factual hallucinations due to timeliness, accuracy, and coverage of parametric knowledge. Meanwhile, integrating reasoning with retrieval-augmented generation (RAG) remains challenging due to ineffective task decomposition and redundant retrieval, which can introduce noise and degrade response quality. In this paper, we propose DeepRAG, a framework that models retrieval-augmented reasoning as a Markov Decision Process (MDP), enabling strategic and adaptive retrieval. By iteratively decomposing queries, DeepRAG dynamically determines whether to retrieve external knowledge or rely on parametric reasoning at each step. Experiments show that DeepRAG improves retrieval efficiency while improving answer accuracy by 21.99%, demonstrating its effectiveness in optimizing retrieval-augmented reasoning.
PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
Jan 07, 2025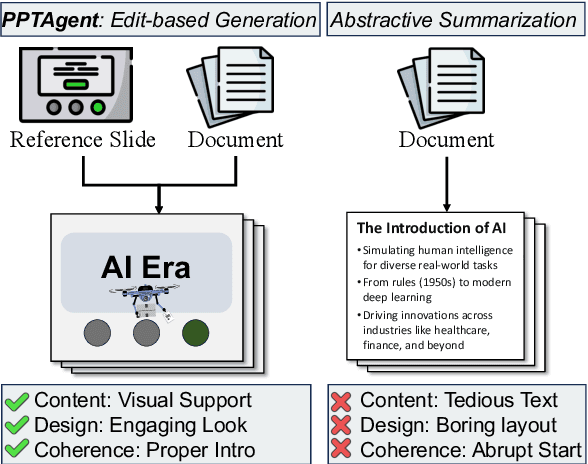

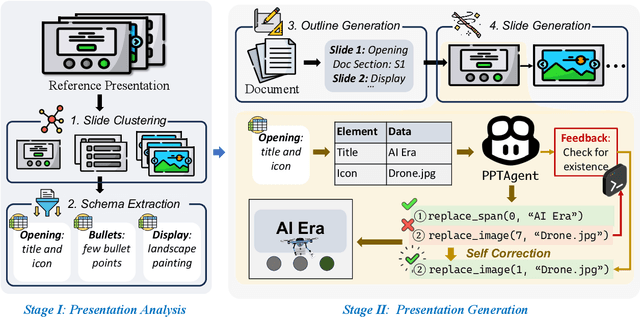
Automatically generating presentations from documents is a challenging task that requires balancing content quality, visual design, and structural coherence. Existing methods primarily focus on improving and evaluating the content quality in isolation, often overlooking visual design and structural coherence, which limits their practical applicability. To address these limitations, we propose PPTAgent, which comprehensively improves presentation generation through a two-stage, edit-based approach inspired by human workflows. PPTAgent first analyzes reference presentations to understand their structural patterns and content schemas, then drafts outlines and generates slides through code actions to ensure consistency and alignment. To comprehensively evaluate the quality of generated presentations, we further introduce PPTEval, an evaluation framework that assesses presentations across three dimensions: Content, Design, and Coherence. Experiments show that PPTAgent significantly outperforms traditional automatic presentation generation methods across all three dimensions. The code and data are available at https://github.com/icip-cas/PPTAgent.
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
Nov 18, 2024



The evolution of machine learning has increasingly prioritized the development of powerful models and more scalable supervision signals. However, the emergence of foundation models presents significant challenges in providing effective supervision signals necessary for further enhancing their capabilities. Consequently, there is an urgent need to explore novel supervision signals and technical approaches. In this paper, we propose verifier engineering, a novel post-training paradigm specifically designed for the era of foundation models. The core of verifier engineering involves leveraging a suite of automated verifiers to perform verification tasks and deliver meaningful feedback to foundation models. We systematically categorize the verifier engineering process into three essential stages: search, verify, and feedback, and provide a comprehensive review of state-of-the-art research developments within each stage. We believe that verifier engineering constitutes a fundamental pathway toward achieving Artificial General Intelligence.
REInstruct: Building Instruction Data from Unlabeled Corpus
Aug 20, 2024



