 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Exploration-Aware Fine-Tuning for Long-Chain Mathematical Reasoning
Mar 17, 2026Through encouraging self-exploration, reinforcement learning from verifiable rewards (RLVR) has significantly advanced the mathematical reasoning capabilities of large language models. As the starting point for RLVR, the capacity of supervised fine-tuning (SFT) to memorize new chain-of-thought trajectories provides a crucial initialization that shapes the subsequent exploration landscape. However, existing research primarily focuses on facilitating exploration during RLVR training, leaving exploration-aware SFT under-explored. To bridge this gap, we propose Offline eXploration-Aware (OXA) fine-tuning. Specifically, OXA optimizes two objectives: promoting low-confidence verified teacher-distillation data to internalize previously uncaptured reasoning patterns, and suppressing high-confidence incorrect self-distillation data to redistribute probability mass of incorrect patterns toward potentially correct candidates. Experimental results across 6 benchmarks show that OXA consistently improves mathematical reasoning performance, especially achieving an average gain of $+6$ Pass@1 and $+5$ Pass@$k$ points compared to conventional SFT on the Qwen2.5-1.5B-Math. Crucially, OXA elevates initial policy entropy, and performance gains persist throughout extensive RLVR training, demonstrating the long-term value of OXA.
Dissecting Long Reasoning Models: An Empirical Study
Jun 05, 2025



Despite recent progress in training long-context reasoning models via reinforcement learning (RL), several open questions and counterintuitive behaviors remain. This work focuses on three key aspects: (1) We systematically analyze the roles of positive and negative samples in RL, revealing that positive samples mainly facilitate data fitting, whereas negative samples significantly enhance generalization and robustness. Interestingly, training solely on negative samples can rival standard RL training performance. (2) We identify substantial data inefficiency in group relative policy optimization, where over half of the samples yield zero advantage. To address this, we explore two straightforward strategies, including relative length rewards and offline sample injection, to better leverage these data and enhance reasoning efficiency and capability. (3) We investigate unstable performance across various reasoning models and benchmarks, attributing instability to uncertain problems with ambiguous outcomes, and demonstrate that multiple evaluation runs mitigate this issue.
ConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.
LongDPO: Unlock Better Long-form Generation Abilities for LLMs via Critique-augmented Stepwise Information
Feb 04, 2025



Long-form generation is crucial for academic writing papers and repo-level code generation. Despite this, current models, including GPT-4o, still exhibit unsatisfactory performance. Existing methods that utilize preference learning with outcome supervision often fail to provide detailed feedback for extended contexts. This shortcoming can lead to content that does not fully satisfy query requirements, resulting in issues like length deviations, and diminished quality. In this paper, we propose enhancing long-form generation by incorporating process supervision. We employ Monte Carlo Tree Search to gather stepwise preference pairs, utilizing a global memory pool to maintain consistency. To address the issue of suboptimal candidate selection, we integrate external critiques to refine and improve the quality of the preference pairs. Finally, we apply step-level DPO using the collected stepwise preference pairs. Experimental results show that our method improves length and quality on long-form generation benchmarks, with almost lossless performance on general benchmarks across various model backbones.
DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Feb 03, 2025



Large Language Models (LLMs) have shown remarkable potential in reasoning while they still suffer from severe factual hallucinations due to timeliness, accuracy, and coverage of parametric knowledge. Meanwhile, integrating reasoning with retrieval-augmented generation (RAG) remains challenging due to ineffective task decomposition and redundant retrieval, which can introduce noise and degrade response quality. In this paper, we propose DeepRAG, a framework that models retrieval-augmented reasoning as a Markov Decision Process (MDP), enabling strategic and adaptive retrieval. By iteratively decomposing queries, DeepRAG dynamically determines whether to retrieve external knowledge or rely on parametric reasoning at each step. Experiments show that DeepRAG improves retrieval efficiency while improving answer accuracy by 21.99%, demonstrating its effectiveness in optimizing retrieval-augmented reasoning.
DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
Oct 10, 2024



