 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Perception to Planning: Evolving Ego-Centric Task-Oriented Spatiotemporal Reasoning via Curriculum Learning
Apr 12, 2026Modern vision-language models achieve strong performance in static perception, but remain limited in the complex spatiotemporal reasoning required for embodied, egocentric tasks. A major source of failure is their reliance on temporal priors learned from passive video data, which often leads to spatiotemporal hallucinations and poor generalization in dynamic environments. To address this, we present EgoTSR, a curriculum-based framework for learning task-oriented spatiotemporal reasoning. EgoTSR is built on the premise that embodied reasoning should evolve from explicit spatial understanding to internalized task-state assessment and finally to long-horizon planning. To support this paradigm, we construct EgoTSR-Data, a large-scale dataset comprising 46 million samples organized into three stages: Chain-of-Thought (CoT) supervision, weakly supervised tagging, and long-horizon sequences. Extensive experiments demonstrate that EgoTSR effectively eliminates chronological biases, achieving 92.4% accuracy on long-horizon logical reasoning tasks while maintaining high fine-grained perceptual precision, significantly outperforming existing open-source and closed-source state-of-the-art models.
Bridging Discrete Marks and Continuous Dynamics: Dual-Path Cross-Interaction for Marked Temporal Point Processes
Mar 12, 2026Predicting irregularly spaced event sequences with discrete marks poses significant challenges due to the complex, asynchronous dependencies embedded within continuous-time data streams.Existing sequential approaches capture dependencies among event tokens but ignore the continuous evolution between events, while Neural Ordinary Differential Equation (Neural ODE) methods model smooth dynamics yet fail to account for how event types influence future timing.To overcome these limitations, we propose NEXTPP, a dual-channel framework that unifies discrete and continuous representations via