 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibeTensor: System Software for Deep Learning, Fully Generated by AI Agents
Jan 21, 2026VIBETENSOR is an open-source research system software stack for deep learning, generated by LLM-powered coding agents under high-level human guidance. In this paper, "fully generated" refers to code provenance: implementation changes were produced and applied as agent-proposed diffs; validation relied on agent-run builds, tests, and differential checks, without per-change manual diff review. It implements a PyTorch-style eager tensor library with a C++20 core (CPU+CUDA), a torch-like Python overlay via nanobind, and an experimental Node.js/TypeScript interface. Unlike thin bindings, VIBETENSOR includes its own tensor/storage system, schema-lite dispatcher, reverse-mode autograd, CUDA runtime (streams/events/graphs), a stream-ordered caching allocator with diagnostics, and a stable C ABI for dynamically loaded operator plugins. We view this release as a milestone for AI-assisted software engineering: it shows coding agents can generate a coherent deep learning runtime spanning language bindings down to CUDA memory management, validated primarily by builds and tests. We describe the architecture, summarize the workflow used to produce and validate the system, and evaluate the artifact. We report repository scale and test-suite composition, and summarize reproducible microbenchmarks from an accompanying AI-generated kernel suite, including fused attention versus PyTorch SDPA/FlashAttention. We also report end-to-end training sanity checks on 3 small workloads (sequence reversal, ViT, miniGPT) on NVIDIA H100 (Hopper, SM90) and Blackwell-class GPUs; multi-GPU results are Blackwell-only and use an optional CUTLASS-based ring-allreduce plugin gated on CUDA 13+ and sm103a toolchain support. Finally, we discuss failure modes in generated system software, including a "Frankenstein" composition effect where locally correct subsystems interact to yield globally suboptimal performance.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Jul 15, 2024

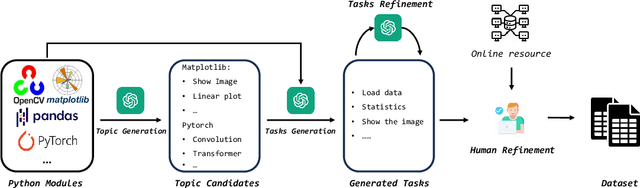

While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
InternLM-Law: An Open Source Chinese Legal Large Language Model
Jun 21, 2024While large language models (LLMs) have showcased impressive capabilities, they struggle with addressing legal queries due to the intricate complexities and specialized expertise required in the legal field. In this paper, we introduce InternLM-Law, a specialized LLM tailored for addressing diverse legal queries related to Chinese laws, spanning from responding to standard legal questions (e.g., legal exercises in textbooks) to analyzing complex real-world legal situations. We meticulously construct a dataset in the Chinese legal domain, encompassing over 1 million queries, and implement a data filtering and processing pipeline to ensure its diversity and quality. Our training approach involves a novel two-stage process: initially fine-tuning LLMs on both legal-specific and general-purpose content to equip the models with broad knowledge, followed by exclusive fine-tuning on high-quality legal data to enhance structured output generation. InternLM-Law achieves the highest average performance on LawBench, outperforming state-of-the-art models, including GPT-4, on 13 out of 20 subtasks. We make InternLM-Law and our dataset publicly available to facilitate future research in applying LLMs within the legal domain.
MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
May 20, 2024



Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024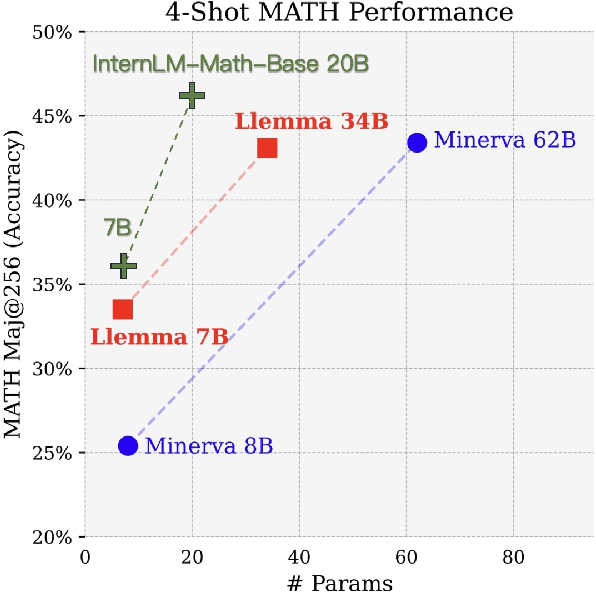
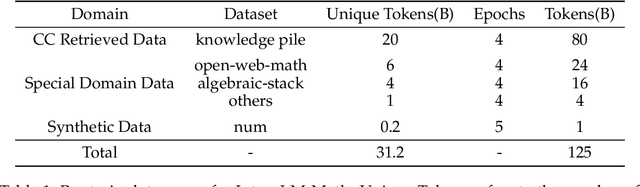
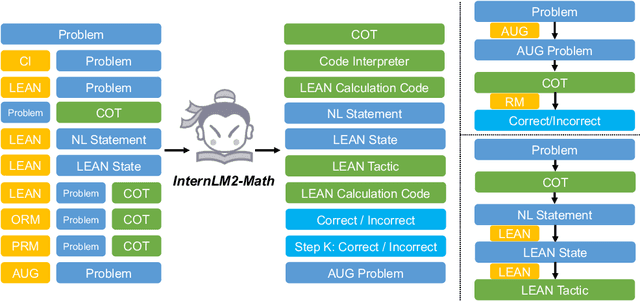
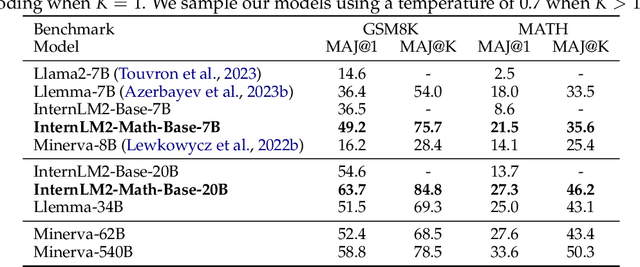
The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.
LawBench: Benchmarking Legal Knowledge of Large Language Models
Sep 28, 2023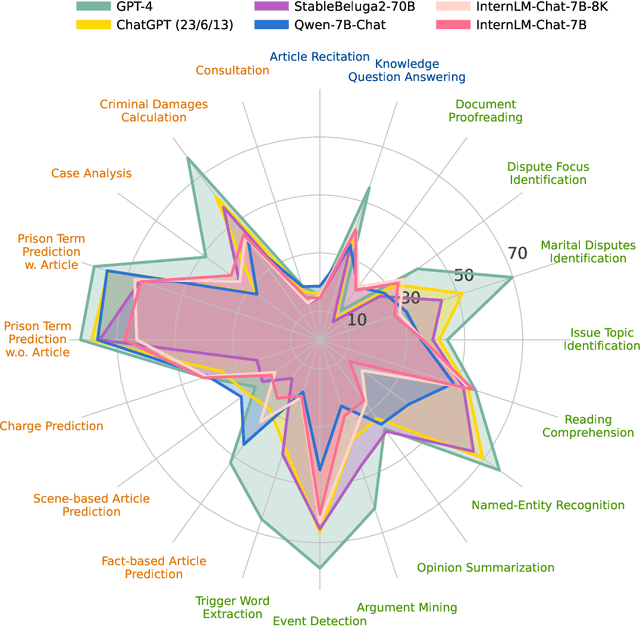
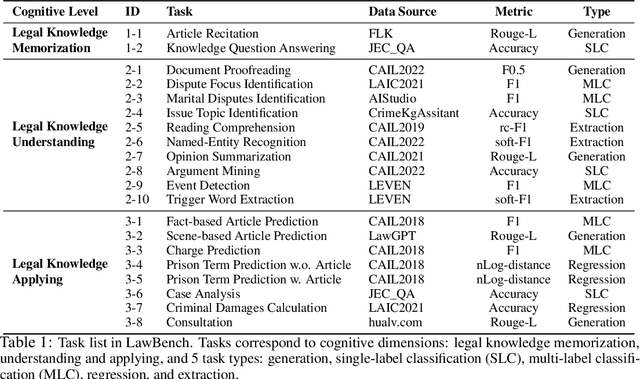
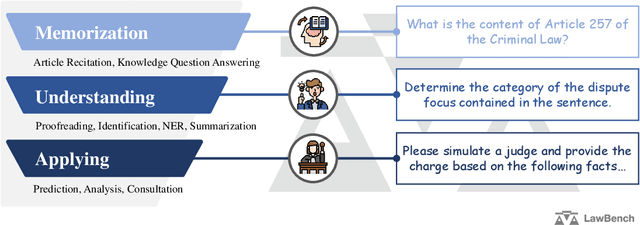
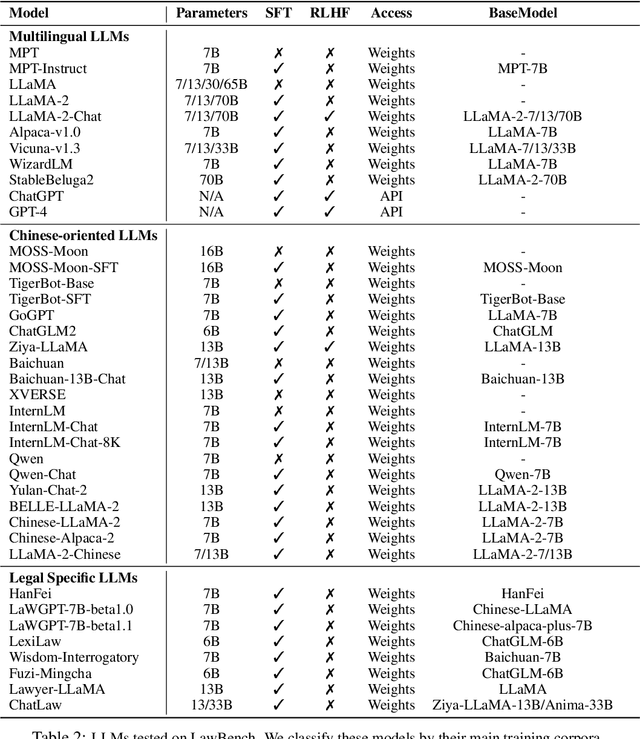
Large language models (LLMs) have demonstrated strong capabilities in various aspects. However, when applying them to the highly specialized, safe-critical legal domain, it is unclear how much legal knowledge they possess and whether they can reliably perform legal-related tasks. To address this gap, we propose a comprehensive evaluation benchmark LawBench. LawBench has been meticulously crafted to have precise assessment of the LLMs' legal capabilities from three cognitive levels: (1) Legal knowledge memorization: whether LLMs can memorize needed legal concepts, articles and facts; (2) Legal knowledge understanding: whether LLMs can comprehend entities, events and relationships within legal text; (3) Legal knowledge applying: whether LLMs can properly utilize their legal knowledge and make necessary reasoning steps to solve realistic legal tasks. LawBench contains 20 diverse tasks covering 5 task types: single-label classification (SLC), multi-label classification (MLC), regression, extraction and generation. We perform extensive evaluations of 51 LLMs on LawBench, including 20 multilingual LLMs, 22 Chinese-oriented LLMs and 9 legal specific LLMs. The results show that GPT-4 remains the best-performing LLM in the legal domain, surpassing the others by a significant margin. While fine-tuning LLMs on legal specific text brings certain improvements, we are still a long way from obtaining usable and reliable LLMs in legal tasks. All data, model predictions and evaluation code are released in https://github.com/open-compass/LawBench/. We hope this benchmark provides in-depth understanding of the LLMs' domain-specified capabilities and speed up the development of LLMs in the legal domain.