 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
Learning LLM Preference over Intra-Dialogue Pairs: A Framework for Utterance-level Understandings
Mar 07, 2025

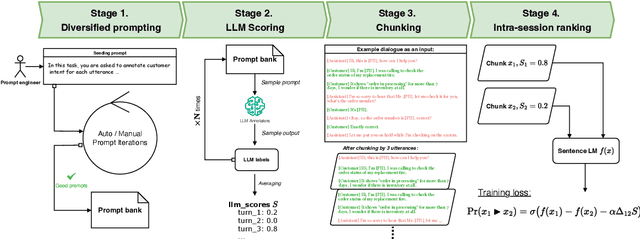

Large language models (LLMs) have demonstrated remarkable capabilities in handling complex dialogue tasks without requiring use case-specific fine-tuning. However, analyzing live dialogues in real-time necessitates low-latency processing systems, making it impractical to deploy models with billions of parameters due to latency constraints. As a result, practitioners often prefer smaller models with millions of parameters, trained on high-quality, human-annotated datasets. Yet, curating such datasets is both time-consuming and costly. Consequently, there is a growing need to combine the scalability of LLM-generated labels with the precision of human annotations, enabling fine-tuned smaller models to achieve both higher speed and accuracy comparable to larger models. In this paper, we introduce a simple yet effective framework to address this challenge. Our approach is specifically designed for per-utterance classification problems, which encompass tasks such as intent detection, dialogue state tracking, and more. To mitigate the impact of labeling errors from LLMs -- the primary source of inaccuracies in student models -- we propose a noise-reduced preference learning loss. Experimental results demonstrate that our method significantly improves accuracy across utterance-level dialogue tasks, including sentiment detection (over $2\%$), dialogue act classification (over $1.5\%$), etc.
GRAM: Generative Retrieval Augmented Matching of Data Schemas in the Context of Data Security
Jun 04, 2024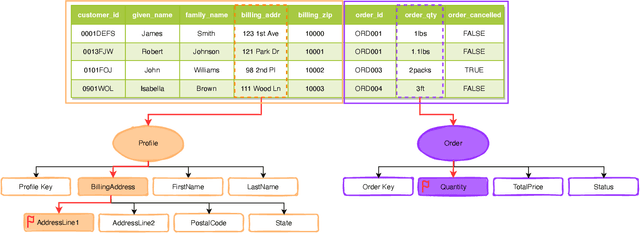
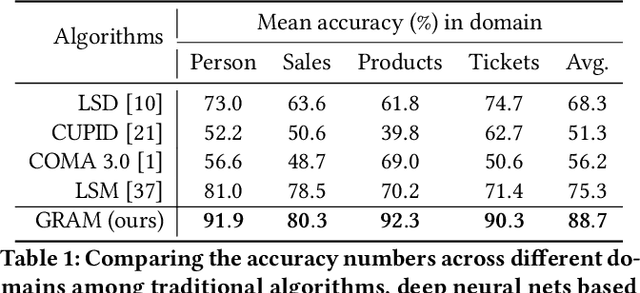

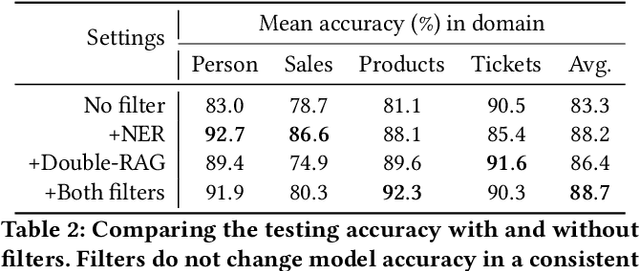
Schema matching constitutes a pivotal phase in the data ingestion process for contemporary database systems. Its objective is to discern pairwise similarities between two sets of attributes, each associated with a distinct data table. This challenge emerges at the initial stages of data analytics, such as when incorporating a third-party table into existing databases to inform business insights. Given its significance in the realm of database systems, schema matching has been under investigation since the 2000s. This study revisits this foundational problem within the context of large language models. Adhering to increasingly stringent data security policies, our focus lies on the zero-shot and few-shot scenarios: the model should analyze only a minimal amount of customer data to execute the matching task, contrasting with the conventional approach of scrutinizing the entire data table. We emphasize that the zero-shot or few-shot assumption is imperative to safeguard the identity and privacy of customer data, even at the potential cost of accuracy. The capability to accurately match attributes under such stringent requirements distinguishes our work from previous literature in this domain.
