 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Automated to Autonomous: Hierarchical Agent-native Network Architecture (HANA)
May 20, 2026Realizing Level 4/5 Autonomous Networks (AN) demands a shift from static automation to agent-native intelligence. Current operations, reliant on rigid scripts, lack the cognitive agency to handle off-nominal conditions. To address this, this letter proposes a hierarchical multi-agent reference architecture enabling high-level autonomy. The framework features a Dual-Driven Orchestrator that coordinates specialized Executive Agents, supported by a shared Public Memory for unified domain knowledge. A key innovation is the integration of agent self-awareness, which empowers the system to harmonize deliberative strategic governance with reflexive fault recovery. We instantiate and validate this architecture within a 5G Core environment. Case studies demonstrate that the system sustains critical throughput under congestion and reduces Mean Time to Repair (MTTR) by 86%, confirming its efficacy in unifying strategic planning with operational resilience.
* This manuscript has been accepted by IEEE Networking Letters
GRIP-VLM: Group-Relative Importance Pruning for Efficient Vision-Language Models
May 13, 2026In Vision-Language Models (VLMs), processing a massive number of visual tokens incurs prohibitive computational overhead. While recent training-aware pruning methods attempt to selectively discard redundant tokens, they largely rely on continuous-gradient relaxations. However, visual token pruning is inherently a discrete, non-convex combinatorial problem; consequently, these continuous approximations frequently trap the optimization in sub-optimal local minima, especially under aggressive compression budgets. To overcome this fundamental bottleneck, we propose GRIP-VLM, a Group-Relative Importance Pruning framework driven by Reinforcement Learning. Rather than relying on smooth-gradient assumptions, GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space. Integrated with a budget-aware scorer, our lightweight agent dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining. Extensive experiments across diverse multimodal benchmarks demonstrate that GRIP-VLM consistently outperforms heuristic and supervised-learning baselines, achieving a superior Pareto frontier and delivering up to a 15\% inference speedup at equal accuracy.
EmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
May 11, 2026Embodied agents can benefit from skills that guide object search, action execution, and state changes across diverse environments. Since embodied environments vary across layouts, object states, and other execution factors, these skills must self-evolve from trajectories generated during task execution. However, existing skill self-evolution methods are mainly developed in digital environments and often convert trajectories into coarse skill updates. Directly applying this paradigm to embodied settings is problematic, because a failed task execution may reflect not only incorrect skill content, but also an execution lapse in which the agent fails to follow valid guidance. We propose EmbodiSkill, a training-free framework for embodied skill self-evolution through skill-aware reflection and targeted revision. EmbodiSkill interprets each trajectory with respect to the current skill, uses skill-changing evidence to update the skill body, and uses execution-lapse evidence to preserve and emphasize valid guidance. Experiments on ALFWorld and EmbodiedBench show that EmbodiSkill consistently improves embodied task success. On ALFWorld, EmbodiSkill enables a frozen Qwen3.5-27B executor to reach 93.28% task success, outperforming GPT-5.2 used as a direct agent without skills by 31.58%. These results show that skill-aware self-evolution helps embodied agents accumulate reusable procedural knowledge from their own trajectories.
Learning to Commit: Generating Organic Pull Requests via Online Repository Memory
Mar 27, 2026Large language model (LLM)-based coding agents achieve impressive results on controlled benchmarks yet routinely produce pull requests that real maintainers reject. The root cause is not functional incorrectness but a lack of organicity: generated code ignores project-specific conventions, duplicates functionality already provided by internal APIs, and violates implicit architectural constraints accumulated over years of development. Simply exposing an agent to the latest repository snapshot is not enough: the snapshot reveals the final state of the codebase, but not the repository-specific change patterns by which that state was reached. We introduce Learning to Commit, a framework that closes this gap through Online Repository Memory. Given a repository with a strict chronological split, the agent performs supervised contrastive reflection on earlier commits: it blindly attempts to resolve each historical issue, compares its prediction against the oracle diff, and distils the gap into a continuously growing set of skills-reusable patterns capturing coding style, internal API usage, and architectural invariants. When a new PR description arrives, the agent conditions its generation on these accumulated skills, producing changes grounded in the project's own evolution rather than generic pretraining priors. Evaluation is conducted on genuinely future, merged pull requests that could not have been seen during the skill-building phase, and spans multiple dimensions including functional correctness, code-style consistency, internal API reuse rate, and modified-region plausibility. Experiments on an expert-maintained repository with rich commit history show that Online Repository Memory effectively improves organicity scores on held-out future tasks.
