 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.
AugFL: Augmenting Federated Learning with Pretrained Models
Mar 04, 2025Federated Learning (FL) has garnered widespread interest in recent years. However, owing to strict privacy policies or limited storage capacities of training participants such as IoT devices, its effective deployment is often impeded by the scarcity of training data in practical decentralized learning environments. In this paper, we study enhancing FL with the aid of (large) pre-trained models (PMs), that encapsulate wealthy general/domain-agnostic knowledge, to alleviate the data requirement in conducting FL from scratch. Specifically, we consider a networked FL system formed by a central server and distributed clients. First, we formulate the PM-aided personalized FL as a regularization-based federated meta-learning problem, where clients join forces to learn a meta-model with knowledge transferred from a private PM stored at the server. Then, we develop an inexact-ADMM-based algorithm, AugFL, to optimize the problem with no need to expose the PM or incur additional computational costs to local clients. Further, we establish theoretical guarantees for AugFL in terms of communication complexity, adaptation performance, and the benefit of knowledge transfer in general non-convex cases. Extensive experiments corroborate the efficacy and superiority of AugFL over existing baselines.
LeMo: Enabling LEss Token Involvement for MOre Context Fine-tuning
Jan 15, 2025



The escalating demand for long-context applications has intensified the necessity of extending the LLM context windows. Despite recent fine-tuning approaches successfully expanding context lengths, their high memory footprints, especially for activations, present a critical practical limitation. Current parameter-efficient fine-tuning methods prioritize reducing parameter update overhead over addressing activation memory constraints. Similarly, existing sparsity mechanisms improve computational efficiency but overlook activation memory optimization due to the phenomenon of Shadowy Activation. In this paper, we propose LeMo, the first LLM fine-tuning system that explores and exploits a new token-level sparsity mechanism inherent in long-context scenarios, termed Contextual Token Sparsity. LeMo minimizes redundant token involvement by assessing the informativeness of token embeddings while preserving model accuracy. Specifically, LeMo introduces three key techniques: (1) Token Elimination, dynamically identifying and excluding redundant tokens across varying inputs and layers. (2) Pattern Prediction, utilizing well-trained predictors to approximate token sparsity patterns with minimal overhead. (3) Kernel Optimization, employing permutation-free and segment-based strategies to boost system performance. We implement LeMo as an end-to-end fine-tuning system compatible with various LLM architectures and other optimization techniques. Comprehensive evaluations demonstrate that LeMo reduces memory consumption by up to 1.93x and achieves up to 1.36x speedups, outperforming state-of-the-art fine-tuning systems.
Enabling Cardiac Monitoring using In-ear Ballistocardiogram on COTS Wireless Earbuds
Jan 12, 2025The human ear offers a unique opportunity for cardiac monitoring due to its physiological and practical advantages. However, existing earable solutions require additional hardware and complex processing, posing challenges for commercial True Wireless Stereo (TWS) earbuds which are limited by their form factor and resources. In this paper, we propose TWSCardio, a novel system that repurposes the IMU sensors in TWS earbuds for cardiac monitoring. Our key finding is that these sensors can capture in-ear ballistocardiogram (BCG) signals. TWSCardio reuses the unstable Bluetooth channel to stream the IMU data to a smartphone for BCG processing. It incorporates a signal enhancement framework to address issues related to missing data and low sampling rate, while mitigating motion artifacts by fusing multi-axis information. Furthermore, it employs a region-focused signal reconstruction method to translate the multi-axis in-ear BCG signals into fine-grained seismocardiogram (SCG) signals. We have implemented TWSCardio as an efficient real-time app. Our experiments on 100 subjects verify that TWSCardio can accurately reconstruct cardiac signals while showing resilience to motion artifacts, missing data, and low sampling rates. Our case studies further demonstrate that TWSCardio can support diverse cardiac monitoring applications.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
ShotVL: Human-Centric Highlight Frame Retrieval via Language Queries
Dec 17, 2024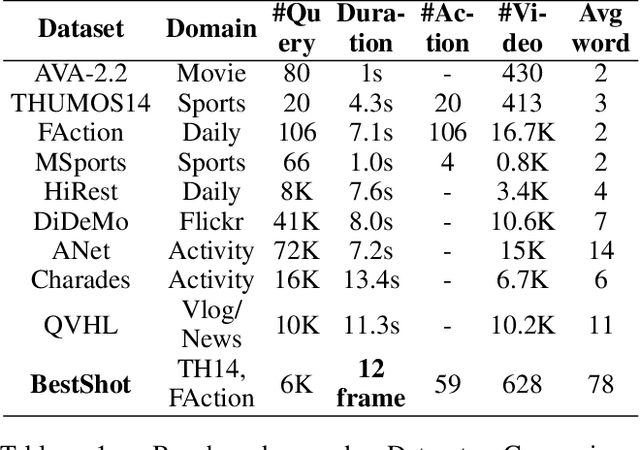

