 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
DA-DPO: Cost-efficient Difficulty-aware Preference Optimization for Reducing MLLM Hallucinations
Jan 02, 2026Direct Preference Optimization (DPO) has shown strong potential for mitigating hallucinations in Multimodal Large Language Models (MLLMs). However, existing multimodal DPO approaches often suffer from overfitting due to the difficulty imbalance in preference data. Our analysis shows that MLLMs tend to overemphasize easily distinguishable preference pairs, which hinders fine-grained hallucination suppression and degrades overall performance. To address this issue, we propose Difficulty-Aware Direct Preference Optimization (DA-DPO), a cost-effective framework designed to balance the learning process. DA-DPO consists of two main components: (1) Difficulty Estimation leverages pre-trained vision--language models with complementary generative and contrastive objectives, whose outputs are integrated via a distribution-aware voting strategy to produce robust difficulty scores without additional training; and (2) Difficulty-Aware Training reweights preference pairs based on their estimated difficulty, down-weighting easy samples while emphasizing harder ones to alleviate overfitting. This framework enables more effective preference optimization by prioritizing challenging examples, without requiring new data or extra fine-tuning stages. Extensive experiments demonstrate that DA-DPO consistently improves multimodal preference optimization, yielding stronger robustness to hallucinations and better generalization across standard benchmarks, while remaining computationally efficient. The project page is available at https://artanic30.github.io/project_pages/DA-DPO/.
Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery
Jul 16, 2025In this paper, we address the problem of novel class discovery (NCD), which aims to cluster novel classes by leveraging knowledge from disjoint known classes. While recent advances have made significant progress in this area, existing NCD methods face two major limitations. First, they primarily focus on single-view data (e.g., images), overlooking the increasingly common multi-view data, such as multi-omics datasets used in disease diagnosis. Second, their reliance on pseudo-labels to supervise novel class clustering often results in unstable performance, as pseudo-label quality is highly sensitive to factors such as data noise and feature dimensionality. To address these challenges, we propose a novel framework named Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery (IICMVNCD), which is the first attempt to explore NCD in multi-view setting so far. Specifically, at the intra-view level, leveraging the distributional similarity between known and novel classes, we employ matrix factorization to decompose features into view-specific shared base matrices and factor matrices. The base matrices capture distributional consistency among the two datasets, while the factor matrices model pairwise relationships between samples. At the inter-view level, we utilize view relationships among known classes to guide the clustering of novel classes. This includes generating predicted labels through the weighted fusion of factor matrices and dynamically adjusting view weights of known classes based on the supervision loss, which are then transferred to novel class learning. Experimental results validate the effectiveness of our proposed approach.
Freeze and Cluster: A Simple Baseline for Rehearsal-Free Continual Category Discovery
Mar 12, 2025This paper addresses the problem of Rehearsal-Free Continual Category Discovery (RF-CCD), which focuses on continuously identifying novel class by leveraging knowledge from labeled data. Existing methods typically train from scratch, overlooking the potential of base models, and often resort to data storage to prevent forgetting. Moreover, because RF-CCD encompasses both continual learning and novel class discovery, previous approaches have struggled to effectively integrate advanced techniques from these fields, resulting in less convincing comparisons and failing to reveal the unique challenges posed by RF-CCD. To address these challenges, we lead the way in integrating advancements from both domains and conducting extensive experiments and analyses. Our findings demonstrate that this integration can achieve state-of-the-art results, leading to the conclusion that in the presence of pre-trained models, the representation does not improve and may even degrade with the introduction of unlabeled data. To mitigate representation degradation, we propose a straightforward yet highly effective baseline method. This method first utilizes prior knowledge of known categories to estimate the number of novel classes. It then acquires representations using a model specifically trained on the base classes, generates high-quality pseudo-labels through k-means clustering, and trains only the classifier layer. We validate our conclusions and methods by conducting extensive experiments across multiple benchmarks, including the Stanford Cars, CUB, iNat, and Tiny-ImageNet datasets. The results clearly illustrate our findings, demonstrate the effectiveness of our baseline, and pave the way for future advancements in RF-CCD.
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.
Composing Novel Classes: A Concept-Driven Approach to Generalized Category Discovery
Oct 17, 2024We tackle the generalized category discovery (GCD) problem, which aims to discover novel classes in unlabeled datasets by leveraging the knowledge of known classes. Previous works utilize the known class knowledge through shared representation spaces. Despite their progress, our analysis experiments show that novel classes can achieve impressive clustering results on the feature space of a known class pre-trained model, suggesting that existing methods may not fully utilize known class knowledge. To address it, we introduce a novel concept learning framework for GCD, named ConceptGCD, that categorizes concepts into two types: derivable and underivable from known class concepts, and adopts a stage-wise learning strategy to learn them separately. Specifically, our framework first extracts known class concepts by a known class pre-trained model and then produces derivable concepts from them by a generator layer with a covariance-augmented loss. Subsequently, we expand the generator layer to learn underivable concepts in a balanced manner ensured by a concept score normalization strategy and integrate a contrastive loss to preserve previously learned concepts. Extensive experiments on various benchmark datasets demonstrate the superiority of our approach over the previous state-of-the-art methods. Code will be available soon.
Dual-level Adaptive Self-Labeling for Novel Class Discovery in Point Cloud Segmentation
Jul 17, 2024



