 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitC-3DGS: High-Capacity 3D Gaussian Splatting Watermarking via Bit Compression
May 28, 2026High-capacity watermarking is necessary for 3D Gaussian Splatting (3DGS) assets to embed rich information (e.g., ownership, provenance, and authentication codes), enabling reliable identification and integrity verification in large-scale 3D asset pipelines. Existing bit-to-token watermarking methods based on a pre-trained text encoder are limited to 77-bit messages due to CLIP's fixed 77-token context length, as tokens beyond this limit are unsupported by learned positional embeddings. To address this limitation, we introduce BitC-3DGS, a bit-compression framework that encodes multiple message bits per token. It employs a bit-compressed tokenization scheme that encodes multiple bits within the same chunk into a single semantic token. To enable recovery of the compressed information, it further introduces a dual-branch architecture for joint chunk decompression and bit decoding, along with a hard-message sampling strategy to improve combinatorial coverage during decoder training. Extensive experiments on the Blender and LLFF datasets demonstrate the effectiveness of BitC-3DGS for high-capacity watermarking, achieving high message recovery accuracy and rendering fidelity. For example, it supports 128-bit message capacity with recovery accuracy comparable to that of 64-bit messages in recent state-of-the-art methods.
Toward Fine-Grained Facial Control in 3D Talking Head Generation
Feb 10, 2026Audio-driven talking head generation is a core component of digital avatars, and 3D Gaussian Splatting has shown strong performance in real-time rendering of high-fidelity talking heads. However, achieving precise control over fine-grained facial movements remains a significant challenge, particularly due to lip-synchronization inaccuracies and facial jitter, both of which can contribute to the uncanny valley effect. To address these challenges, we propose Fine-Grained 3D Gaussian Splatting (FG-3DGS), a novel framework that enables temporally consistent and high-fidelity talking head generation. Our method introduces a frequency-aware disentanglement strategy to explicitly model facial regions based on their motion characteristics. Low-frequency regions, such as the cheeks, nose, and forehead, are jointly modeled using a standard MLP, while high-frequency regions, including the eyes and mouth, are captured separately using a dedicated network guided by facial area masks. The predicted motion dynamics, represented as Gaussian deltas, are applied to the static Gaussians to generate the final head frames, which are rendered via a rasterizer using frame-specific camera parameters. Additionally, a high-frequency-refined post-rendering alignment mechanism, learned from large-scale audio-video pairs by a pretrained model, is incorporated to enhance per-frame generation and achieve more accurate lip synchronization. Extensive experiments on widely used datasets for talking head generation demonstrate that our method outperforms recent state-of-the-art approaches in producing high-fidelity, lip-synced talking head videos.
A Survey on Small Sample Imbalance Problem: Metrics, Feature Analysis, and Solutions
Apr 21, 2025The small sample imbalance (S&I) problem is a major challenge in machine learning and data analysis. It is characterized by a small number of samples and an imbalanced class distribution, which leads to poor model performance. In addition, indistinct inter-class feature distributions further complicate classification tasks. Existing methods often rely on algorithmic heuristics without sufficiently analyzing the underlying data characteristics. We argue that a detailed analysis from the data perspective is essential before developing an appropriate solution. Therefore, this paper proposes a systematic analytical framework for the S\&I problem. We first summarize imbalance metrics and complexity analysis methods, highlighting the need for interpretable benchmarks to characterize S&I problems. Second, we review recent solutions for conventional, complexity-based, and extreme S&I problems, revealing methodological differences in handling various data distributions. Our summary finds that resampling remains a widely adopted solution. However, we conduct experiments on binary and multiclass datasets, revealing that classifier performance differences significantly exceed the improvements achieved through resampling. Finally, this paper highlights open questions and discusses future trends.
