 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Narrative Review on Large AI Models in Lung Cancer Screening, Diagnosis, and Treatment Planning
Jun 08, 2025Lung cancer remains one of the most prevalent and fatal diseases worldwide, demanding accurate and timely diagnosis and treatment. Recent advancements in large AI models have significantly enhanced medical image understanding and clinical decision-making. This review systematically surveys the state-of-the-art in applying large AI models to lung cancer screening, diagnosis, prognosis, and treatment. We categorize existing models into modality-specific encoders, encoder-decoder frameworks, and joint encoder architectures, highlighting key examples such as CLIP, BLIP, Flamingo, BioViL-T, and GLoRIA. We further examine their performance in multimodal learning tasks using benchmark datasets like LIDC-IDRI, NLST, and MIMIC-CXR. Applications span pulmonary nodule detection, gene mutation prediction, multi-omics integration, and personalized treatment planning, with emerging evidence of clinical deployment and validation. Finally, we discuss current limitations in generalizability, interpretability, and regulatory compliance, proposing future directions for building scalable, explainable, and clinically integrated AI systems. Our review underscores the transformative potential of large AI models to personalize and optimize lung cancer care.
Decentralized Nonconvex Composite Federated Learning with Gradient Tracking and Momentum
Apr 17, 2025Decentralized Federated Learning (DFL) eliminates the reliance on the server-client architecture inherent in traditional federated learning, attracting significant research interest in recent years. Simultaneously, the objective functions in machine learning tasks are often nonconvex and frequently incorporate additional, potentially nonsmooth regularization terms to satisfy practical requirements, thereby forming nonconvex composite optimization problems. Employing DFL methods to solve such general optimization problems leads to the formulation of Decentralized Nonconvex Composite Federated Learning (DNCFL), a topic that remains largely underexplored. In this paper, we propose a novel DNCFL algorithm, termed \bf{DEPOSITUM}. Built upon proximal stochastic gradient tracking, DEPOSITUM mitigates the impact of data heterogeneity by enabling clients to approximate the global gradient. The introduction of momentums in the proximal gradient descent step, replacing tracking variables, reduces the variance introduced by stochastic gradients. Additionally, DEPOSITUM supports local updates of client variables, significantly reducing communication costs. Theoretical analysis demonstrates that DEPOSITUM achieves an expected $\epsilon$-stationary point with an iteration complexity of $\mathcal{O}(1/\epsilon^2)$. The proximal gradient, consensus errors, and gradient estimation errors decrease at a sublinear rate of $\mathcal{O}(1/T)$. With appropriate parameter selection, the algorithm achieves network-independent linear speedup without requiring mega-batch sampling. Finally, we apply DEPOSITUM to the training of neural networks on real-world datasets, systematically examining the influence of various hyperparameters on its performance. Comparisons with other federated composite optimization algorithms validate the effectiveness of the proposed method.
FedCanon: Non-Convex Composite Federated Learning with Efficient Proximal Operation on Heterogeneous Data
Apr 16, 2025Composite federated learning offers a general framework for solving machine learning problems with additional regularization terms. However, many existing methods require clients to perform multiple proximal operations to handle non-smooth terms and their performance are often susceptible to data heterogeneity. To overcome these limitations, we propose a novel composite federated learning algorithm called \textbf{FedCanon}, designed to solve the optimization problems comprising a possibly non-convex loss function and a weakly convex, potentially non-smooth regularization term. By decoupling proximal mappings from local updates, FedCanon requires only a single proximal evaluation on the server per iteration, thereby reducing the overall proximal computation cost. It also introduces control variables that incorporate global gradient information into client updates, which helps mitigate the effects of data heterogeneity. Theoretical analysis demonstrates that FedCanon achieves sublinear convergence rates under general non-convex settings and linear convergence under the Polyak-{\L}ojasiewicz condition, without relying on bounded heterogeneity assumptions. Experiments demonstrate that FedCanon outperforms the state-of-the-art methods in terms of both accuracy and computational efficiency, particularly under heterogeneous data distributions.
Multi-Scale Occ: 4th Place Solution for CVPR 2023 3D Occupancy Prediction Challenge
Jun 20, 2023In this report, we present the 4th place solution for CVPR 2023 3D occupancy prediction challenge. We propose a simple method called Multi-Scale Occ for occupancy prediction based on lift-splat-shoot framework, which introduces multi-scale image features for generating better multi-scale 3D voxel features with temporal fusion of multiple past frames. Post-processing including model ensemble, test-time augmentation, and class-wise thresh are adopted to further boost the final performance. As shown on the leaderboard, our proposed occupancy prediction method ranks the 4th place with 49.36 mIoU.
