 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternLM-Law: An Open Source Chinese Legal Large Language Model
Jun 21, 2024While large language models (LLMs) have showcased impressive capabilities, they struggle with addressing legal queries due to the intricate complexities and specialized expertise required in the legal field. In this paper, we introduce InternLM-Law, a specialized LLM tailored for addressing diverse legal queries related to Chinese laws, spanning from responding to standard legal questions (e.g., legal exercises in textbooks) to analyzing complex real-world legal situations. We meticulously construct a dataset in the Chinese legal domain, encompassing over 1 million queries, and implement a data filtering and processing pipeline to ensure its diversity and quality. Our training approach involves a novel two-stage process: initially fine-tuning LLMs on both legal-specific and general-purpose content to equip the models with broad knowledge, followed by exclusive fine-tuning on high-quality legal data to enhance structured output generation. InternLM-Law achieves the highest average performance on LawBench, outperforming state-of-the-art models, including GPT-4, on 13 out of 20 subtasks. We make InternLM-Law and our dataset publicly available to facilitate future research in applying LLMs within the legal domain.
A Comprehensive Evaluation of Parameter-Efficient Fine-Tuning on Software Engineering Tasks
Dec 25, 2023Pre-trained models (PTMs) have achieved great success in various Software Engineering (SE) downstream tasks following the ``pre-train then fine-tune'' paradigm. As fully fine-tuning all parameters of PTMs can be computationally expensive, a widely used solution is parameter-efficient fine-tuning (PEFT), which freezes PTMs while introducing extra parameters. Though work has been done to test PEFT methods in the SE field, a comprehensive evaluation is still lacking. This paper aims to fill in this gap by evaluating the effectiveness of five PEFT methods on eight PTMs and four SE downstream tasks. For different tasks and PEFT methods, we seek answers to the following research questions: 1) Is it more effective to use PTMs trained specifically on source code, or is it sufficient to use PTMs trained on natural language text? 2) What is the impact of varying model sizes? 