Stochastic Optimization for Non-convex Problem with Inexact Hessian Matrix, Gradient, and Function
Oct 18, 2023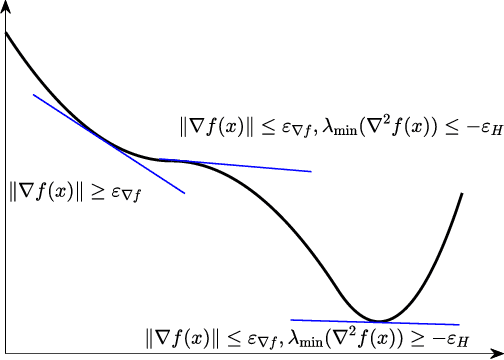
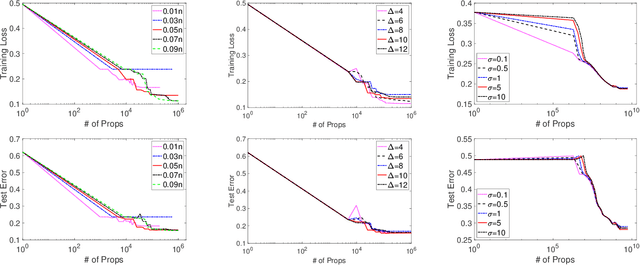
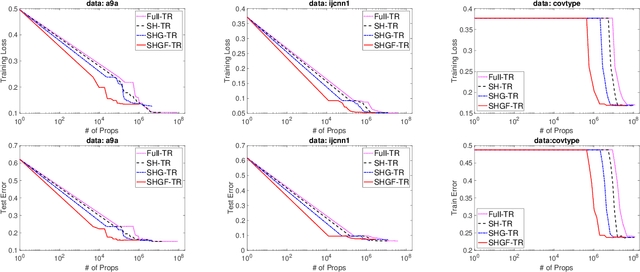
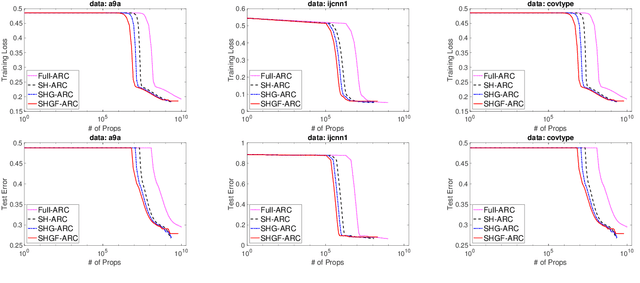
Trust-region (TR) and adaptive regularization using cubics (ARC) have proven to have some very appealing theoretical properties for non-convex optimization by concurrently computing function value, gradient, and Hessian matrix to obtain the next search direction and the adjusted parameters. Although stochastic approximations help largely reduce the computational cost, it is challenging to theoretically guarantee the convergence rate. In this paper, we explore a family of stochastic TR and ARC methods that can simultaneously provide inexact computations of the Hessian matrix, gradient, and function values. Our algorithms require much fewer propagations overhead per iteration than TR and ARC. We prove that the iteration complexity to achieve $\epsilon$-approximate second-order optimality is of the same order as the exact computations demonstrated in previous studies. Additionally, the mild conditions on inexactness can be met by leveraging a random sampling technology in the finite-sum minimization problem. Numerical experiments with a non-convex problem support these findings and demonstrate that, with the same or a similar number of iterations, our algorithms require less computational overhead per iteration than current second-order methods.