Large language models (LLMs) have achieved reasonable quality improvements in machine translation (MT). However, most current research on MT-LLMs still faces significant challenges in maintaining translation consistency and accuracy when processing entire documents. In this paper, we introduce DelTA, a Document-levEL Translation Agent designed to overcome these limitations. DelTA features a multi-level memory structure that stores information across various granularities and spans, including Proper Noun Records, Bilingual Summary, Long-Term Memory, and Short-Term Memory, which are continuously retrieved and updated by auxiliary LLM-based components. Experimental results indicate that DelTA significantly outperforms strong baselines in terms of translation consistency and quality across four open/closed-source LLMs and two representative document translation datasets, achieving an increase in consistency scores by up to 4.58 percentage points and in COMET scores by up to 3.16 points on average. DelTA employs a sentence-by-sentence translation strategy, ensuring no sentence omissions and offering a memory-efficient solution compared to the mainstream method. Furthermore, DelTA improves pronoun translation accuracy, and the summary component of the agent also shows promise as a tool for query-based summarization tasks. We release our code and data at https://github.com/YutongWang1216/DocMTAgent.
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Jun 12, 2024
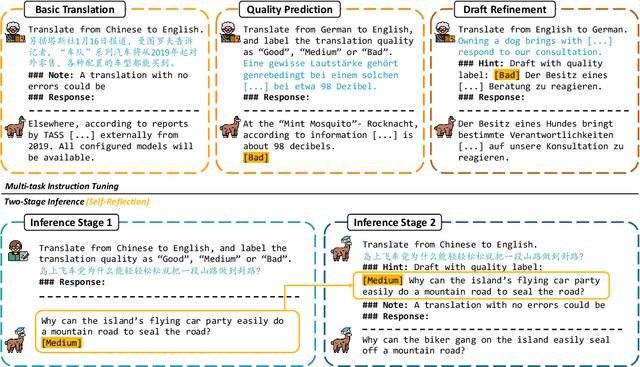
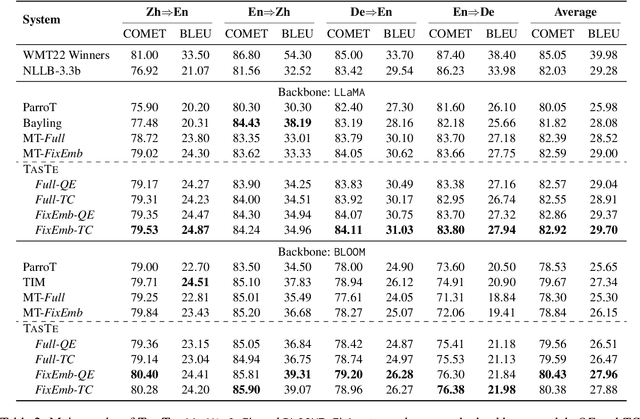
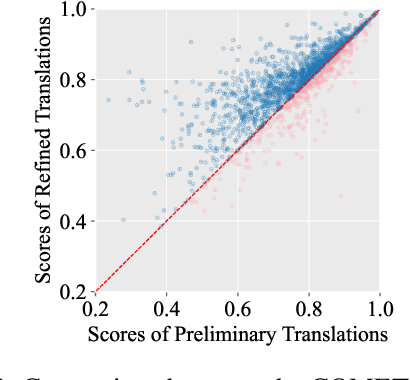
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
LexMatcher: Dictionary-centric Data Collection for LLM-based Machine Translation
Jun 03, 2024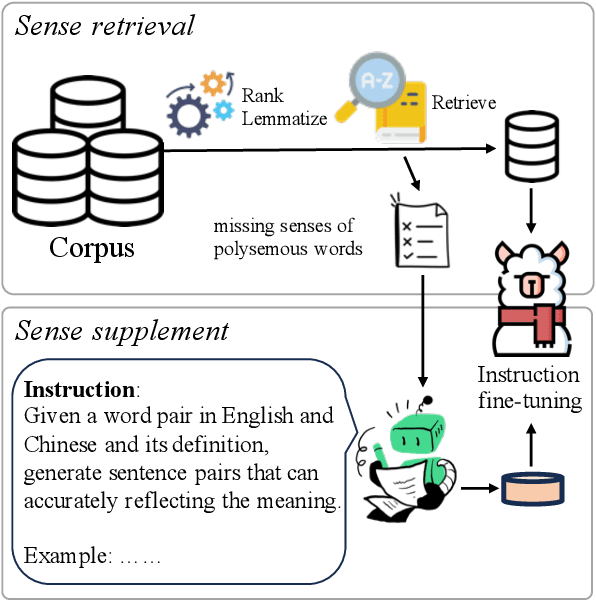
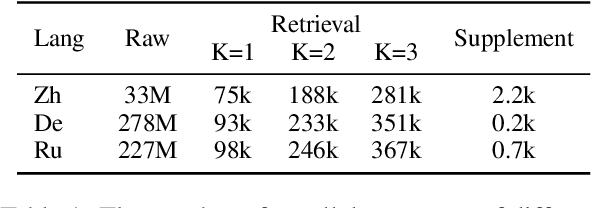
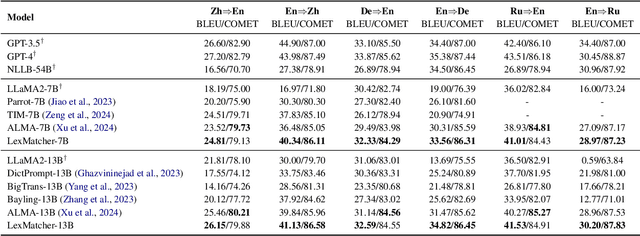
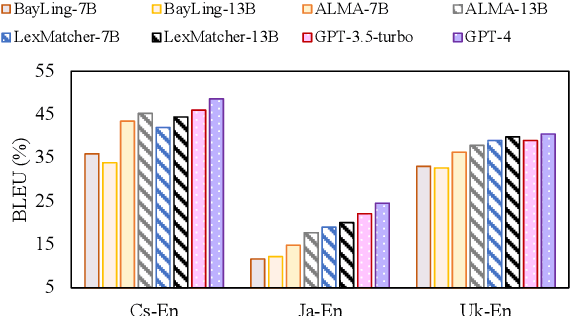
The fine-tuning of open-source large language models (LLMs) for machine translation has recently received considerable attention, marking a shift towards data-centric research from traditional neural machine translation. However, the area of data collection for instruction fine-tuning in machine translation remains relatively underexplored. In this paper, we present LexMatcher, a simple yet effective method for data collection that leverages bilingual dictionaries to generate a dataset, the design of which is driven by the coverage of senses found in these dictionaries. The dataset comprises a subset retrieved from an existing corpus and a smaller synthesized subset which supplements the infrequent senses of polysemous words. Utilizing LLaMA2 as our base model, our approach outperforms the established baselines on the WMT2022 test sets and also exhibits significant performance improvements in tasks related to word sense disambiguation and specialized terminology translation. These results underscore the effectiveness of LexMatcher in enhancing LLM-based machine translation.