3) How does the model architecture affect the performance? Besides effectiveness, we also discuss the efficiency of PEFT methods, concerning the costs of required training time and GPU resource consumption. We hope that our findings can provide a deeper understanding of PEFT methods on various PTMs and SE downstream tasks. All the codes and data are available at \url{https://github.com/zwtnju/PEFT.git}.
LawBench: Benchmarking Legal Knowledge of Large Language Models
Sep 28, 2023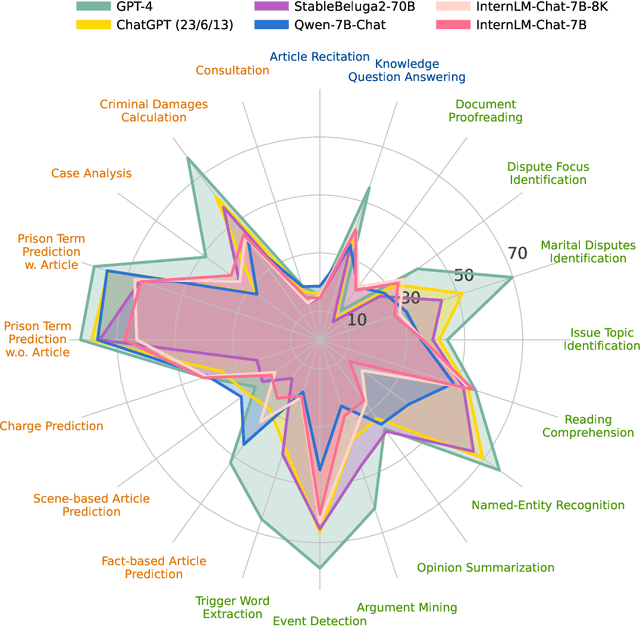
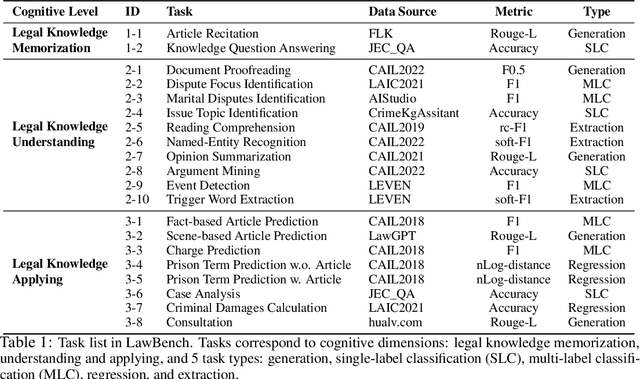
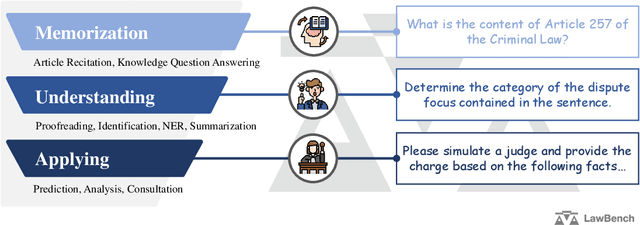
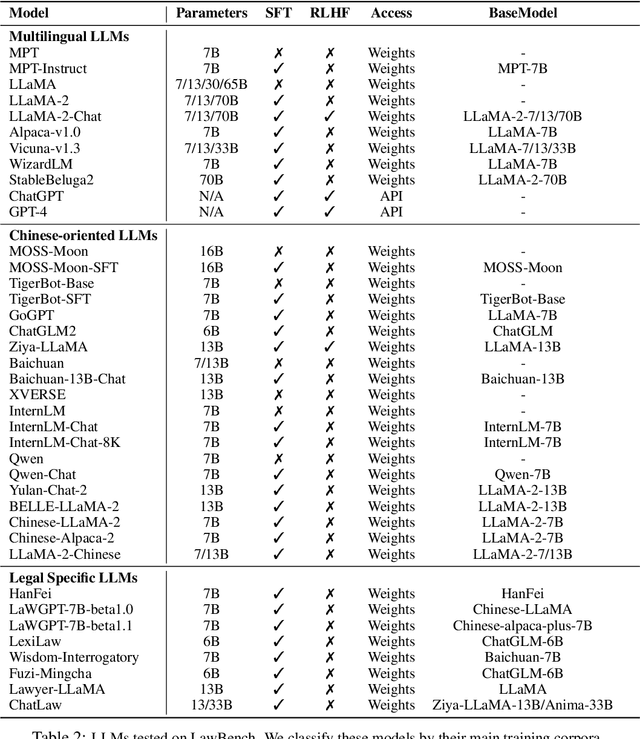
Large language models (LLMs) have demonstrated strong capabilities in various aspects. However, when applying them to the highly specialized, safe-critical legal domain, it is unclear how much legal knowledge they possess and whether they can reliably perform legal-related tasks. To address this gap, we propose a comprehensive evaluation benchmark LawBench. LawBench has been meticulously crafted to have precise assessment of the LLMs' legal capabilities from three cognitive levels: (1) Legal knowledge memorization: whether LLMs can memorize needed legal concepts, articles and facts; (2) Legal knowledge understanding: whether LLMs can comprehend entities, events and relationships within legal text; (3) Legal knowledge applying: whether LLMs can properly utilize their legal knowledge and make necessary reasoning steps to solve realistic legal tasks. LawBench contains 20 diverse tasks covering 5 task types: single-label classification (SLC), multi-label classification (MLC), regression, extraction and generation. We perform extensive evaluations of 51 LLMs on LawBench, including 20 multilingual LLMs, 22 Chinese-oriented LLMs and 9 legal specific LLMs. The results show that GPT-4 remains the best-performing LLM in the legal domain, surpassing the others by a significant margin. While fine-tuning LLMs on legal specific text brings certain improvements, we are still a long way from obtaining usable and reliable LLMs in legal tasks. All data, model predictions and evaluation code are released in https://github.com/open-compass/LawBench/. We hope this benchmark provides in-depth understanding of the LLMs' domain-specified capabilities and speed up the development of LLMs in the legal domain.