Understanding the Robustness of 3D Object Detection with Bird's-Eye-View Representations in Autonomous Driving
Mar 30, 20233D object detection is an essential perception task in autonomous driving to understand the environments. The Bird's-Eye-View (BEV) representations have significantly improved the performance of 3D detectors with camera inputs on popular benchmarks. However, there still lacks a systematic understanding of the robustness of these vision-dependent BEV models, which is closely related to the safety of autonomous driving systems. In this paper, we evaluate the natural and adversarial robustness of various representative models under extensive settings, to fully understand their behaviors influenced by explicit BEV features compared with those without BEV. In addition to the classic settings, we propose a 3D consistent patch attack by applying adversarial patches in the 3D space to guarantee the spatiotemporal consistency, which is more realistic for the scenario of autonomous driving. With substantial experiments, we draw several findings: 1) BEV models tend to be more stable than previous methods under different natural conditions and common corruptions due to the expressive spatial representations; 2) BEV models are more vulnerable to adversarial noises, mainly caused by the redundant BEV features; 3) Camera-LiDAR fusion models have superior performance under different settings with multi-modal inputs, but BEV fusion model is still vulnerable to adversarial noises of both point cloud and image. These findings alert the safety issue in the applications of BEV detectors and could facilitate the development of more robust models.
WS-3D-Lane: Weakly Supervised 3D Lane Detection With 2D Lane Labels
Sep 23, 2022
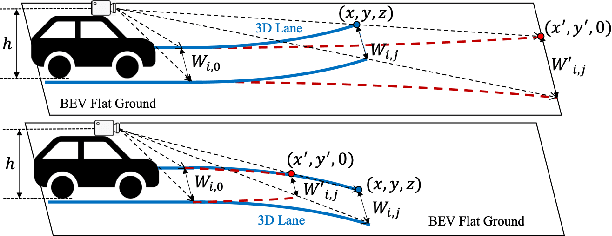
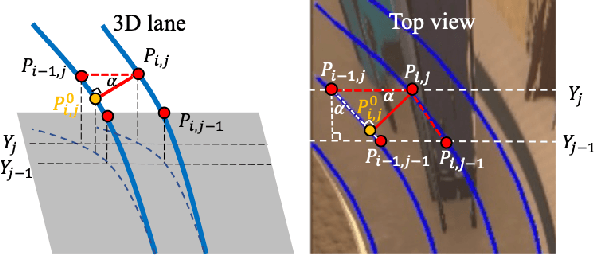

Compared to 2D lanes, real 3D lane data is difficult to collect accurately. In this paper, we propose a novel method for training 3D lanes with only 2D lane labels, called weakly supervised 3D lane detection WS-3D-Lane. By assumptions of constant lane width and equal height on adjacent lanes, we indirectly supervise 3D lane heights in the training. To overcome the problem of the dynamic change of the camera pitch during data collection, a camera pitch self-calibration method is proposed. In anchor representation, we propose a double-layer anchor with a improved non-maximum suppression (NMS) method, which enables the anchor-based method to predict two lane lines that are close. Experiments are conducted on the base of 3D-LaneNet under two supervision methods. Under weakly supervised setting, our WS-3D-Lane outperforms previous 3D-LaneNet: F-score rises to 92.3% on Apollo 3D synthetic dataset, and F1 rises to 74.5% on ONCE-3DLanes. Meanwhile, WS-3D-Lane in purely supervised setting makes more increments and outperforms state-of-the-art. To the best of our knowledge, WS-3D-Lane is the first try of 3D lane detection under weakly supervised setting.
DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks
Feb 15, 2022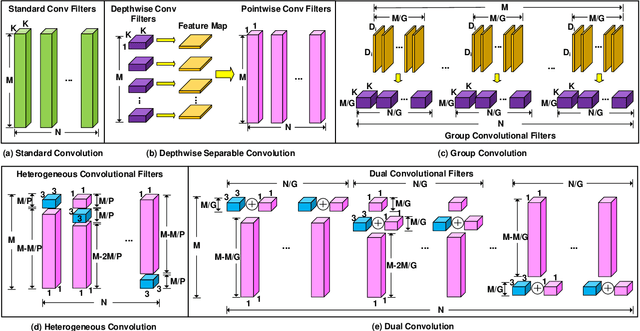
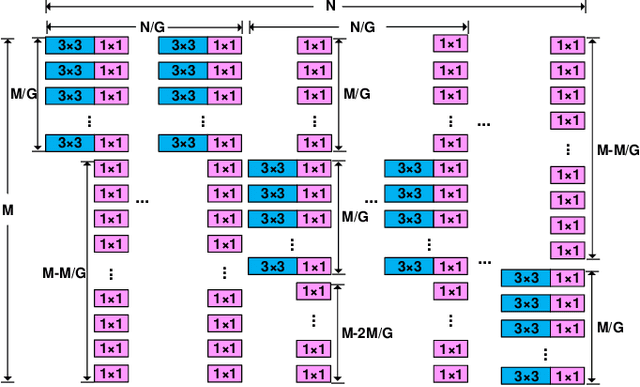
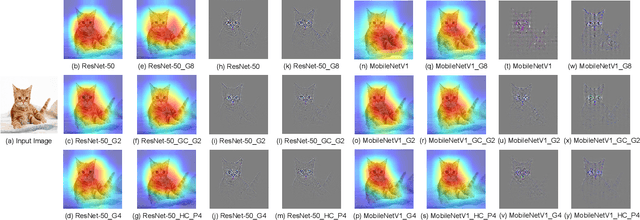
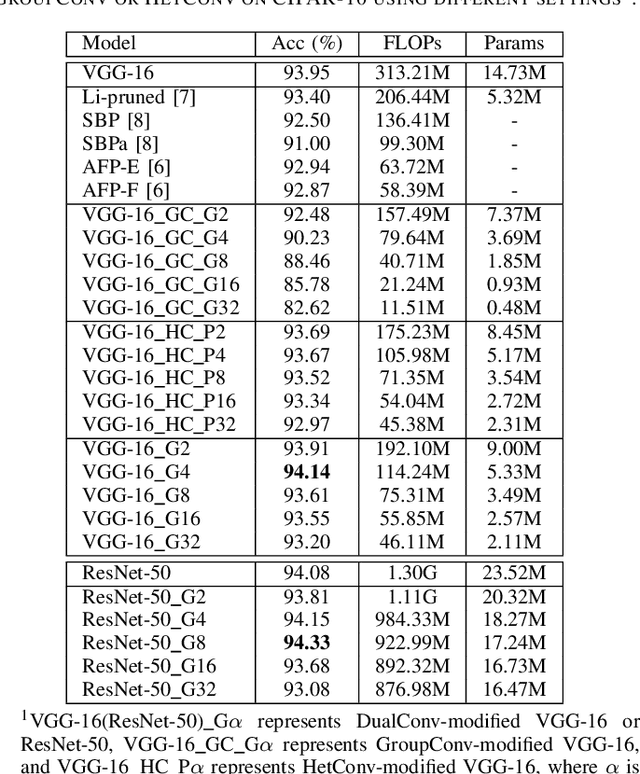
CNN architectures are generally heavy on memory and computational requirements which makes them infeasible for embedded systems with limited hardware resources. We propose dual convolutional kernels (DualConv) for constructing lightweight deep neural networks. DualConv combines 3$\times$3 and 1$\times$1 convolutional kernels to process the same input feature map channels simultaneously and exploits the group convolution technique to efficiently arrange convolutional filters. DualConv can be employed in any CNN model such as VGG-16 and ResNet-50 for image classification, YOLO and R-CNN for object detection, or FCN for semantic segmentation. In this paper, we extensively test DualConv for classification since these network architectures form the backbones for many other tasks. We also test DualConv for image detection on YOLO-V3. Experimental results show that, combined with our structural innovations, DualConv significantly reduces the computational cost and number of parameters of deep neural networks while surprisingly achieving slightly higher accuracy than the original models in some cases. We use DualConv to further reduce the number of parameters of the lightweight MobileNetV2 by 54% with only 0.68% drop in accuracy on CIFAR-100 dataset. When the number of parameters is not an issue, DualConv increases the accuracy of MobileNetV1 by 4.11% on the same dataset. Furthermore, DualConv significantly improves the YOLO-V3 object detection speed and improves its accuracy by 4.4% on PASCAL VOC dataset.
Improving the Speed and Quality of GAN by Adversarial Training
Aug 07, 2020
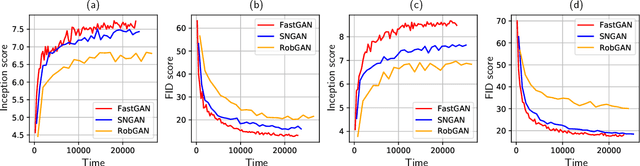
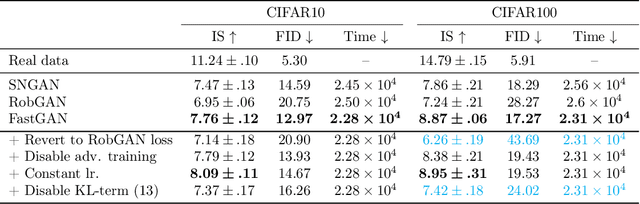

Generative adversarial networks (GAN) have shown remarkable results in image generation tasks. High fidelity class-conditional GAN methods often rely on stabilization techniques by constraining the global Lipschitz continuity. Such regularization leads to less expressive models and slower convergence speed; other techniques, such as the large batch training, require unconventional computing power and are not widely accessible. In this paper, we develop an efficient algorithm, namely FastGAN (Free AdverSarial Training), to improve the speed and quality of GAN training based on the adversarial training technique. We benchmark our method on CIFAR10, a subset of ImageNet, and the full ImageNet datasets. We choose strong baselines such as SNGAN and SAGAN; the results demonstrate that our training algorithm can achieve better generation quality (in terms of the Inception score and Frechet Inception distance) with less overall training time. Most notably, our training algorithm brings ImageNet training to the broader public by requiring 2-4 GPUs.