Event-granular Neural Evolution with Cross-Interaction for Marked Temporal Point Processes. Specifically, NEXTPP encodes discrete event marks via a self-attention mechanism, simultaneously evolving a latent continuous-time state using a Neural ODE. These parallel streams are then fused through a crossattention module to enable explicit bidirectional interaction between continuous and discrete representations. The fused representations drive the conditional intensity function of the neural Hawkes process, while an iterative thinning sampler is employed to generate future events. Extensive evaluations on five real-world datasets demonstrate that NEXTPP consistently outperforms state-of-the-art models. The source code can be found at https://github.com/AONE-NLP/NEXTPP.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Writing Like the Best: Exemplar-Based Expository Text Generation
May 24, 2025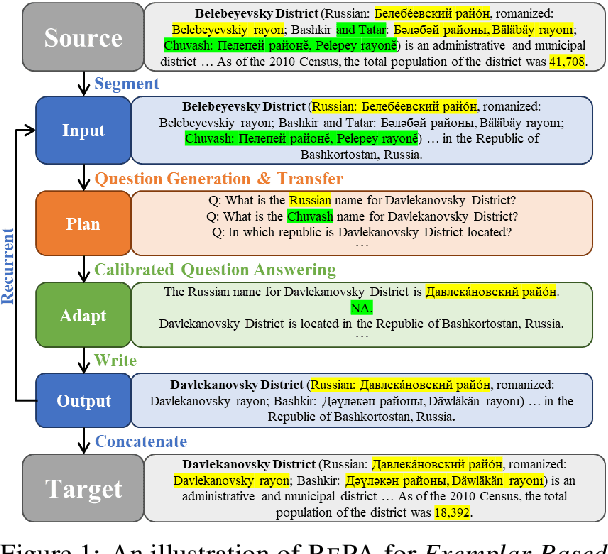
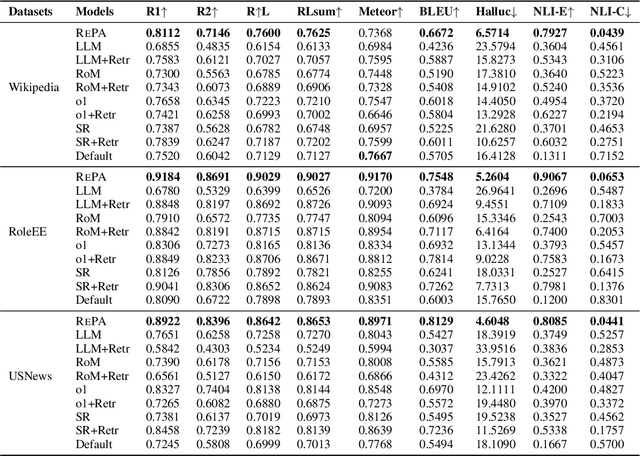
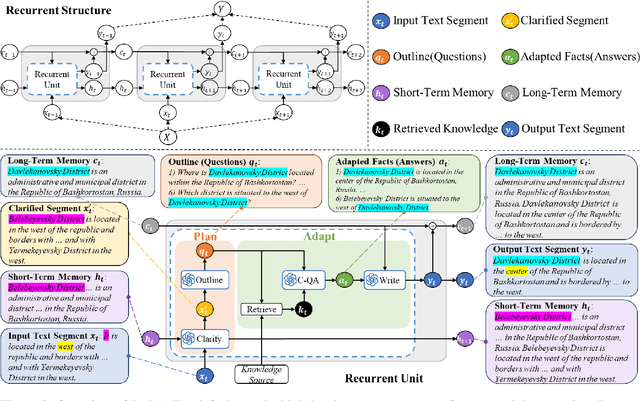
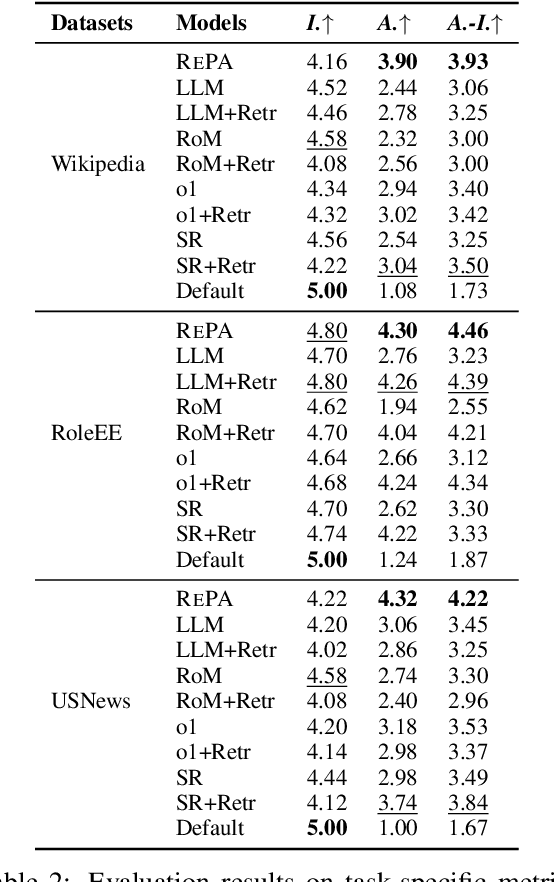
We introduce the Exemplar-Based Expository Text Generation task, aiming to generate an expository text on a new topic using an exemplar on a similar topic. Current methods fall short due to their reliance on extensive exemplar data, difficulty in adapting topic-specific content, and issues with long-text coherence. To address these challenges, we propose the concept of Adaptive Imitation and present a novel Recurrent Plan-then-Adapt (RePA) framework. RePA leverages large language models (LLMs) for effective adaptive imitation through a fine-grained plan-then-adapt process. RePA also enables recurrent segment-by-segment imitation, supported by two memory structures that enhance input clarity and output coherence. We also develop task-specific evaluation metrics--imitativeness, adaptiveness, and adaptive-imitativeness--using LLMs as evaluators. Experimental results across our collected three diverse datasets demonstrate that RePA surpasses existing baselines in producing factual, consistent, and relevant texts for this task.