Label Disentanglement in Partition-based Extreme Multilabel Classification
Jun 24, 2021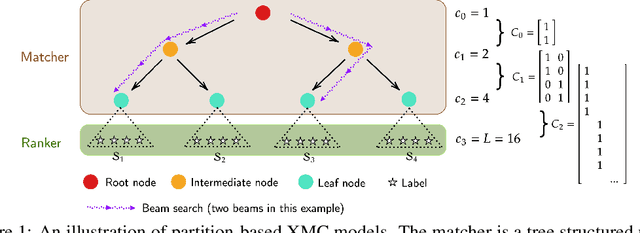
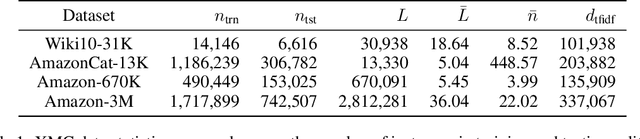
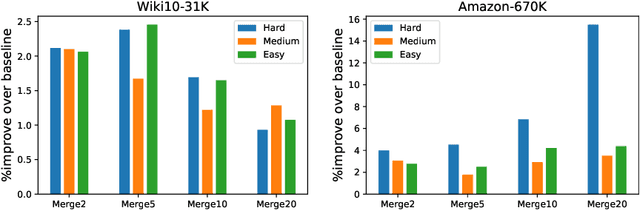
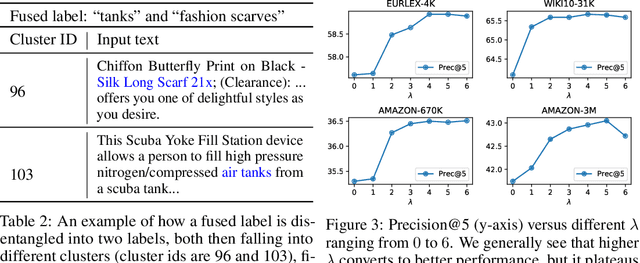
Partition-based methods are increasingly-used in extreme multi-label classification (XMC) problems due to their scalability to large output spaces (e.g., millions or more). However, existing methods partition the large label space into mutually exclusive clusters, which is sub-optimal when labels have multi-modality and rich semantics. For instance, the label "Apple" can be the fruit or the brand name, which leads to the following research question: can we disentangle these multi-modal labels with non-exclusive clustering tailored for downstream XMC tasks? In this paper, we show that the label assignment problem in partition-based XMC can be formulated as an optimization problem, with the objective of maximizing precision rates. This leads to an efficient algorithm to form flexible and overlapped label clusters, and a method that can alternatively optimizes the cluster assignments and the model parameters for partition-based XMC. Experimental results on synthetic and real datasets show that our method can successfully disentangle multi-modal labels, leading to state-of-the-art (SOTA) results on four XMC benchmarks.
How much progress have we made in neural network training? A New Evaluation Protocol for Benchmarking Optimizers
Oct 19, 2020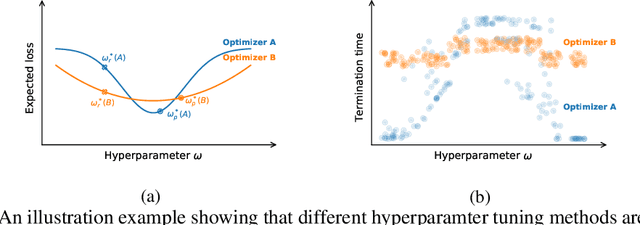

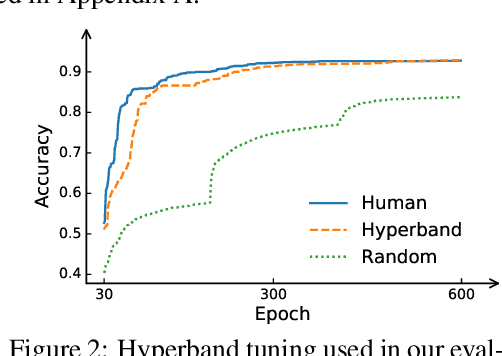
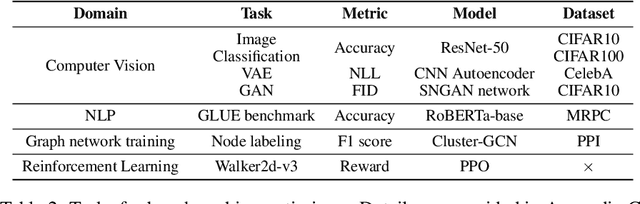
Many optimizers have been proposed for training deep neural networks, and they often have multiple hyperparameters, which make it tricky to benchmark their performance. In this work, we propose a new benchmarking protocol to evaluate both end-to-end efficiency (training a model from scratch without knowing the best hyperparameter) and data-addition training efficiency (the previously selected hyperparameters are used for periodically re-training the model with newly collected data). For end-to-end efficiency, unlike previous work that assumes random hyperparameter tuning, which over-emphasizes the tuning time, we propose to evaluate with a bandit hyperparameter tuning strategy. A human study is conducted to show that our evaluation protocol matches human tuning behavior better than the random search. For data-addition training, we propose a new protocol for assessing the hyperparameter sensitivity to data shift. We then apply the proposed benchmarking framework to 7 optimizers and various tasks, including computer vision, natural language processing, reinforcement learning, and graph mining. Our results show that there is no clear winner across all the tasks.