Manually annotating instruction data for large language models is difficult, costly, and hard to scale. Meanwhile, current automatic annotation methods typically rely on distilling synthetic data from proprietary LLMs, which not only limits the upper bound of the quality of the instruction data but also raises potential copyright issues. In this paper, we propose REInstruct, a simple and scalable method to automatically build instruction data from an unlabeled corpus without heavy reliance on proprietary LLMs and human annotation. Specifically, REInstruct first selects a subset of unlabeled texts that potentially contain well-structured helpful and insightful content and then generates instructions for these texts. To generate accurate and relevant responses for effective and robust training, REInstruct further proposes a rewriting-based approach to improve the quality of the generated instruction data. By training Llama-7b on a combination of 3k seed data and 32k synthetic data from REInstruct, fine-tuned model achieves a 65.41\% win rate on AlpacaEval leaderboard against text-davinci-003, outperforming other open-source, non-distilled instruction data construction methods. The code is publicly available at \url{https://github.com/cs32963/REInstruct}.
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation
Jun 18, 2024



Hallucination occurs when large language models (LLMs) exhibit behavior that deviates from the boundaries of their knowledge during the response generation process. Previous learning-based methods focus on detecting knowledge boundaries and finetuning models with instance-level feedback, but they suffer from inaccurate signals due to off-policy data sampling and coarse-grained feedback. In this paper, we introduce \textit{\b{R}einforcement \b{L}earning \b{f}or \b{H}allucination} (RLFH), a fine-grained feedback-based online reinforcement learning method for hallucination mitigation. Unlike previous learning-based methods, RLFH enables LLMs to explore the boundaries of their internal knowledge and provide on-policy, fine-grained feedback on these explorations. To construct fine-grained feedback for learning reliable generation behavior, RLFH decomposes the outcomes of large models into atomic facts, provides statement-level evaluation signals, and traces back the signals to the tokens of the original responses. Finally, RLFH adopts the online reinforcement algorithm with these token-level rewards to adjust model behavior for hallucination mitigation. For effective on-policy optimization, RLFH also introduces an LLM-based fact assessment framework to verify the truthfulness and helpfulness of atomic facts without human intervention. Experiments on HotpotQA, SQuADv2, and Biography benchmarks demonstrate that RLFH can balance their usage of internal knowledge during the generation process to eliminate the hallucination behavior of LLMs.
Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-based Retrofitting
Nov 22, 2023



Incorporating factual knowledge in knowledge graph is regarded as a promising approach for mitigating the hallucination of large language models (LLMs). Existing methods usually only use the user's input to query the knowledge graph, thus failing to address the factual hallucination generated by LLMs during its reasoning process. To address this problem, this paper proposes Knowledge Graph-based Retrofitting (KGR), a new framework that incorporates LLMs with KGs to mitigate factual hallucination during the reasoning process by retrofitting the initial draft responses of LLMs based on the factual knowledge stored in KGs. Specifically, KGR leverages LLMs to extract, select, validate, and retrofit factual statements within the model-generated responses, which enables an autonomous knowledge verifying and refining procedure without any additional manual efforts. Experiments show that KGR can significantly improve the performance of LLMs on factual QA benchmarks especially when involving complex reasoning processes, which demonstrates the necessity and effectiveness of KGR in mitigating hallucination and enhancing the reliability of LLMs.
DLUE: Benchmarking Document Language Understanding
May 16, 2023



Understanding documents is central to many real-world tasks but remains a challenging topic. Unfortunately, there is no well-established consensus on how to comprehensively evaluate document understanding abilities, which significantly hinders the fair comparison and measuring the progress of the field. To benchmark document understanding researches, this paper summarizes four representative abilities, i.e., document classification, document structural analysis, document information extraction, and document transcription. Under the new evaluation framework, we propose \textbf{Document Language Understanding Evaluation} -- \textbf{DLUE}, a new task suite which covers a wide-range of tasks in various forms, domains and document genres. We also systematically evaluate six well-established transformer models on DLUE, and find that due to the lengthy content, complicated underlying structure and dispersed knowledge, document understanding is still far from being solved, and currently there is no neural architecture that dominates all tasks, raising requirements for a universal document understanding architecture.
Improving Temporal Generalization of Pre-trained Language Models with Lexical Semantic Change
Oct 31, 2022Recent research has revealed that neural language models at scale suffer from poor temporal generalization capability, i.e., the language model pre-trained on static data from past years performs worse over time on emerging data. Existing methods mainly perform continual training to mitigate such a misalignment. While effective to some extent but is far from being addressed on both the language modeling and downstream tasks. In this paper, we empirically observe that temporal generalization is closely affiliated with lexical semantic change, which is one of the essential phenomena of natural languages. Based on this observation, we propose a simple yet effective lexical-level masking strategy to post-train a converged language model. Experiments on two pre-trained language models, two different classification tasks, and four benchmark datasets demonstrate the effectiveness of our proposed method over existing temporal adaptation methods, i.e., continual training with new data. Our code is available at \url{https://github.com/zhaochen0110/LMLM}.