Judicial Intelligent Assistant System: Extracting Events from Divorce Cases to Detect Disputes for the Judge
Mar 23, 2023In formal procedure of civil cases, the textual materials provided by different parties describe the development process of the cases. It is a difficult but necessary task to extract the key information for the cases from these textual materials and to clarify the dispute focus of related parties. Currently, officers read the materials manually and use methods, such as keyword searching and regular matching, to get the target information. These approaches are time-consuming and heavily depending on prior knowledge and carefulness of the officers. To assist the officers to enhance working efficiency and accuracy, we propose an approach to detect disputes from divorce cases based on a two-round-labeling event extracting technique in this paper. We implement the Judicial Intelligent Assistant (JIA) system according to the proposed approach to 1) automatically extract focus events from divorce case materials, 2) align events by identifying co-reference among them, and 3) detect conflicts among events brought by the plaintiff and the defendant. With the JIA system, it is convenient for judges to determine the disputed issues. Experimental results demonstrate that the proposed approach and system can obtain the focus of cases and detect conflicts more effectively and efficiently comparing with existing method.
Learning the Relation between Similarity Loss and Clustering Loss in Self-Supervised Learning
Jan 08, 2023



Self-supervised learning enables networks to learn discriminative features from massive data itself. Most state-of-the-art methods maximize the similarity between two augmentations of one image based on contrastive learning. By utilizing the consistency of two augmentations, the burden of manual annotations can be freed. Contrastive learning exploits instance-level information to learn robust features. However, the learned information is probably confined to different views of the same instance. In this paper, we attempt to leverage the similarity between two distinct images to boost representation in self-supervised learning. In contrast to instance-level information, the similarity between two distinct images may provide more useful information. Besides, we analyze the relation between similarity loss and feature-level cross-entropy loss. These two losses are essential for most deep learning methods. However, the relation between these two losses is not clear. Similarity loss helps obtain instance-level representation, while feature-level cross-entropy loss helps mine the similarity between two distinct images. We provide theoretical analyses and experiments to show that a suitable combination of these two losses can get state-of-the-art results.
MDIA: A Benchmark for Multilingual Dialogue Generation in 46 Languages
Aug 27, 2022

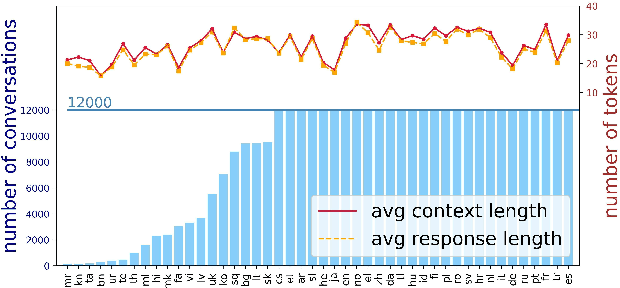
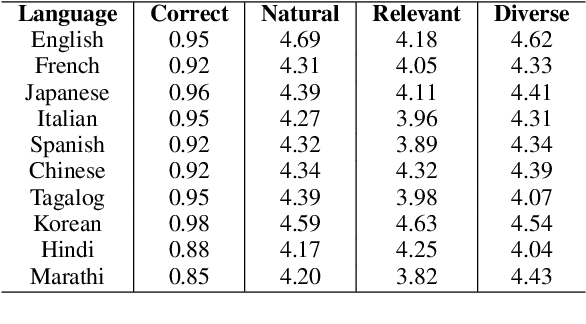
Owing to the lack of corpora for low-resource languages, current works on dialogue generation have mainly focused on English. In this paper, we present mDIA, the first large-scale multilingual benchmark for dialogue generation across low- to high-resource languages. It covers real-life conversations in 46 languages across 19 language families. We present baseline results obtained by fine-tuning the multilingual, non-dialogue-focused pre-trained model mT5 as well as English-centric, dialogue-focused pre-trained chatbot DialoGPT. The results show that mT5-based models perform better on sacreBLEU and BertScore but worse on diversity. Even though promising results are found in few-shot and zero-shot scenarios, there is a large gap between the generation quality in English and other languages. We hope that the release of mDIA could encourage more works on multilingual dialogue generation to promote language diversity.