Improving the Speed and Quality of GAN by Adversarial Training
Aug 07, 2020
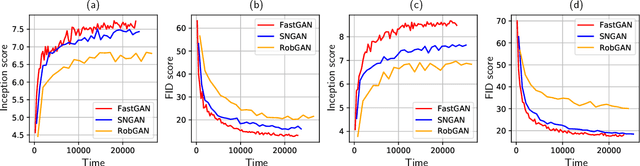
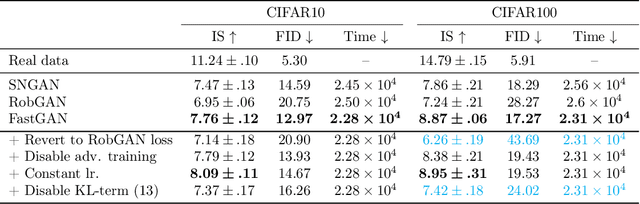

Generative adversarial networks (GAN) have shown remarkable results in image generation tasks. High fidelity class-conditional GAN methods often rely on stabilization techniques by constraining the global Lipschitz continuity. Such regularization leads to less expressive models and slower convergence speed; other techniques, such as the large batch training, require unconventional computing power and are not widely accessible. In this paper, we develop an efficient algorithm, namely FastGAN (Free AdverSarial Training), to improve the speed and quality of GAN training based on the adversarial training technique. We benchmark our method on CIFAR10, a subset of ImageNet, and the full ImageNet datasets. We choose strong baselines such as SNGAN and SAGAN; the results demonstrate that our training algorithm can achieve better generation quality (in terms of the Inception score and Frechet Inception distance) with less overall training time. Most notably, our training algorithm brings ImageNet training to the broader public by requiring 2-4 GPUs.
Provably Robust Metric Learning