We tackle the novel class discovery in point cloud segmentation, which discovers novel classes based on the semantic knowledge of seen classes. Existing work proposes an online point-wise clustering method with a simplified equal class-size constraint on the novel classes to avoid degenerate solutions. However, the inherent imbalanced distribution of novel classes in point clouds typically violates the equal class-size constraint. Moreover, point-wise clustering ignores the rich spatial context information of objects, which results in less expressive representation for semantic segmentation. To address the above challenges, we propose a novel self-labeling strategy that adaptively generates high-quality pseudo-labels for imbalanced classes during model training. In addition, we develop a dual-level representation that incorporates regional consistency into the point-level classifier learning, reducing noise in generated segmentation. Finally, we conduct extensive experiments on two widely used datasets, SemanticKITTI and SemanticPOSS, and the results show our method outperforms the state of the art by a large margin.
CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Jul 15, 2024

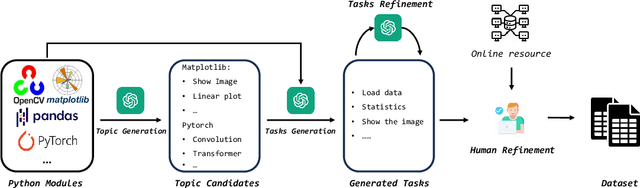

While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
SP$^2$OT: Semantic-Regularized Progressive Partial Optimal Transport for Imbalanced Clustering
Apr 04, 2024Deep clustering, which learns representation and semantic clustering without labels information, poses a great challenge for deep learning-based approaches. Despite significant progress in recent years, most existing methods focus on uniformly distributed datasets, significantly limiting the practical applicability of their methods. In this paper, we propose a more practical problem setting named deep imbalanced clustering, where the underlying classes exhibit an imbalance distribution. To address this challenge, we introduce a novel optimal transport-based pseudo-label learning framework. Our framework formulates pseudo-label generation as a Semantic-regularized Progressive Partial Optimal Transport (SP$^2$OT) problem, which progressively transports each sample to imbalanced clusters under several prior distribution and semantic relation constraints, thus generating high-quality and imbalance-aware pseudo-labels. To solve SP$^2$OT, we develop a Majorization-Minimization-based optimization algorithm. To be more precise, we employ the strategy of majorization to reformulate the SP$^2$OT problem into a Progressive Partial Optimal Transport problem, which can be transformed into an unbalanced optimal transport problem with augmented constraints and can be solved efficiently by a fast matrix scaling algorithm. Experiments on various datasets, including a human-curated long-tailed CIFAR100, challenging ImageNet-R, and large-scale subsets of fine-grained iNaturalist2018 datasets, demonstrate the superiority of our method.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.