 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Learning to Commit: Generating Organic Pull Requests via Online Repository Memory
Mar 27, 2026Large language model (LLM)-based coding agents achieve impressive results on controlled benchmarks yet routinely produce pull requests that real maintainers reject. The root cause is not functional incorrectness but a lack of organicity: generated code ignores project-specific conventions, duplicates functionality already provided by internal APIs, and violates implicit architectural constraints accumulated over years of development. Simply exposing an agent to the latest repository snapshot is not enough: the snapshot reveals the final state of the codebase, but not the repository-specific change patterns by which that state was reached. We introduce Learning to Commit, a framework that closes this gap through Online Repository Memory. Given a repository with a strict chronological split, the agent performs supervised contrastive reflection on earlier commits: it blindly attempts to resolve each historical issue, compares its prediction against the oracle diff, and distils the gap into a continuously growing set of skills-reusable patterns capturing coding style, internal API usage, and architectural invariants. When a new PR description arrives, the agent conditions its generation on these accumulated skills, producing changes grounded in the project's own evolution rather than generic pretraining priors. Evaluation is conducted on genuinely future, merged pull requests that could not have been seen during the skill-building phase, and spans multiple dimensions including functional correctness, code-style consistency, internal API reuse rate, and modified-region plausibility. Experiments on an expert-maintained repository with rich commit history show that Online Repository Memory effectively improves organicity scores on held-out future tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
AutoTour: Automatic Photo Tour Guide with Smartphones and LLMs
Jan 11, 2026We present AutoTour, a system that enhances user exploration by automatically generating fine-grained landmark annotations and descriptive narratives for photos captured by users. The key idea of AutoTour is to fuse visual features extracted from photos with nearby geospatial features queried from open matching databases. Unlike existing tour applications that rely on pre-defined content or proprietary datasets, AutoTour leverages open and extensible data sources to provide scalable and context-aware photo-based guidance. To achieve this, we design a training-free pipeline that first extracts and filters relevant geospatial features around the user's GPS location. It then detects major landmarks in user photos through VLM-based feature detection and projects them into the horizontal spatial plane. A geometric matching algorithm aligns photo features with corresponding geospatial entities based on their estimated distance and direction. The matched features are subsequently grounded and annotated directly on the original photo, accompanied by large language model-generated textual and audio descriptions to provide an informative, tour-like experience. We demonstrate that AutoTour can deliver rich, interpretable annotations for both iconic and lesser-known landmarks, enabling a new form of interactive, context-aware exploration that bridges visual perception and geospatial understanding.
Sculptor: Empowering LLMs with Cognitive Agency via Active Context Management
Aug 06, 2025Large Language Models (LLMs) suffer from significant performance degradation when processing long contexts due to proactive interference, where irrelevant information in earlier parts of the context disrupts reasoning and memory recall. While most research focuses on external memory systems to augment LLMs' capabilities, we propose a complementary approach: empowering LLMs with Active Context Management (ACM) tools to actively sculpt their internal working memory. We introduce Sculptor, a framework that equips LLMs with three categories of tools: (1) context fragmentation, (2) summary, hide, and restore, and (3) intelligent search. Our approach enables LLMs to proactively manage their attention and working memory, analogous to how humans selectively focus on relevant information while filtering out distractions. Experimental evaluation on information-sparse benchmarks-PI-LLM (proactive interference) and NeedleBench Multi-Needle Reasoning-demonstrates that Sculptor significantly improves performance even without specific training, leveraging LLMs' inherent tool calling generalization capabilities. By enabling Active Context Management, Sculptor not only mitigates proactive interference but also provides a cognitive foundation for more reliable reasoning across diverse long-context tasks-highlighting that explicit context-control strategies, rather than merely larger token windows, are key to robustness at scale.
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
May 29, 2025Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025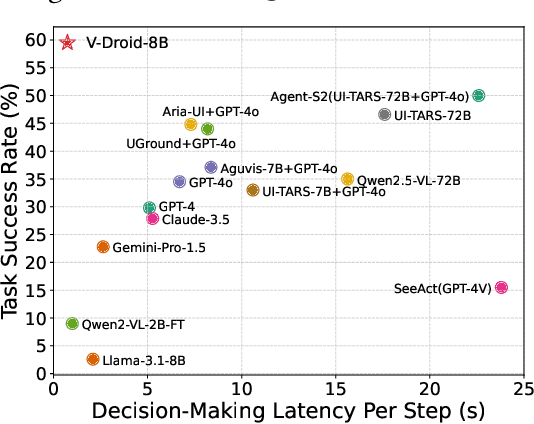
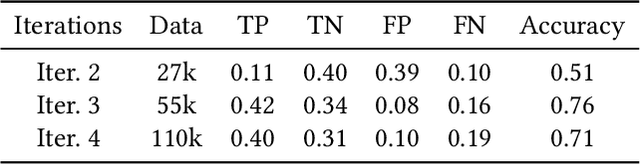
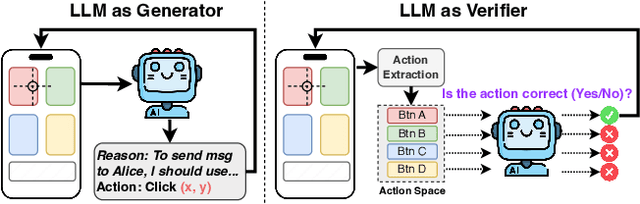
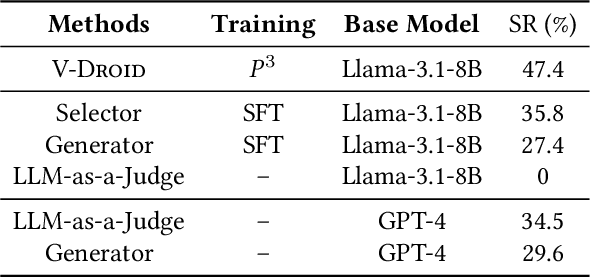
We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.