ColorVein: Colorful Cancelable Vein Biometrics
Apr 19, 2025



Vein recognition technologies have become one of the primary solutions for high-security identification systems. However, the issue of biometric information leakage can still pose a serious threat to user privacy and anonymity. Currently, there is no cancelable biometric template generation scheme specifically designed for vein biometrics. Therefore, this paper proposes an innovative cancelable vein biometric generation scheme: ColorVein. Unlike previous cancelable template generation schemes, ColorVein does not destroy the original biometric features and introduces additional color information to grayscale vein images. This method significantly enhances the information density of vein images by transforming static grayscale information into dynamically controllable color representations through interactive colorization. ColorVein allows users/administrators to define a controllable pseudo-random color space for grayscale vein images by editing the position, number, and color of hint points, thereby generating protected cancelable templates. Additionally, we propose a new secure center loss to optimize the training process of the protected feature extraction model, effectively increasing the feature distance between enrolled users and any potential impostors. Finally, we evaluate ColorVein's performance on all types of vein biometrics, including recognition performance, unlinkability, irreversibility, and revocability, and conduct security and privacy analyses. ColorVein achieves competitive performance compared with state-of-the-art methods.
Underwater Organism Color Enhancement via Color Code Decomposition, Adaptation and Interpolation
Sep 29, 2024



Underwater images often suffer from quality degradation due to absorption and scattering effects. Most existing underwater image enhancement algorithms produce a single, fixed-color image, limiting user flexibility and application. To address this limitation, we propose a method called \textit{ColorCode}, which enhances underwater images while offering a range of controllable color outputs. Our approach involves recovering an underwater image to a reference enhanced image through supervised training and decomposing it into color and content codes via self-reconstruction and cross-reconstruction. The color code is explicitly constrained to follow a Gaussian distribution, allowing for efficient sampling and interpolation during inference. ColorCode offers three key features: 1) color enhancement, producing an enhanced image with a fixed color; 2) color adaptation, enabling controllable adjustments of long-wavelength color components using guidance images; and 3) color interpolation, allowing for the smooth generation of multiple colors through continuous sampling of the color code. Quantitative and visual evaluations on popular and challenging benchmark datasets demonstrate the superiority of ColorCode over existing methods in providing diverse, controllable, and color-realistic enhancement results. The source code is available at https://github.com/Xiaofeng-life/ColorCode.
Improving Fast Adversarial Training via Self-Knowledge Guidance
Sep 26, 2024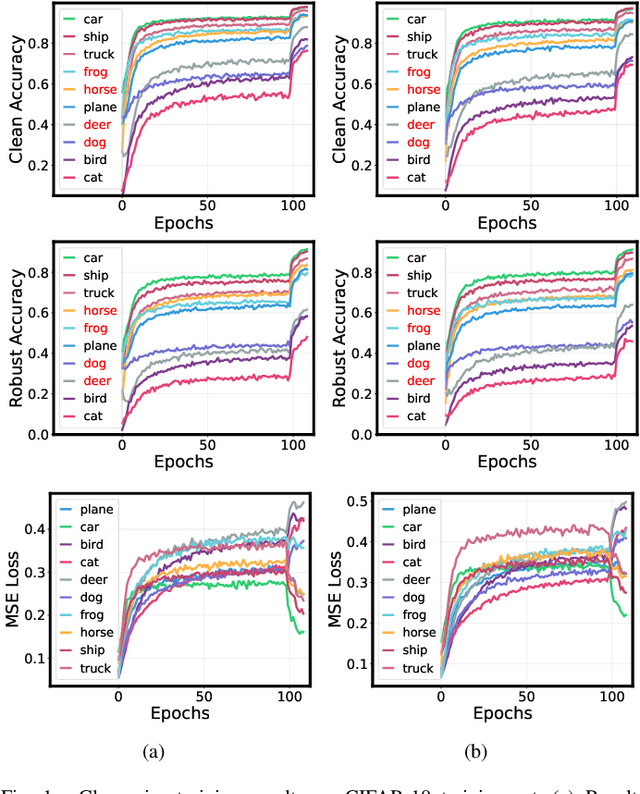
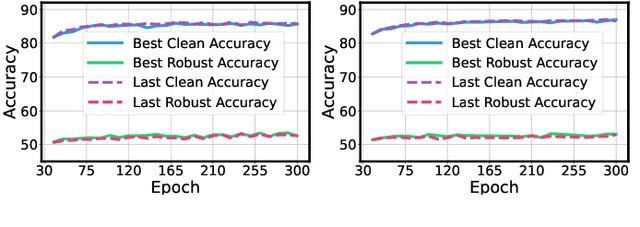
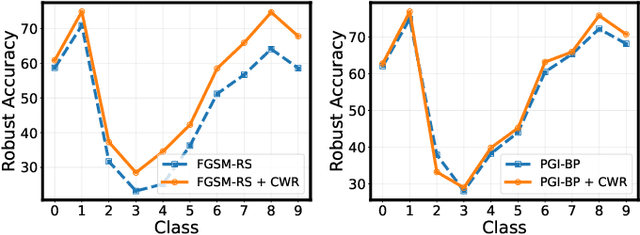
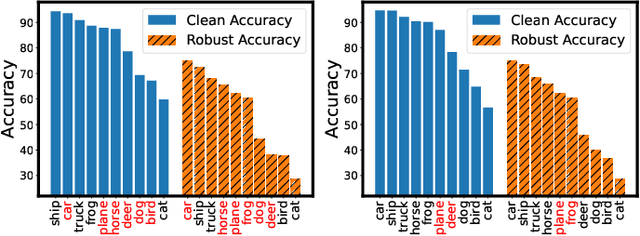
