 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaRCA: Multi-Agent Reinforcement Learning for Dynamic Computation Allocation in Large-Scale Recommender Systems
Dec 30, 2025Modern recommender systems face significant computational challenges due to growing model complexity and traffic scale, making efficient computation allocation critical for maximizing business revenue. Existing approaches typically simplify multi-stage computation resource allocation, neglecting inter-stage dependencies, thus limiting global optimality. In this paper, we propose MaRCA, a multi-agent reinforcement learning framework for end-to-end computation resource allocation in large-scale recommender systems. MaRCA models the stages of a recommender system as cooperative agents, using Centralized Training with Decentralized Execution (CTDE) to optimize revenue under computation resource constraints. We introduce an AutoBucket TestBench for accurate computation cost estimation, and a Model Predictive Control (MPC)-based Revenue-Cost Balancer to proactively forecast traffic loads and adjust the revenue-cost trade-off accordingly. Since its end-to-end deployment in the advertising pipeline of a leading global e-commerce platform in November 2024, MaRCA has consistently handled hundreds of billions of ad requests per day and has delivered a 16.67% revenue uplift using existing computation resources.
GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection
Dec 10, 2025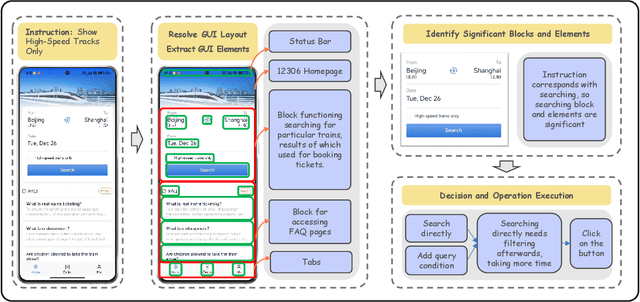
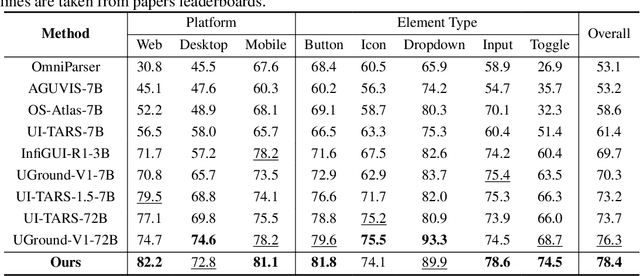
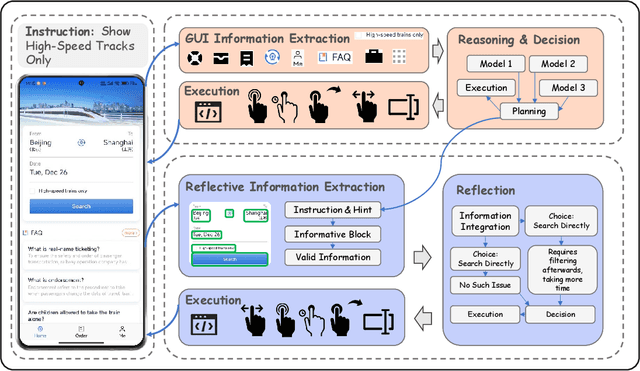
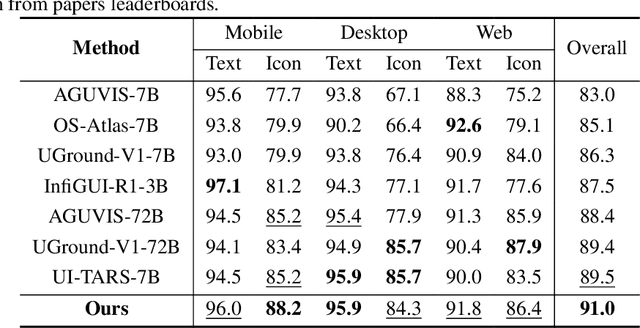
Building AI systems for GUI automation task has attracted remarkable research efforts, where MLLMs are leveraged for processing user requirements and give operations. However, GUI automation includes a wide range of tasks, from document processing to online shopping, from CAD to video editing. Diversity between particular tasks requires MLLMs for GUI automation to have heterogeneous capabilities and master multidimensional expertise, raising problems on constructing such a model. To address such challenge, we propose GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection, a novel MLLM-based GUI automation agent framework designed for integrating knowledge and combining capabilities from heterogeneous models to build GUI automation agent systems with higher performance. Since different GUI-specific MLLMs are trained on different dataset and thus have different strengths, GAIR introduced a general-purpose MLLM for jointly processing the information from multiple GUI-specific models, further enhancing performance of the agent framework. The general-purpose MLLM also serves as decision maker, trying to execute a reasonable operation based on previously gathered information. When the general-purpose model thinks that there isn't sufficient information for a reasonable decision, GAIR would transit into group reflection status, where the general-purpose model would provide GUI-specific models with different instructions and hints based on their strengths and weaknesses, driving them to gather information with more significance and accuracy that can support deeper reasoning and decision. We evaluated the effectiveness and reliability of GAIR through extensive experiments on GUI benchmarks.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage
Sep 06, 2024



Running LLMs on end devices has garnered significant attention recently due to their advantages in privacy preservation. With the advent of lightweight LLM models and specially designed GPUs, on-device LLM inference has achieved the necessary accuracy and performance metrics. However, we have identified that LLM inference on GPUs can leak privacy-sensitive intermediate information, specifically the KV pairs. An attacker could exploit these KV pairs to reconstruct the entire user conversation, leading to significant vulnerabilities. Existing solutions, such as Fully Homomorphic Encryption (FHE) and Trusted Execution Environments (TEE), are either too computation-intensive or resource-limited. To address these issues, we designed KV-Shield, which operates in two phases. In the initialization phase, it permutes the weight matrices so that all KV pairs are correspondingly permuted. During the runtime phase, the attention vector is inversely permuted to ensure the correctness of the layer output. All permutation-related operations are executed within the TEE, ensuring that insecure GPUs cannot access the original KV pairs, thus preventing conversation reconstruction. Finally, we theoretically analyze the correctness of KV-Shield, along with its advantages and overhead.