Neural Program Repair: Systems, Challenges and Solutions
Feb 22, 2022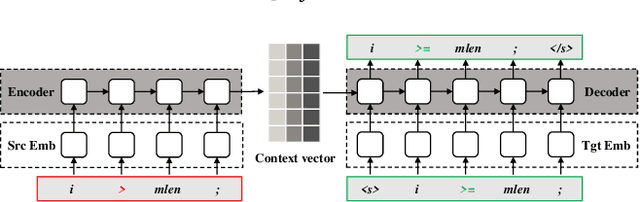
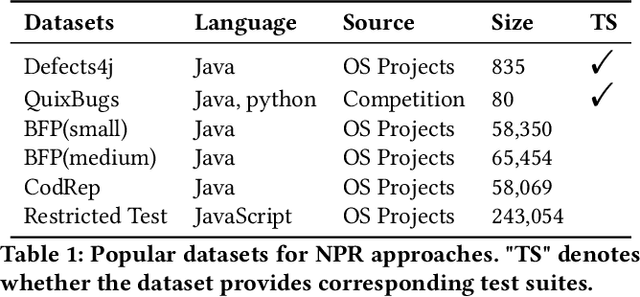
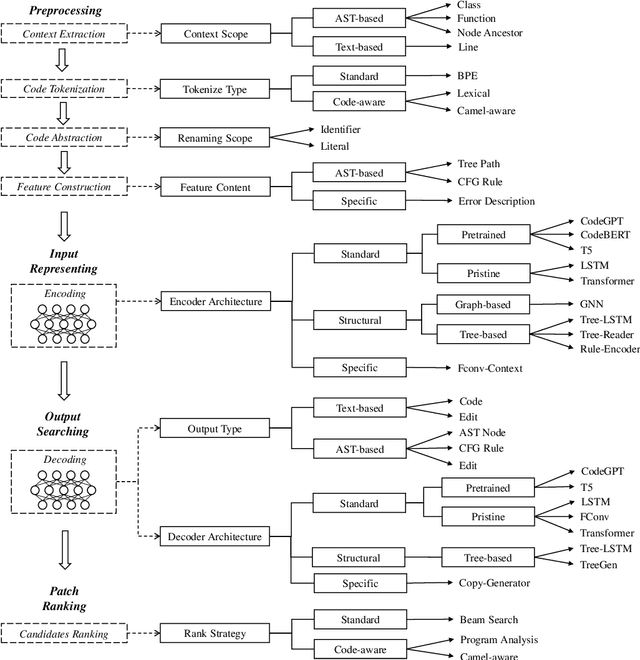

Automated Program Repair (APR) aims to automatically fix bugs in the source code. Recently, as advances in Deep Learning (DL) field, there is a rise of Neural Program Repair (NPR) studies, which formulate APR as a translation task from buggy code to correct code and adopt neural networks based on encoder-decoder architecture. Compared with other APR techniques, NPR approaches have a great advantage in applicability because they do not need any specification (i.e., a test suite). Although NPR has been a hot research direction, there isn't any overview on this field yet. In order to help interested readers understand architectures, challenges and corresponding solutions of existing NPR systems, we conduct a literature review on latest studies in this paper. We begin with introducing the background knowledge on this field. Next, to be understandable, we decompose the NPR procedure into a series of modules and explicate various design choices on each module. Furthermore, we identify several challenges and discuss the effect of existing solutions. Finally, we conclude and provide some promising directions for future research.
