 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Gradient Flow Utility: A Unified Metric for Structural Pruning and Dynamic Routing in Deep Networks
Mar 17, 2026Efficient deep learning traditionally relies on static heuristics like weight magnitude or activation awareness (e.g., Wanda, RIA). While successful in unstructured settings, we observe a critical limitation when applying these metrics to the structural pruning of deep vision networks. These contemporary metrics suffer from a magnitude bias, failing to preserve critical functional pathways. To overcome this, we propose a decoupled kinetic paradigm inspired by Alternating Gradient Flow (AGF), utilizing an absolute feature-space Taylor expansion to accurately capture the network's structural "kinetic utility". First, we uncover a topological phase transition at extreme sparsity, where AGF successfully preserves baseline functionality and exhibits topological implicit regularization, avoiding the collapse seen in models trained from scratch. Second, transitioning to architectures without strict structural priors, we reveal a phenomenon of Sparsity Bottleneck in Vision Transformers (ViTs). Through a gradient-magnitude decoupling analysis, we discover that dynamic signals suffer from signal compression in converged models, rendering them suboptimal for real-time routing. Finally, driven by these empirical constraints, we design a hybrid routing framework that decouples AGF-guided offline structural search from online execution via zero-cost physical priors. We validate our paradigm on large-scale benchmarks: under a 75% compression stress test on ImageNet-1K, AGF effectively avoids the structural collapse where traditional metrics aggressively fall below random sampling. Furthermore, when systematically deployed for dynamic inference on ImageNet-100, our hybrid approach achieves Pareto-optimal efficiency. It reduces the usage of the heavy expert by approximately 50% (achieving an estimated overall cost of 0.92$\times$) without sacrificing the full-model accuracy.
Resource-constrained Amazons chess decision framework integrating large language models and graph attention
Mar 11, 2026Artificial intelligence has advanced significantly through the development of intelligent game-playing systems, providing rigorous testbeds for decision-making, strategic planning, and adaptive learning. However, resource-constrained environments pose critical challenges, as conventional deep learning methods heavily rely on extensive datasets and computational resources. In this paper, we propose a lightweight hybrid framework for the Game of the Amazons, which explores the paradigm of weak-to-strong generalization by integrating the structural reasoning of graph-based learning with the generative capabilities of large language models. Specifically, we leverage a Graph Attention Autoencoder to inform a multi-step Monte Carlo Tree Search, utilize a Stochastic Graph Genetic Algorithm to optimize evaluation signals, and harness GPT-4o-mini to generate synthetic training data. Unlike traditional approaches that rely on expert demonstrations, our framework learns from noisy and imperfect supervision. We demonstrate that the Graph Attention mechanism effectively functions as a structural filter, denoising the LLM's outputs. Experiments on a 10$\times$10 Amazons board show that our hybrid approach not only achieves a 15\%--56\% improvement in decision accuracy over baselines but also significantly outperforms its teacher model (GPT-4o-mini), achieving a competitive win rate of 45.0\% at N=30 nodes and a decisive 66.5\% at only N=50 nodes. These results verify the feasibility of evolving specialized, high-performance game AI from general-purpose foundation models under stringent computational constraints.
Local adapt-then-combine algorithms for distributed nonsmooth optimization: Achieving provable communication acceleration
Feb 18, 2026This paper is concerned with the distributed composite optimization problem over networks, where agents aim to minimize a sum of local smooth components and a common nonsmooth term. Leveraging the probabilistic local updates mechanism, we propose a communication-efficient Adapt-Then-Combine (ATC) framework, FlexATC, unifying numerous ATC-based distributed algorithms. Under stepsizes independent of the network topology and the number of local updates, we establish sublinear and linear convergence rates for FlexATC in convex and strongly convex settings, respectively. Remarkably, in the strong convex setting, the linear rate is decoupled from the objective functions and network topology, and FlexATC permits communication to be skipped in most iterations without any deterioration of the linear rate. In addition, the proposed unified theory demonstrates for the first time that local updates provably lead to communication acceleration for ATC-based distributed algorithms. Numerical experiments further validate the efficacy of the proposed framework and corroborate the theoretical results.