Understanding and Addressing the Under-Translation Problem from the Perspective of Decoding Objective
May 29, 2024Neural Machine Translation (NMT) has made remarkable progress over the past years. However, under-translation and over-translation remain two challenging problems in state-of-the-art NMT systems. In this work, we conduct an in-depth analysis on the underlying cause of under-translation in NMT, providing an explanation from the perspective of decoding objective. To optimize the beam search objective, the model tends to overlook words it is less confident about, leading to the under-translation phenomenon. Correspondingly, the model's confidence in predicting the End Of Sentence (EOS) diminishes when under-translation occurs, serving as a mild penalty for under-translated candidates. Building upon this analysis, we propose employing the confidence of predicting EOS as a detector for under-translation, and strengthening the confidence-based penalty to penalize candidates with a high risk of under-translation. Experiments on both synthetic and real-world data show that our method can accurately detect and rectify under-translated outputs, with minor impact on other correct translations.
Generative Multi-Modal Knowledge Retrieval with Large Language Models
Jan 16, 2024



Knowledge retrieval with multi-modal queries plays a crucial role in supporting knowledge-intensive multi-modal applications. However, existing methods face challenges in terms of their effectiveness and training efficiency, especially when it comes to training and integrating multiple retrievers to handle multi-modal queries. In this paper, we propose an innovative end-to-end generative framework for multi-modal knowledge retrieval. Our framework takes advantage of the fact that large language models (LLMs) can effectively serve as virtual knowledge bases, even when trained with limited data. We retrieve knowledge via a two-step process: 1) generating knowledge clues related to the queries, and 2) obtaining the relevant document by searching databases using the knowledge clue. In particular, we first introduce an object-aware prefix-tuning technique to guide multi-grained visual learning. Then, we align multi-grained visual features into the textual feature space of the LLM, employing the LLM to capture cross-modal interactions. Subsequently, we construct instruction data with a unified format for model training. Finally, we propose the knowledge-guided generation strategy to impose prior constraints in the decoding steps, thereby promoting the generation of distinctive knowledge clues. Through experiments conducted on three benchmarks, we demonstrate significant improvements ranging from 3.0% to 14.6% across all evaluation metrics when compared to strong baselines.