Adversarial training has achieved remarkable advancements in defending against adversarial attacks. Among them, fast adversarial training (FAT) is gaining attention for its ability to achieve competitive robustness with fewer computing resources. Existing FAT methods typically employ a uniform strategy that optimizes all training data equally without considering the influence of different examples, which leads to an imbalanced optimization. However, this imbalance remains unexplored in the field of FAT. In this paper, we conduct a comprehensive study of the imbalance issue in FAT and observe an obvious class disparity regarding their performances. This disparity could be embodied from a perspective of alignment between clean and robust accuracy. Based on the analysis, we mainly attribute the observed misalignment and disparity to the imbalanced optimization in FAT, which motivates us to optimize different training data adaptively to enhance robustness. Specifically, we take disparity and misalignment into consideration. First, we introduce self-knowledge guided regularization, which assigns differentiated regularization weights to each class based on its training state, alleviating class disparity. Additionally, we propose self-knowledge guided label relaxation, which adjusts label relaxation according to the training accuracy, alleviating the misalignment and improving robustness. By combining these methods, we formulate the Self-Knowledge Guided FAT (SKG-FAT), leveraging naturally generated knowledge during training to enhance the adversarial robustness without compromising training efficiency. Extensive experiments on four standard datasets demonstrate that the SKG-FAT improves the robustness and preserves competitive clean accuracy, outperforming the state-of-the-art methods.
Unrevealed Threats: A Comprehensive Study of the Adversarial Robustness of Underwater Image Enhancement Models
Sep 10, 2024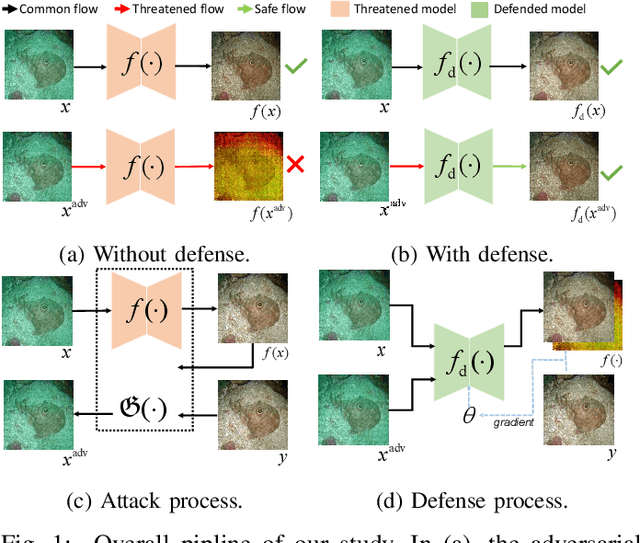


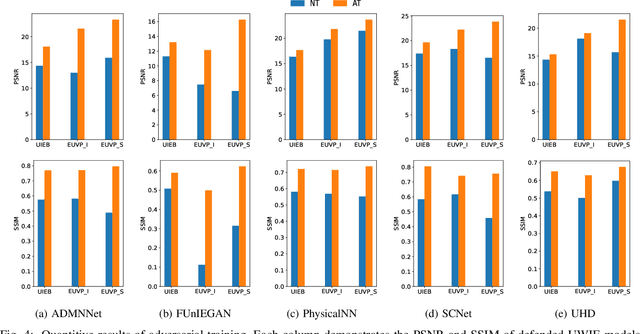
Learning-based methods for underwater image enhancement (UWIE) have undergone extensive exploration. However, learning-based models are usually vulnerable to adversarial examples so as the UWIE models. To the best of our knowledge, there is no comprehensive study on the adversarial robustness of UWIE models, which indicates that UWIE models are potentially under the threat of adversarial attacks. In this paper, we propose a general adversarial attack protocol. We make a first attempt to conduct adversarial attacks on five well-designed UWIE models on three common underwater image benchmark datasets. Considering the scattering and absorption of light in the underwater environment, there exists a strong correlation between color correction and underwater image enhancement. On the basis of that, we also design two effective UWIE-oriented adversarial attack methods Pixel Attack and Color Shift Attack targeting different color spaces. The results show that five models exhibit varying degrees of vulnerability to adversarial attacks and well-designed small perturbations on degraded images are capable of preventing UWIE models from generating enhanced results. Further, we conduct adversarial training on these models and successfully mitigated the effectiveness of adversarial attacks. In summary, we reveal the adversarial vulnerability of UWIE models and propose a new evaluation dimension of UWIE models.
Illumination Controllable Dehazing Network based on Unsupervised Retinex Embedding
Jun 09, 2023