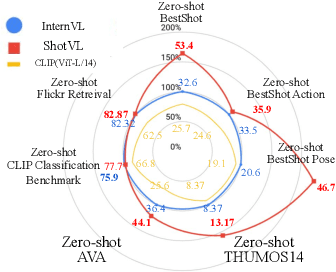
Existing works on human-centric video understanding typically focus on analyzing specific moment or entire videos. However, many applications require higher precision at the frame level. In this work, we propose a novel task, BestShot, which aims to locate highlight frames within human-centric videos via language queries. This task demands not only a deep semantic comprehension of human actions but also precise temporal localization. To support this task, we introduce the BestShot Benchmark. %The benchmark is meticulously constructed by combining human detection and tracking, potential frame selection based on human judgment, and detailed textual descriptions crafted by human input to ensure precision. The benchmark is meticulously constructed by combining human-annotated highlight frames, detailed textual descriptions and duration labeling. These descriptions encompass three critical elements: (1) Visual content; (2) Fine-grained action; and (3) Human Pose Description. Together, these elements provide the necessary precision to identify the exact highlight frames in videos. To tackle this problem, we have collected two distinct datasets: (i) ShotGPT4o Dataset, which is algorithmically generated by GPT-4o and (ii) Image-SMPLText Dataset, a dataset with large-scale and accurate per-frame pose description leveraging PoseScript and existing pose estimation datasets. Based on these datasets, we present a strong baseline model, ShotVL, fine-tuned from InternVL, specifically for BestShot. We highlight the impressive zero-shot capabilities of our model and offer comparative analyses with existing SOTA models. ShotVL demonstrates a significant 52% improvement over InternVL on the BestShot Benchmark and a notable 57% improvement on the THUMOS14 Benchmark, all while maintaining the SOTA performance in general image classification and retrieval.
EdgeOAR: Real-time Online Action Recognition On Edge Devices
Dec 02, 2024



This paper addresses the challenges of Online Action Recognition (OAR), a framework that involves instantaneous analysis and classification of behaviors in video streams. OAR must operate under stringent latency constraints, making it an indispensable component for real-time feedback for edge computing. Existing methods, which typically rely on the processing of entire video clips, fall short in scenarios requiring immediate recognition. To address this, we designed EdgeOAR, a novel framework specifically designed for OAR on edge devices. EdgeOAR includes the Early Exit-oriented Task-specific Feature Enhancement Module (TFEM), which comprises lightweight submodules to optimize features in both temporal and spatial dimensions. We design an iterative training method to enable TFEM learning features from the beginning of the video. Additionally, EdgeOAR includes an Inverse Information Entropy (IIE) and Modality Consistency (MC)-driven fusion module to fuse features and make better exit decisions. This design overcomes the two main challenges: robust modeling of spatio-temporal action representations with limited initial frames in online video streams and balancing accuracy and efficiency on resource-constrained edge devices. Experiments show that on the UCF-101 dataset, our method EdgeOAR reduces latency by 99.23% and energy consumption by 99.28% compared to state-of-the-art (SOTA) method. And achieves an adequate accuracy on edge devices.
Ripple: Accelerating LLM Inference on Smartphones with Correlation-Aware Neuron Management
Oct 29, 2024