NTR-Gaussian: Nighttime Dynamic Thermal Reconstruction with 4D Gaussian Splatting Based on Thermodynamics
Mar 05, 2025Thermal infrared imaging offers the advantage of all-weather capability, enabling non-intrusive measurement of an object's surface temperature. Consequently, thermal infrared images are employed to reconstruct 3D models that accurately reflect the temperature distribution of a scene, aiding in applications such as building monitoring and energy management. However, existing approaches predominantly focus on static 3D reconstruction for a single time period, overlooking the impact of environmental factors on thermal radiation and failing to predict or analyze temperature variations over time. To address these challenges, we propose the NTR-Gaussian method, which treats temperature as a form of thermal radiation, incorporating elements like convective heat transfer and radiative heat dissipation. Our approach utilizes neural networks to predict thermodynamic parameters such as emissivity, convective heat transfer coefficient, and heat capacity. By integrating these predictions, we can accurately forecast thermal temperatures at various times throughout a nighttime scene. Furthermore, we introduce a dynamic dataset specifically for nighttime thermal imagery. Extensive experiments and evaluations demonstrate that NTR-Gaussian significantly outperforms comparison methods in thermal reconstruction, achieving a predicted temperature error within 1 degree Celsius.
Molecular Odor Prediction with Harmonic Modulated Feature Mapping and Chemically-Informed Loss
Feb 03, 2025



Molecular odor prediction has great potential across diverse fields such as chemistry, pharmaceuticals, and environmental science, enabling the rapid design of new materials and enhancing environmental monitoring. However, current methods face two main challenges: First, existing models struggle with non-smooth objective functions and the complexity of mixed feature dimensions; Second, datasets suffer from severe label imbalance, which hampers model training, particularly in learning minority class labels. To address these issues, we introduce a novel feature mapping method and a molecular ensemble optimization loss function. By incorporating feature importance learning and frequency modulation, our model adaptively adjusts the contribution of each feature, efficiently capturing the intricate relationship between molecular structures and odor descriptors. Our feature mapping preserves feature independence while enhancing the model's efficiency in utilizing molecular features through frequency modulation. Furthermore, the proposed loss function dynamically adjusts label weights, improves structural consistency, and strengthens label correlations, effectively addressing data imbalance and label co-occurrence challenges. Experimental results show that our method significantly can improves the accuracy of molecular odor prediction across various deep learning models, demonstrating its promising potential in molecular structure representation and chemoinformatics.
The Fusion of Deep Reinforcement Learning and Edge Computing for Real-time Monitoring and Control Optimization in IoT Environments
Feb 28, 2024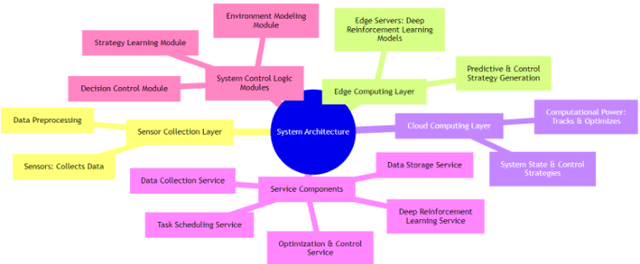
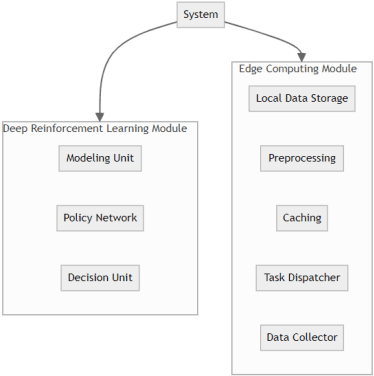
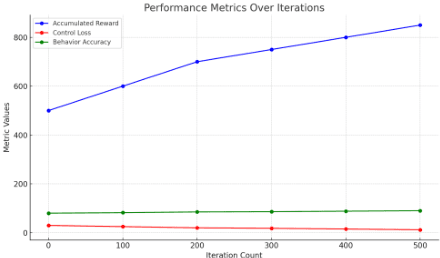

In response to the demand for real-time performance and control quality in industrial Internet of Things (IoT) environments, this paper proposes an optimization control system based on deep reinforcement learning and edge computing. The system leverages cloud-edge collaboration, deploys lightweight policy networks at the edge, predicts system states, and outputs controls at a high frequency, enabling monitoring and optimization of industrial objectives. Additionally, a dynamic resource allocation mechanism is designed to ensure rational scheduling of edge computing resources, achieving global optimization. Results demonstrate that this approach reduces cloud-edge communication latency, accelerates response to abnormal situations, reduces system failure rates, extends average equipment operating time, and saves costs for manual maintenance and replacement. This ensures real-time and stable control.