Jun 12, 2020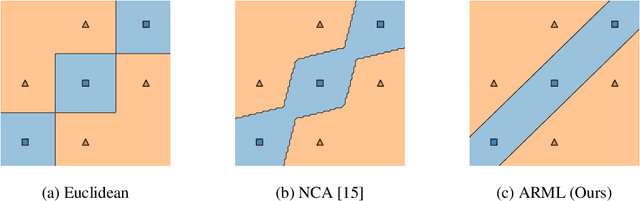
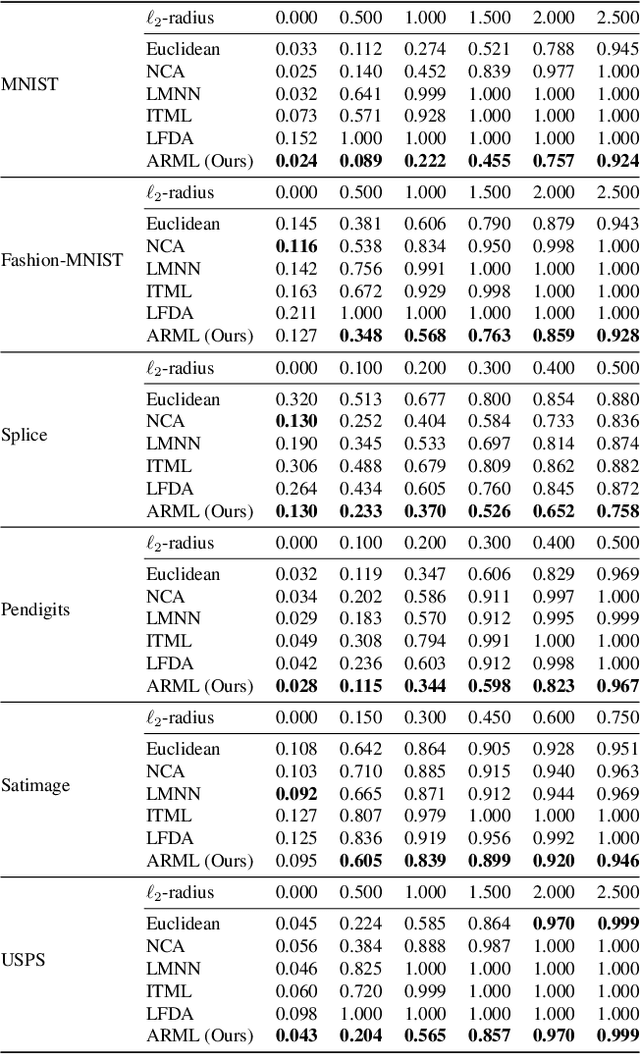
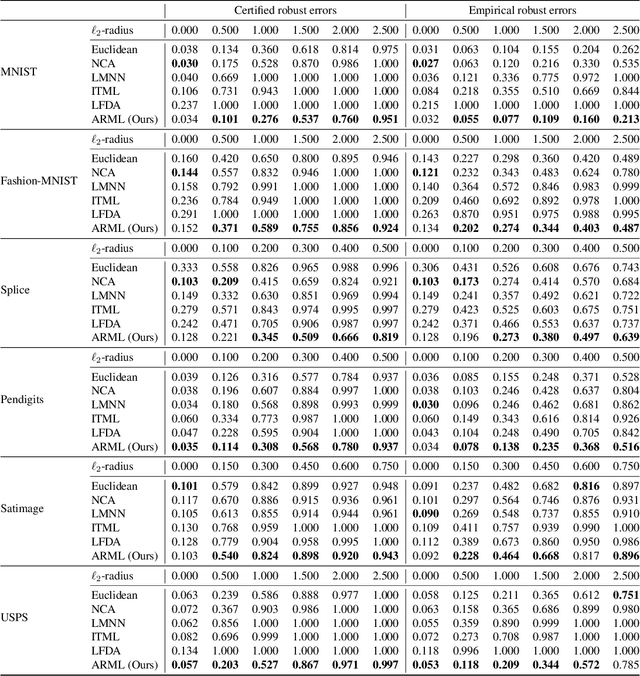
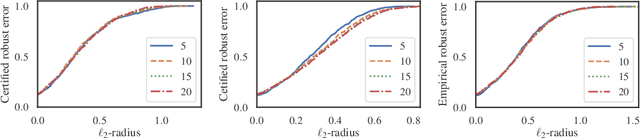
Metric learning is an important family of algorithms for classification and similarity search, but the robustness of learned metrics against small adversarial perturbations is less studied. In this paper, we show that existing metric learning algorithms, which focus on boosting the clean accuracy, can result in metrics that are less robust than the Euclidean distance. To overcome this problem, we propose a novel metric learning algorithm to find a Mahalanobis distance that is robust against adversarial perturbations, and the robustness of the resulting model is certifiable. Experimental results show that the proposed metric learning algorithm improves both certified robust errors and empirical robust errors (errors under adversarial attacks). Furthermore, unlike neural network defenses which usually encounter a trade-off between clean and robust errors, our method does not sacrifice clean errors compared with previous metric learning methods. Our code is available at https://github.com/wangwllu/provably_robust_metric_learning.