On the one hand, the dehazing task is an illposedness problem, which means that no unique solution exists. On the other hand, the dehazing task should take into account the subjective factor, which is to give the user selectable dehazed images rather than a single result. Therefore, this paper proposes a multi-output dehazing network by introducing illumination controllable ability, called IC-Dehazing. The proposed IC-Dehazing can change the illumination intensity by adjusting the factor of the illumination controllable module, which is realized based on the interpretable Retinex theory. Moreover, the backbone dehazing network of IC-Dehazing consists of a Transformer with double decoders for high-quality image restoration. Further, the prior-based loss function and unsupervised training strategy enable IC-Dehazing to complete the parameter learning process without the need for paired data. To demonstrate the effectiveness of the proposed IC-Dehazing, quantitative and qualitative experiments are conducted on image dehazing, semantic segmentation, and object detection tasks. Code is available at https://github.com/Xiaofeng-life/ICDehazing.
No Place to Hide: Dual Deep Interaction Channel Network for Fake News Detection based on Data Augmentation
Mar 31, 2023



Online Social Network (OSN) has become a hotbed of fake news due to the low cost of information dissemination. Although the existing methods have made many attempts in news content and propagation structure, the detection of fake news is still facing two challenges: one is how to mine the unique key features and evolution patterns, and the other is how to tackle the problem of small samples to build the high-performance model. Different from popular methods which take full advantage of the propagation topology structure, in this paper, we propose a novel framework for fake news detection from perspectives of semantic, emotion and data enhancement, which excavates the emotional evolution patterns of news participants during the propagation process, and a dual deep interaction channel network of semantic and emotion is designed to obtain a more comprehensive and fine-grained news representation with the consideration of comments. Meanwhile, the framework introduces a data enhancement module to obtain more labeled data with high quality based on confidence which further improves the performance of the classification model. Experiments show that the proposed approach outperforms the state-of-the-art methods.
Adversarial Attack and Defense for Dehazing Networks
Mar 30, 2023



The research on single image dehazing task has been widely explored. However, as far as we know, no comprehensive study has been conducted on the robustness of the well-trained dehazing models. Therefore, there is no evidence that the dehazing networks can resist malicious attacks. In this paper, we focus on designing a group of attack methods based on first order gradient to verify the robustness of the existing dehazing algorithms. By analyzing the general goal of image dehazing task, five attack methods are proposed, which are prediction, noise, mask, ground-truth and input attack. The corresponding experiments are conducted on six datasets with different scales. Further, the defense strategy based on adversarial training is adopted for reducing the negative effects caused by malicious attacks. In summary, this paper defines a new challenging problem for image dehazing area, which can be called as adversarial attack on dehazing networks (AADN). Code is available at https://github.com/guijiejie/AADN.