Ask To The Point: Open-Domain Entity-Centric Question Generation
Oct 21, 2023We introduce a new task called *entity-centric question generation* (ECQG), motivated by real-world applications such as topic-specific learning, assisted reading, and fact-checking. The task aims to generate questions from an entity perspective. To solve ECQG, we propose a coherent PLM-based framework GenCONE with two novel modules: content focusing and question verification. The content focusing module first identifies a focus as "what to ask" to form draft questions, and the question verification module refines the questions afterwards by verifying the answerability. We also construct a large-scale open-domain dataset from SQuAD to support this task. Our extensive experiments demonstrate that GenCONE significantly and consistently outperforms various baselines, and two modules are effective and complementary in generating high-quality questions.
Render-and-Compare: Cross-View 6 DoF Localization from Noisy Prior
Feb 13, 2023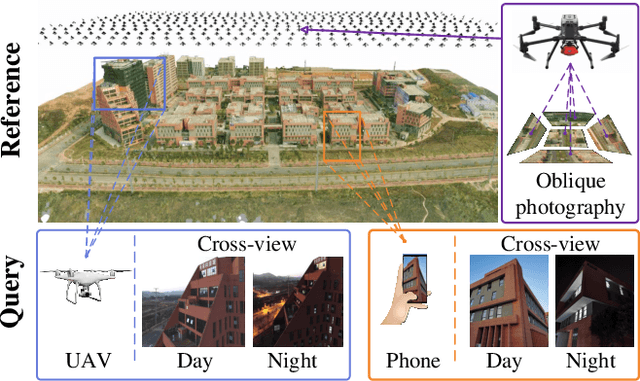



Despite the significant progress in 6-DoF visual localization, researchers are mostly driven by ground-level benchmarks. Compared with aerial oblique photography, ground-level map collection lacks scalability and complete coverage. In this work, we propose to go beyond the traditional ground-level setting and exploit the cross-view localization from aerial to ground. We solve this problem by formulating camera pose estimation as an iterative render-and-compare pipeline and enhancing the robustness through augmenting seeds from noisy initial priors. As no public dataset exists for the studied problem, we collect a new dataset that provides a variety of cross-view images from smartphones and drones and develop a semi-automatic system to acquire ground-truth poses for query images. We benchmark our method as well as several state-of-the-art baselines and demonstrate that our method outperforms other approaches by a large margin.
Learning the Relation between Similarity Loss and Clustering Loss in Self-Supervised Learning
Jan 08, 2023



Self-supervised learning enables networks to learn discriminative features from massive data itself. Most state-of-the-art methods maximize the similarity between two augmentations of one image based on contrastive learning. By utilizing the consistency of two augmentations, the burden of manual annotations can be freed. Contrastive learning exploits instance-level information to learn robust features. However, the learned information is probably confined to different views of the same instance. In this paper, we attempt to leverage the similarity between two distinct images to boost representation in self-supervised learning. In contrast to instance-level information, the similarity between two distinct images may provide more useful information. Besides, we analyze the relation between similarity loss and feature-level cross-entropy loss. These two losses are essential for most deep learning methods. However, the relation between these two losses is not clear. Similarity loss helps obtain instance-level representation, while feature-level cross-entropy loss helps mine the similarity between two distinct images. We provide theoretical analyses and experiments to show that a suitable combination of these two losses can get state-of-the-art results.