Evaluations and Methods for Explanation through Robustness Analysis
May 31, 2020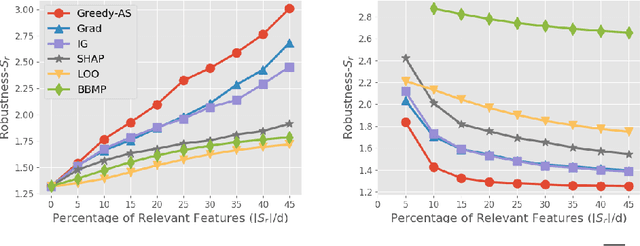


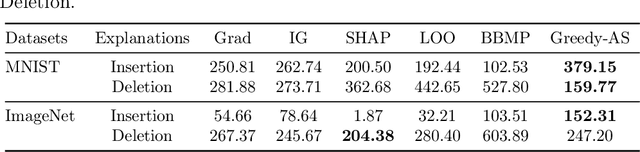
Among multiple ways of interpreting a machine learning model, measuring the importance of a set of features tied to a prediction is probably one of the most intuitive ways to explain a model. In this paper, we establish the link between a set of features to a prediction with a new evaluation criterion, robustness analysis, which measures the minimum distortion distance of adversarial perturbation. By measuring the tolerance level for an adversarial attack, we can extract a set of features that provides the most robust support for a prediction, and also can extract a set of features that contrasts the current prediction to a target class by setting a targeted adversarial attack. By applying this methodology to various prediction tasks across multiple domains, we observe the derived explanations are indeed capturing the significant feature set qualitatively and quantitatively.
Learning to Encode Position for Transformer with Continuous Dynamical Model
Mar 13, 2020
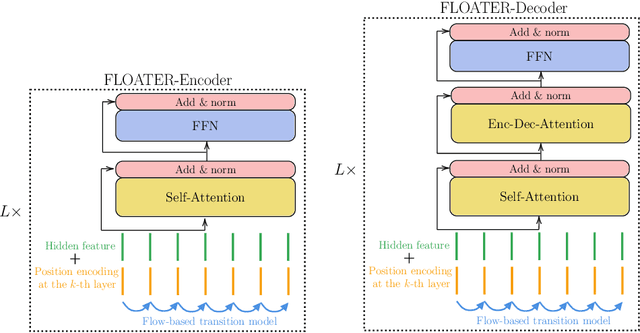
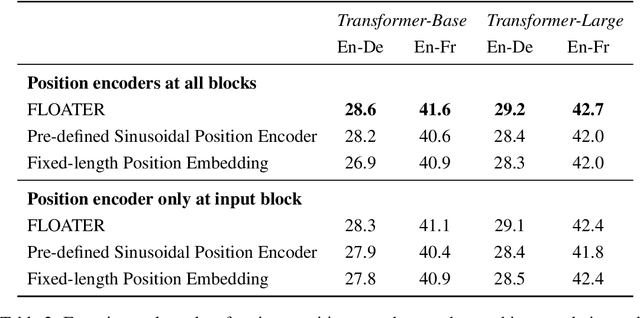
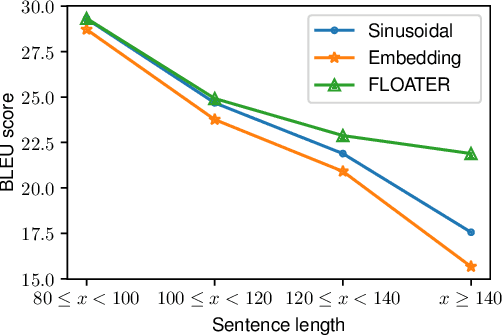
We introduce a new way of learning to encode position information for non-recurrent models, such as Transformer models. Unlike RNN and LSTM, which contain inductive bias by loading the input tokens sequentially, non-recurrent models are less sensitive to position. The main reason is that position information among input units is not inherently encoded, i.e., the models are permutation equivalent; this problem justifies why all of the existing models are accompanied by a sinusoidal encoding/embedding layer at the input. However, this solution has clear limitations: the sinusoidal encoding is not flexible enough as it is manually designed and does not contain any learnable parameters, whereas the position embedding restricts the maximum length of input sequences. It is thus desirable to design a new position layer that contains learnable parameters to adjust to different datasets and different architectures. At the same time, we would also like the encodings to extrapolate in accordance with the variable length of inputs. In our proposed solution, we borrow from the recent Neural ODE approach, which may be viewed as a versatile continuous version of a ResNet. This model is capable of modeling many kinds of dynamical systems. We model the evolution of encoded results along position index by such a dynamical system, thereby overcoming the above limitations of existing methods. We evaluate our new position layers on a variety of neural machine translation and language understanding tasks, the experimental results show consistent improvements over the baselines.