Em-Garde: A Propose-Match Framework for Proactive Streaming Video Understanding
Mar 19, 2026Recent advances in Streaming Video Understanding has enabled a new interaction paradigm where models respond proactively to user queries. Current proactive VideoLLMs rely on per-frame triggering decision making, which suffers from an efficiency-accuracy dilemma. We propose Em-Garde, a novel framework that decouples semantic understanding from streaming perception. At query time, the Instruction-Guided Proposal Parser transforms user queries into structured, perceptually grounded visual proposals; during streaming, a Lightweight Proposal Matching Module performs efficient embedding-based matching to trigger responses. Experiments on StreamingBench and OVO-Bench demonstrate consistent improvements over prior models in proactive response accuracy and efficiency, validating an effective solution for proactive video understanding under strict computational constraints.
OxyGen: Unified KV Cache Management for Vision-Language-Action Models under Multi-Task Parallelism
Mar 15, 2026Embodied AI agents increasingly require parallel execution of multiple tasks, such as manipulation, conversation, and memory construction, from shared observations under distinct time constraints. Recent Mixture-of-Transformers (MoT) Vision-Language-Action Models (VLAs) architecturally support such heterogeneous outputs, yet existing inference systems fail to achieve efficient multi-task parallelism for on-device deployment due to redundant computation and resource contention. We identify isolated KV cache management as the root cause. To address this, we propose unified KV cache management, an inference paradigm that treats KV cache as a first-class shared resource across tasks and over time. This abstraction enables two key optimizations: cross-task KV sharing eliminates redundant prefill of shared observations, while cross-frame continuous batching decouples variable-length language decoding from fixed-rate action generation across control cycles. We implement this paradigm for $π_{0.5}$, the most popular MoT VLA, and evaluate under representative robotic configurations. OxyGen achieves up to 3.7$\times$ speedup over isolated execution, delivering over 200 tokens/s language throughput and 70 Hz action frequency simultaneously without action quality degradation.
AgentProg: Empowering Long-Horizon GUI Agents with Program-Guided Context Management
Dec 11, 2025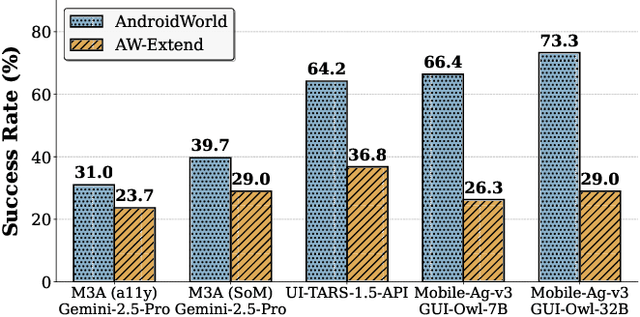

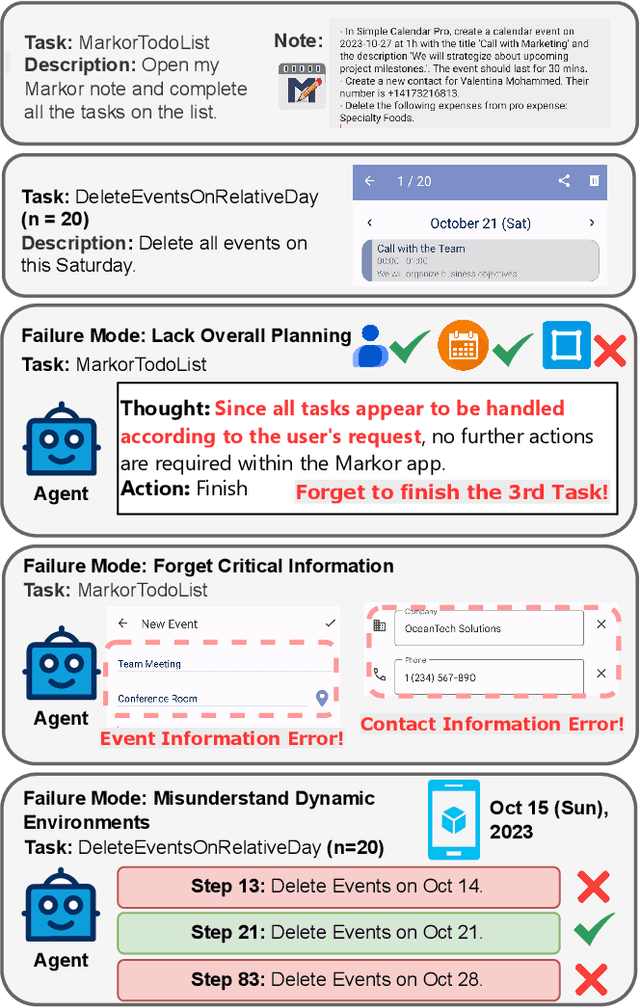

The rapid development of mobile GUI agents has stimulated growing research interest in long-horizon task automation. However, building agents for these tasks faces a critical bottleneck: the reliance on ever-expanding interaction history incurs substantial context overhead. Existing context management and compression techniques often fail to preserve vital semantic information, leading to degraded task performance. We propose AgentProg, a program-guided approach for agent context management that reframes the interaction history as a program with variables and control flow. By organizing information according to the structure of program, this structure provides a principled mechanism to determine which information should be retained and which can be discarded. We further integrate a global belief state mechanism inspired by Belief MDP framework to handle partial observability and adapt to unexpected environmental changes. Experiments on AndroidWorld and our extended long-horizon task suite demonstrate that AgentProg has achieved the state-of-the-art success rates on these benchmarks. More importantly, it maintains robust performance on long-horizon tasks while baseline methods experience catastrophic degradation. Our system is open-sourced at https://github.com/MobileLLM/AgentProg.
EBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilities
Oct 31, 2025Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
Leveraging AI Agents for Autonomous Networks: A Reference Architecture and Empirical Studies
Sep 10, 2025The evolution toward Level 4 (L4) Autonomous Networks (AN) represents a strategic inflection point in telecommunications, where networks must transcend reactive automation to achieve genuine cognitive capabilities--fulfilling TM Forum's vision of self-configuring, self-healing, and self-optimizing systems that deliver zero-wait, zero-touch, and zero-fault services. This work bridges the gap between architectural theory and operational reality by implementing Joseph Sifakis's AN Agent reference architecture in a functional cognitive system, deploying coordinated proactive-reactive runtimes driven by hybrid knowledge representation. Through an empirical case study of a Radio Access Network (RAN) Link Adaptation (LA) Agent, we validate this framework's transformative potential: demonstrating sub-10 ms real-time control in 5G NR sub-6 GHz while achieving 6% higher downlink throughput than Outer Loop Link Adaptation (OLLA) algorithms and 67% Block Error Rate (BLER) reduction for ultra-reliable services through dynamic Modulation and Coding Scheme (MCS) optimization. These improvements confirm the architecture's viability in overcoming traditional autonomy barriers and advancing critical L4-enabling capabilities toward next-generation objectives.
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Aug 24, 2025Recent advancements in Large Language Models (LLMs) have leveraged increased test-time computation to enhance reasoning capabilities, a strategy that, while effective, incurs significant latency and resource costs, limiting their applicability in real-world time-constrained or cost-sensitive scenarios. This paper introduces BudgetThinker, a novel framework designed to empower LLMs with budget-aware reasoning, enabling precise control over the length of their thought processes. We propose a methodology that periodically inserts special control tokens during inference to continuously inform the model of its remaining token budget. This approach is coupled with a comprehensive two-stage training pipeline, beginning with Supervised Fine-Tuning (SFT) to familiarize the model with budget constraints, followed by a curriculum-based Reinforcement Learning (RL) phase that utilizes a length-aware reward function to optimize for both accuracy and budget adherence. We demonstrate that BudgetThinker significantly surpasses strong baselines in maintaining performance across a variety of reasoning budgets on challenging mathematical benchmarks. Our method provides a scalable and effective solution for developing efficient and controllable LLM reasoning, making advanced models more practical for deployment in resource-constrained and real-time environments.