Diversifying Counterattacks: Orthogonal Exploration for Robust CLIP Inference
Nov 12, 2025Vision-language pre-training models (VLPs) demonstrate strong multimodal understanding and zero-shot generalization, yet remain vulnerable to adversarial examples, raising concerns about their reliability. Recent work, Test-Time Counterattack (TTC), improves robustness by generating perturbations that maximize the embedding deviation of adversarial inputs using PGD, pushing them away from their adversarial representations. However, due to the fundamental difference in optimization objectives between adversarial attacks and counterattacks, generating counterattacks solely based on gradients with respect to the adversarial input confines the search to a narrow space. As a result, the counterattacks could overfit limited adversarial patterns and lack the diversity to fully neutralize a broad range of perturbations. In this work, we argue that enhancing the diversity and coverage of counterattacks is crucial to improving adversarial robustness in test-time defense. Accordingly, we propose Directional Orthogonal Counterattack (DOC), which augments counterattack optimization by incorporating orthogonal gradient directions and momentum-based updates. This design expands the exploration of the counterattack space and increases the diversity of perturbations, which facilitates the discovery of more generalizable counterattacks and ultimately improves the ability to neutralize adversarial perturbations. Meanwhile, we present a directional sensitivity score based on averaged cosine similarity to boost DOC by improving example discrimination and adaptively modulating the counterattack strength. Extensive experiments on 16 datasets demonstrate that DOC improves adversarial robustness under various attacks while maintaining competitive clean accuracy. Code is available at https://github.com/bookman233/DOC.
ColorVein: Colorful Cancelable Vein Biometrics
Apr 19, 2025



Vein recognition technologies have become one of the primary solutions for high-security identification systems. However, the issue of biometric information leakage can still pose a serious threat to user privacy and anonymity. Currently, there is no cancelable biometric template generation scheme specifically designed for vein biometrics. Therefore, this paper proposes an innovative cancelable vein biometric generation scheme: ColorVein. Unlike previous cancelable template generation schemes, ColorVein does not destroy the original biometric features and introduces additional color information to grayscale vein images. This method significantly enhances the information density of vein images by transforming static grayscale information into dynamically controllable color representations through interactive colorization. ColorVein allows users/administrators to define a controllable pseudo-random color space for grayscale vein images by editing the position, number, and color of hint points, thereby generating protected cancelable templates. Additionally, we propose a new secure center loss to optimize the training process of the protected feature extraction model, effectively increasing the feature distance between enrolled users and any potential impostors. Finally, we evaluate ColorVein's performance on all types of vein biometrics, including recognition performance, unlinkability, irreversibility, and revocability, and conduct security and privacy analyses. ColorVein achieves competitive performance compared with state-of-the-art methods.
Decentralized Nonconvex Composite Federated Learning with Gradient Tracking and Momentum
Apr 17, 2025Decentralized Federated Learning (DFL) eliminates the reliance on the server-client architecture inherent in traditional federated learning, attracting significant research interest in recent years. Simultaneously, the objective functions in machine learning tasks are often nonconvex and frequently incorporate additional, potentially nonsmooth regularization terms to satisfy practical requirements, thereby forming nonconvex composite optimization problems. Employing DFL methods to solve such general optimization problems leads to the formulation of Decentralized Nonconvex Composite Federated Learning (DNCFL), a topic that remains largely underexplored. In this paper, we propose a novel DNCFL algorithm, termed \bf{DEPOSITUM}. Built upon proximal stochastic gradient tracking, DEPOSITUM mitigates the impact of data heterogeneity by enabling clients to approximate the global gradient. The introduction of momentums in the proximal gradient descent step, replacing tracking variables, reduces the variance introduced by stochastic gradients. Additionally, DEPOSITUM supports local updates of client variables, significantly reducing communication costs. Theoretical analysis demonstrates that DEPOSITUM achieves an expected $\epsilon$-stationary point with an iteration complexity of $\mathcal{O}(1/\epsilon^2)$. The proximal gradient, consensus errors, and gradient estimation errors decrease at a sublinear rate of $\mathcal{O}(1/T)$. With appropriate parameter selection, the algorithm achieves network-independent linear speedup without requiring mega-batch sampling. Finally, we apply DEPOSITUM to the training of neural networks on real-world datasets, systematically examining the influence of various hyperparameters on its performance. Comparisons with other federated composite optimization algorithms validate the effectiveness of the proposed method.