Large Language Models (LLMs) have achieved remarkable success across various domains, yet deploying them on mobile devices remains an arduous challenge due to their extensive computational and memory demands. While lightweight LLMs have been developed to fit mobile environments, they suffer from degraded model accuracy. In contrast, sparsity-based techniques minimize DRAM usage by selectively transferring only relevant neurons to DRAM while retaining the full model in external storage, such as flash. However, such approaches are critically limited by numerous I/O operations, particularly on smartphones with severe IOPS constraints. In this paper, we propose Ripple, a novel approach that accelerates LLM inference on smartphones by optimizing neuron placement in flash memory. Ripple leverages the concept of Neuron Co-Activation, where neurons frequently activated together are linked to facilitate continuous read access and optimize data transfer efficiency. Our approach incorporates a two-stage solution: an offline stage that reorganizes neuron placement based on co-activation patterns, and an online stage that employs tailored data access and caching strategies to align well with hardware characteristics. Evaluations conducted on a variety of smartphones and LLMs demonstrate that Ripple achieves up to 5.93x improvements in I/O latency compared to the state-of-the-art. As the first solution to optimize storage placement under sparsity, Ripple explores a new optimization space at the intersection of sparsity-driven algorithm and storage-level system co-design in LLM inference.
How to Leverage Diverse Demonstrations in Offline Imitation Learning
May 29, 2024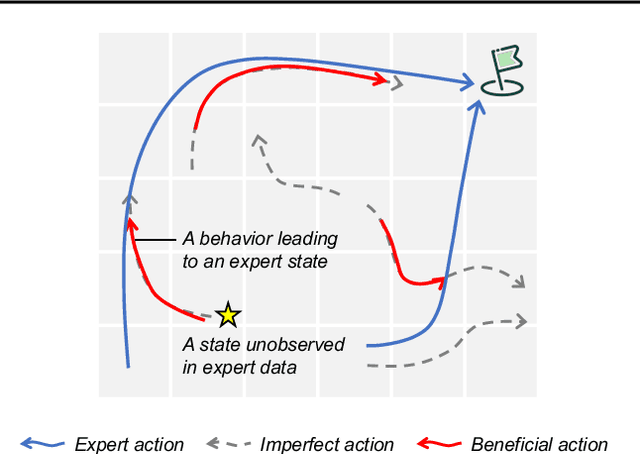
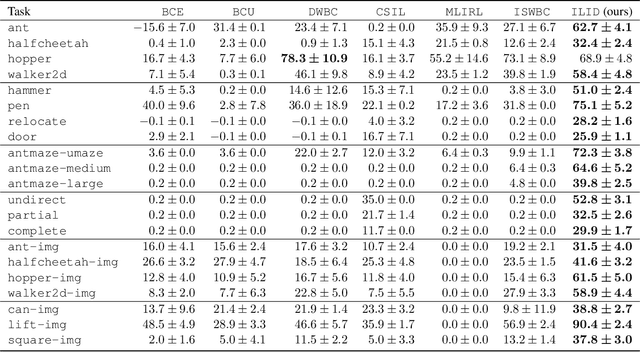
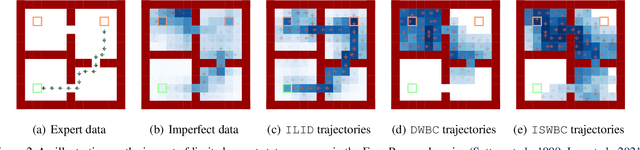
Offline Imitation Learning (IL) with imperfect demonstrations has garnered increasing attention owing to the scarcity of expert data in many real-world domains. A fundamental problem in this scenario is how to extract positive behaviors from noisy data. In general, current approaches to the problem select data building on state-action similarity to given expert demonstrations, neglecting precious information in (potentially abundant) $\textit{diverse}$ state-actions that deviate from expert ones. In this paper, we introduce a simple yet effective data selection method that identifies positive behaviors based on their resultant states -- a more informative criterion enabling explicit utilization of dynamics information and effective extraction of both expert and beneficial diverse behaviors. Further, we devise a lightweight behavior cloning algorithm capable of leveraging the expert and selected data correctly. In the experiments, we evaluate our method on a suite of complex and high-dimensional offline IL benchmarks, including continuous-control and vision-based tasks. The results demonstrate that our method achieves state-of-the-art performance, outperforming existing methods on $\textbf{20/21}$ benchmarks, typically by $\textbf{2-5x}$, while maintaining a comparable runtime to Behavior Cloning ($\texttt{BC}$).
OLLIE: Imitation Learning from Offline Pretraining to Online Finetuning
May 29, 2024



In this paper, we study offline-to-online Imitation Learning (IL) that pretrains an imitation policy from static demonstration data, followed by fast finetuning with minimal environmental interaction. We find the na\"ive combination of existing offline IL and online IL methods tends to behave poorly in this context, because the initial discriminator (often used in online IL) operates randomly and discordantly against the policy initialization, leading to misguided policy optimization and $\textit{unlearning}$ of pretraining knowledge. To overcome this challenge, we propose a principled offline-to-online IL method, named $\texttt{OLLIE}$, that simultaneously learns a near-expert policy initialization along with an $\textit{aligned discriminator initialization}$, which can be seamlessly integrated into online IL, achieving smooth and fast finetuning. Empirically, $\texttt{OLLIE}$ consistently and significantly outperforms the baseline methods in $\textbf{20}$ challenging tasks, from continuous control to vision-based domains, in terms of performance, demonstration efficiency, and convergence speed. This work may serve as a foundation for further exploration of pretraining and finetuning in the context of IL.