AutoIOT: LLM-Driven Automated Natural Language Programming for AIoT Applications
Mar 07, 2025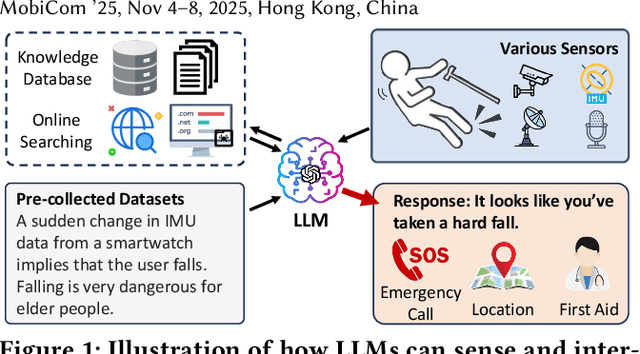


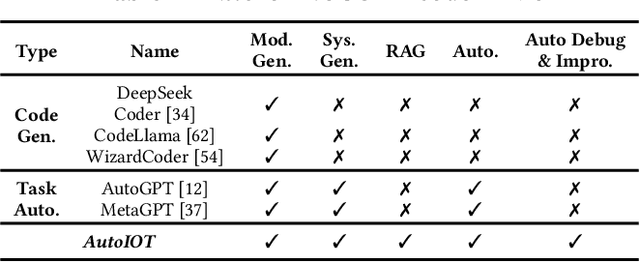
The advent of Large Language Models (LLMs) has profoundly transformed our lives, revolutionizing interactions with AI and lowering the barrier to AI usage. While LLMs are primarily designed for natural language interaction, the extensive embedded knowledge empowers them to comprehend digital sensor data. This capability enables LLMs to engage with the physical world through IoT sensors and actuators, performing a myriad of AIoT tasks. Consequently, this evolution triggers a paradigm shift in conventional AIoT application development, democratizing its accessibility to all by facilitating the design and development of AIoT applications via natural language. However, some limitations need to be addressed to unlock the full potential of LLMs in AIoT application development. First, existing solutions often require transferring raw sensor data to LLM servers, which raises privacy concerns, incurs high query fees, and is limited by token size. Moreover, the reasoning processes of LLMs are opaque to users, making it difficult to verify the robustness and correctness of inference results. This paper introduces AutoIOT, an LLM-based automated program generator for AIoT applications. AutoIOT enables users to specify their requirements using natural language (input) and automatically synthesizes interpretable programs with documentation (output). AutoIOT automates the iterative optimization to enhance the quality of generated code with minimum user involvement. AutoIOT not only makes the execution of AIoT tasks more explainable but also mitigates privacy concerns and reduces token costs with local execution of synthesized programs. Extensive experiments and user studies demonstrate AutoIOT's remarkable capability in program synthesis for various AIoT tasks. The synthesized programs can match and even outperform some representative baselines.
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.
AutoLife: Automatic Life Journaling with Smartphones and LLMs
Dec 23, 2024This paper introduces a novel mobile sensing application - life journaling - designed to generate semantic descriptions of users' daily lives. We present AutoLife, an automatic life journaling system based on commercial smartphones. AutoLife only inputs low-cost sensor data (without photos or audio) from smartphones and can automatically generate comprehensive life journals for users. To achieve this, we first derive time, motion, and location contexts from multimodal sensor data, and harness the zero-shot capabilities of Large Language Models (LLMs), enriched with commonsense knowledge about human lives, to interpret diverse contexts and generate life journals. To manage the task complexity and long sensing duration, a multilayer framework is proposed, which decomposes tasks and seamlessly integrates LLMs with other techniques for life journaling. This study establishes a real-life dataset as a benchmark and extensive experiment results demonstrate that AutoLife produces accurate and reliable life journals.