FedCanon: Non-Convex Composite Federated Learning with Efficient Proximal Operation on Heterogeneous Data
Apr 16, 2025Composite federated learning offers a general framework for solving machine learning problems with additional regularization terms. However, many existing methods require clients to perform multiple proximal operations to handle non-smooth terms and their performance are often susceptible to data heterogeneity. To overcome these limitations, we propose a novel composite federated learning algorithm called \textbf{FedCanon}, designed to solve the optimization problems comprising a possibly non-convex loss function and a weakly convex, potentially non-smooth regularization term. By decoupling proximal mappings from local updates, FedCanon requires only a single proximal evaluation on the server per iteration, thereby reducing the overall proximal computation cost. It also introduces control variables that incorporate global gradient information into client updates, which helps mitigate the effects of data heterogeneity. Theoretical analysis demonstrates that FedCanon achieves sublinear convergence rates under general non-convex settings and linear convergence under the Polyak-{\L}ojasiewicz condition, without relying on bounded heterogeneity assumptions. Experiments demonstrate that FedCanon outperforms the state-of-the-art methods in terms of both accuracy and computational efficiency, particularly under heterogeneous data distributions.
Improving Fast Adversarial Training via Self-Knowledge Guidance
Sep 26, 2024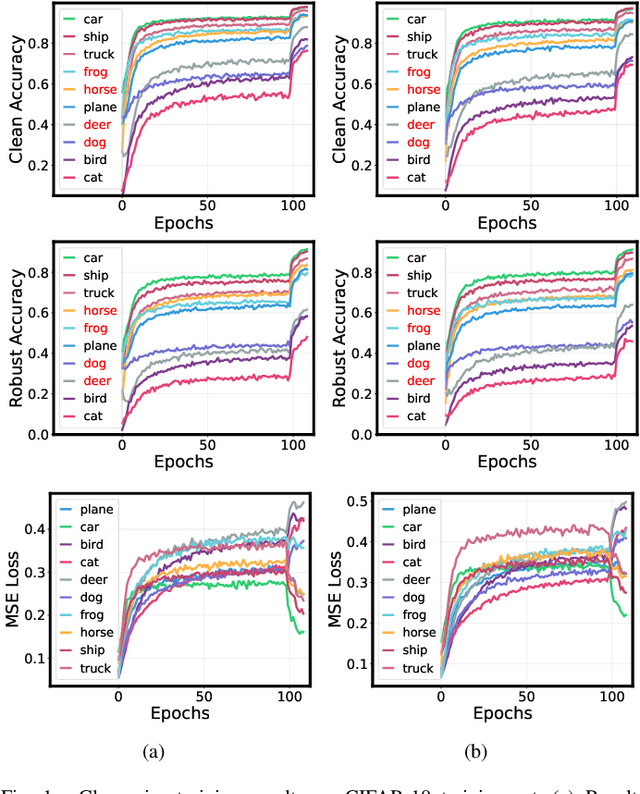
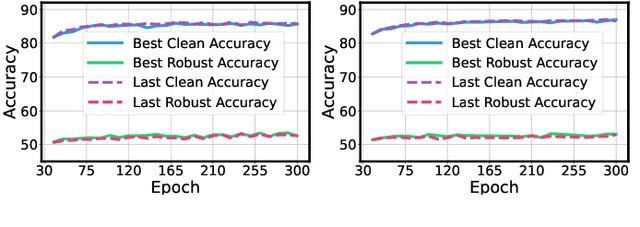
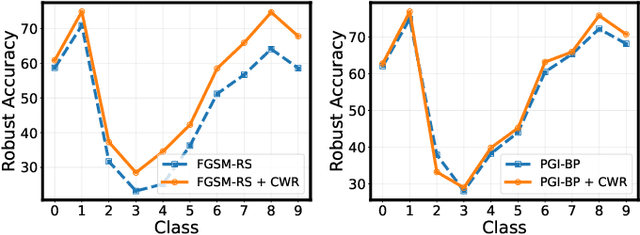
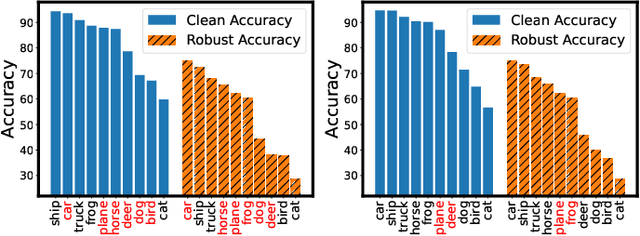
Adversarial training has achieved remarkable advancements in defending against adversarial attacks. Among them, fast adversarial training (FAT) is gaining attention for its ability to achieve competitive robustness with fewer computing resources. Existing FAT methods typically employ a uniform strategy that optimizes all training data equally without considering the influence of different examples, which leads to an imbalanced optimization. However, this imbalance remains unexplored in the field of FAT. In this paper, we conduct a comprehensive study of the imbalance issue in FAT and observe an obvious class disparity regarding their performances. This disparity could be embodied from a perspective of alignment between clean and robust accuracy. Based on the analysis, we mainly attribute the observed misalignment and disparity to the imbalanced optimization in FAT, which motivates us to optimize different training data adaptively to enhance robustness. Specifically, we take disparity and misalignment into consideration. First, we introduce self-knowledge guided regularization, which assigns differentiated regularization weights to each class based on its training state, alleviating class disparity. Additionally, we propose self-knowledge guided label relaxation, which adjusts label relaxation according to the training accuracy, alleviating the misalignment and improving robustness. By combining these methods, we formulate the Self-Knowledge Guided FAT (SKG-FAT), leveraging naturally generated knowledge during training to enhance the adversarial robustness without compromising training efficiency. Extensive experiments on four standard datasets demonstrate that the SKG-FAT improves the robustness and preserves competitive clean accuracy, outperforming the state-of-the-art methods.