Dependency Learning for Legal Judgment Prediction with a Unified Text-to-Text Transformer
Dec 13, 2021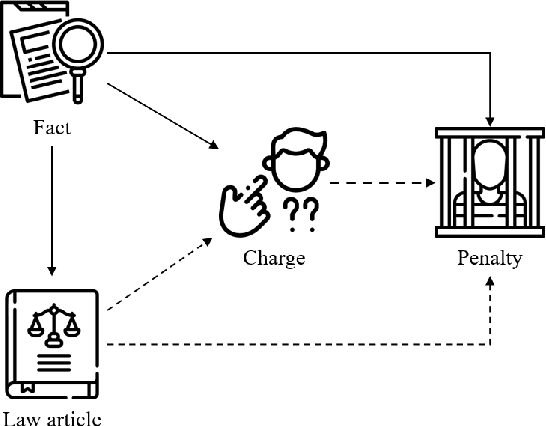


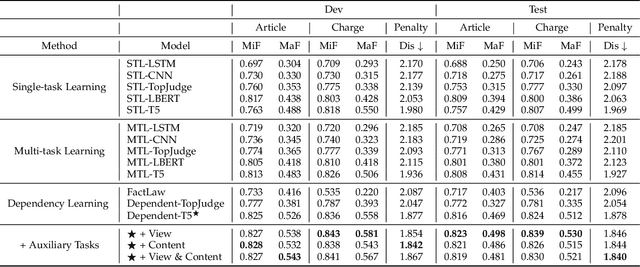
Given the fact of a case, Legal Judgment Prediction (LJP) involves a series of sub-tasks such as predicting violated law articles, charges and term of penalty. We propose leveraging a unified text-to-text Transformer for LJP, where the dependencies among sub-tasks can be naturally established within the auto-regressive decoder. Compared with previous works, it has three advantages: (1) it fits in the pretraining pattern of masked language models, and thereby can benefit from the semantic prompts of each sub-task rather than treating them as atomic labels, (2) it utilizes a single unified architecture, enabling full parameter sharing across all sub-tasks, and (3) it can incorporate both classification and generative sub-tasks. We show that this unified transformer, albeit pretrained on general-domain text, outperforms pretrained models tailored specifically for the legal domain. Through an extensive set of experiments, we find that the best order to capture dependencies is different from human intuitions, and the most reasonable logical order for humans can be sub-optimal for the model. We further include two more auxiliary tasks: court view generation and article content prediction, showing they can not only improve the prediction accuracy, but also provide interpretable explanations for model outputs even when an error is made. With the best configuration, our model outperforms both previous SOTA and a single-tasked version of the unified transformer by a large margin.
AST-Transformer: Encoding Abstract Syntax Trees Efficiently for Code Summarization
Dec 02, 2021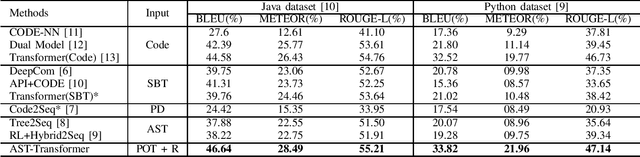
Code summarization aims to generate brief natural language descriptions for source code. As source code is highly structured and follows strict programming language grammars, its Abstract Syntax Tree (AST) is often leveraged to inform the encoder about the structural information. However, ASTs are usually much longer than the source code. Current approaches ignore the size limit and simply feed the whole linearized AST into the encoder. To address this problem, we propose AST-Transformer to efficiently encode tree-structured ASTs. Experiments show that AST-Transformer outperforms the state-of-arts by a substantial margin while being able to reduce $90\sim95\%$ of the computational complexity in the encoding process.
Learning Fine-grained Fact-Article Correspondence in Legal Cases
Apr 24, 2021

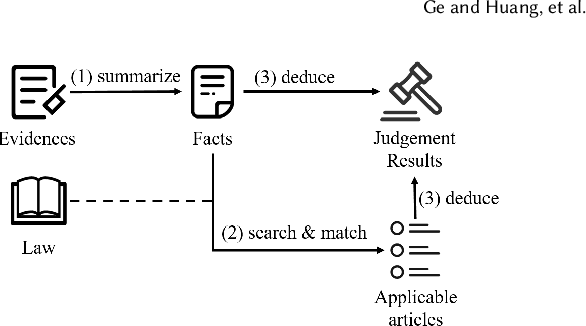

Automatically recommending relevant law articles to a given legal case has attracted much attention as it can greatly release human labor from searching over the large database of laws. However, current researches only support coarse-grained recommendation where all relevant articles are predicted as a whole without explaining which specific fact each article is relevant with. Since one case can be formed of many supporting facts, traversing over them to verify the correctness of recommendation results can be time-consuming. We believe that learning fine-grained correspondence between each single fact and law articles is crucial for an accurate and trustworthy AI system. With this motivation, we perform a pioneering study and create a corpus with manually annotated fact-article correspondences. We treat the learning as a text matching task and propose a multi-level matching network to address it. To help the model better digest the content of law articles, we parse articles in form of premise-conclusion pairs with random forest. Experiments show that the parsed form yielded better performance and the resulting model surpassed other popular text matching baselines. Furthermore, we compare with previous researches and find that establishing the fine-grained fact-article correspondences can improve the recommendation accuracy by a large margin. Our best system reaches an F1 score of 96.3%, making it of great potential for practical use. It can also significantly boost the downstream task of legal decision prediction, increasing the F1 score by up to 12.7%.