 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
Nov 15, 2025Goal-driven persuasive dialogue, exemplified by applications like telemarketing, requires sophisticated multi-turn planning and strict factual faithfulness, which remains a significant challenge for even state-of-the-art Large Language Models (LLMs). A lack of task-specific data often limits previous works, and direct LLM application suffers from strategic brittleness and factual hallucination. In this paper, we first construct and release TeleSalesCorpus, the first real-world-grounded dialogue dataset for this domain. We then propose AI-Salesman, a novel framework featuring a dual-stage architecture. For the training stage, we design a Bayesian-supervised reinforcement learning algorithm that learns robust sales strategies from noisy dialogues. For the inference stage, we introduce the Dynamic Outline-Guided Agent (DOGA), which leverages a pre-built script library to provide dynamic, turn-by-turn strategic guidance. Moreover, we design a comprehensive evaluation framework that combines fine-grained metrics for key sales skills with the LLM-as-a-Judge paradigm. Experimental results demonstrate that our proposed AI-Salesman significantly outperforms baseline models in both automatic metrics and comprehensive human evaluations, showcasing its effectiveness in complex persuasive scenarios.
DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Feb 03, 2025



Large Language Models (LLMs) have shown remarkable potential in reasoning while they still suffer from severe factual hallucinations due to timeliness, accuracy, and coverage of parametric knowledge. Meanwhile, integrating reasoning with retrieval-augmented generation (RAG) remains challenging due to ineffective task decomposition and redundant retrieval, which can introduce noise and degrade response quality. In this paper, we propose DeepRAG, a framework that models retrieval-augmented reasoning as a Markov Decision Process (MDP), enabling strategic and adaptive retrieval. By iteratively decomposing queries, DeepRAG dynamically determines whether to retrieve external knowledge or rely on parametric reasoning at each step. Experiments show that DeepRAG improves retrieval efficiency while improving answer accuracy by 21.99%, demonstrating its effectiveness in optimizing retrieval-augmented reasoning.
Semantic-aware Contrastive Learning for More Accurate Semantic Parsing
Jan 19, 2023



Since the meaning representations are detailed and accurate annotations which express fine-grained sequence-level semtantics, it is usually hard to train discriminative semantic parsers via Maximum Likelihood Estimation (MLE) in an autoregressive fashion. In this paper, we propose a semantic-aware contrastive learning algorithm, which can learn to distinguish fine-grained meaning representations and take the overall sequence-level semantic into consideration. Specifically, a multi-level online sampling algorithm is proposed to sample confusing and diverse instances. Three semantic-aware similarity functions are designed to accurately measure the distance between meaning representations as a whole. And a ranked contrastive loss is proposed to pull the representations of the semantic-identical instances together and push negative instances away. Experiments on two standard datasets show that our approach achieves significant improvements over MLE baselines and gets state-of-the-art performances by simply applying semantic-aware contrastive learning on a vanilla Seq2Seq model.
From Paraphrasing to Semantic Parsing: Unsupervised Semantic Parsing via Synchronous Semantic Decoding
Jun 11, 2021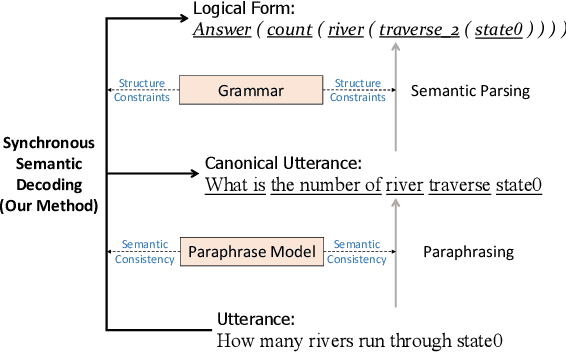
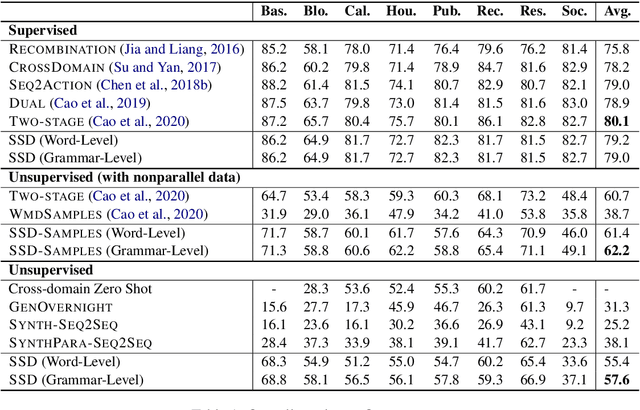
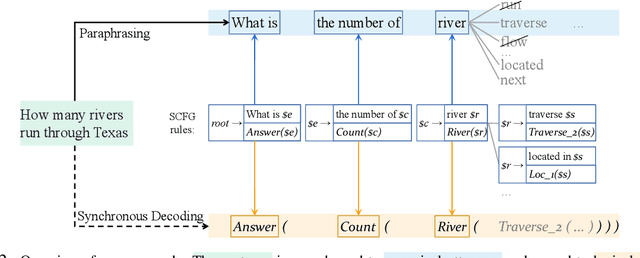
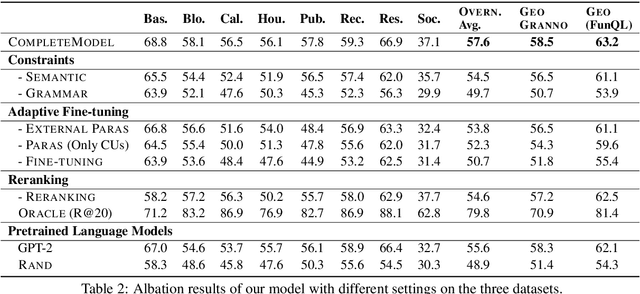
Semantic parsing is challenging due to the structure gap and the semantic gap between utterances and logical forms. In this paper, we propose an unsupervised semantic parsing method - Synchronous Semantic Decoding (SSD), which can simultaneously resolve the semantic gap and the structure gap by jointly leveraging paraphrasing and grammar constrained decoding. Specifically, we reformulate semantic parsing as a constrained paraphrasing problem: given an utterance, our model synchronously generates its canonical utterance and meaning representation. During synchronous decoding: the utterance paraphrasing is constrained by the structure of the logical form, therefore the canonical utterance can be paraphrased controlledly; the semantic decoding is guided by the semantics of the canonical utterance, therefore its logical form can be generated unsupervisedly. Experimental results show that SSD is a promising approach and can achieve competitive unsupervised semantic parsing performance on multiple datasets.