MG-Skip: Random Multi-Gossip Skipping Method for Nonsmooth Distributed Optimization
Dec 19, 2023



Distributed optimization methods with probabilistic local updates have recently gained attention for their provable ability to communication acceleration. Nevertheless, this capability is effective only when the loss function is smooth and the network is sufficiently well-connected. In this paper, we propose the first linear convergent method MG-Skip with probabilistic local updates for nonsmooth distributed optimization. Without any extra condition for the network connectivity, MG-Skip allows for the multiple-round gossip communication to be skipped in most iterations, while its iteration complexity is $\mathcal{O}\left(\kappa \log \frac{1}{\epsilon}\right)$ and communication complexity is only $\mathcal{O}\left(\sqrt{\frac{\kappa}{(1-\rho)}} \log \frac{1}{\epsilon}\right)$, where $\kappa$ is the condition number of the loss function and $\rho$ reflects the connectivity of the network topology. To the best of our knowledge, MG-Skip achieves the best communication complexity when the loss function has the smooth (strongly convex)+nonsmooth (convex) composite form.
A data-driven rutting depth short-time prediction model with metaheuristic optimization for asphalt pavements based on RIOHTrack
May 11, 2023



Rutting of asphalt pavements is a crucial design criterion in various pavement design guides. A good road transportation base can provide security for the transportation of oil and gas in road transportation. This study attempts to develop a robust artificial intelligence model to estimate different asphalt pavements' rutting depth clips, temperature, and load axes as primary characteristics. The experiment data were obtained from 19 asphalt pavements with different crude oil sources on a 2.038 km long full-scale field accelerated pavement test track (RIOHTrack, Road Track Institute) in Tongzhou, Beijing. In addition, this paper also proposes to build complex networks with different pavement rutting depths through complex network methods and the Louvain algorithm for community detection. The most critical structural elements can be selected from different asphalt pavement rutting data, and similar structural elements can be found. An extreme learning machine algorithm with residual correction (RELM) is designed and optimized using an independent adaptive particle swarm algorithm. The experimental results of the proposed method are compared with several classical machine learning algorithms, with predictions of Average Root Mean Squared Error, Average Mean Absolute Error, and Average Mean Absolute Percentage Error for 19 asphalt pavements reaching 1.742, 1.363, and 1.94\% respectively. The experiments demonstrate that the RELM algorithm has an advantage over classical machine learning methods in dealing with non-linear problems in road engineering. Notably, the method ensures the adaptation of the simulated environment to different levels of abstraction through the cognitive analysis of the production environment parameters.