 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneTeract: Agentic Functional Affordances and VLM Grounding in 3D Scenes
Mar 31, 2026Embodied AI depends on interactive 3D environments that support meaningful activities for diverse users, yet assessing their functional affordances remains a core challenge. We introduce SceneTeract, a framework that verifies 3D scene functionality under agent-specific constraints. Our core contribution is a grounded verification engine that couples high-level semantic reasoning with low-level geometric checks. SceneTeract decomposes complex activities into sequences of atomic actions and validates each step against accessibility requirements (e.g., reachability, clearance, and navigability) conditioned on an embodied agent profile, using explicit physical and geometric simulations. We deploy SceneTeract to perform an in-depth evaluation of (i) synthetic indoor environments, uncovering frequent functional failures that prevent basic interactions, and (ii) the ability of frontier Vision-Language Models (VLMs) to reason about and predict functional affordances, revealing systematic mismatches between semantic confidence and physical feasibility even for the strongest current models. Finally, we leverage SceneTeract as a reward engine for VLM post-training, enabling scalable distillation of geometric constraints into reasoning models. We release the SceneTeract verification suite and data to bridge perception and physical reality in embodied 3D scene understanding.
SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
CAMEL: Confidence-Gated Reflection for Reward Modeling
Feb 24, 2026Reward models play a fundamental role in aligning large language models with human preferences. Existing methods predominantly follow two paradigms: scalar discriminative preference models, which are efficient but lack interpretability, and generative judging models, which offer richer reasoning at the cost of higher computational overhead. We observe that the log-probability margin between verdict tokens strongly correlates with prediction correctness, providing a reliable proxy for instance difficulty without additional inference cost. Building on this insight, we propose CAMEL, a confidence-gated reflection framework that performs a lightweight single-token preference decision first and selectively invokes reflection only for low-confidence instances. To induce effective self-correction, we train the model via reinforcement learning with counterfactual prefix augmentation, which exposes the model to diverse initial verdicts and encourages genuine revision. Empirically, CAMEL achieves state-of-the-art performance on three widely used reward-model benchmarks with 82.9% average accuracy, surpassing the best prior model by 3.2% and outperforming 70B-parameter models using only 14B parameters, while establishing a strictly better accuracy-efficiency Pareto frontier.
Learning Physical Principles from Interaction: Self-Evolving Planning via Test-Time Memory
Feb 23, 2026Reliable object manipulation requires understanding physical properties that vary across objects and environments. Vision-language model (VLM) planners can reason about friction and stability in general terms; however, they often cannot predict how a specific ball will roll on a particular surface or which stone will provide a stable foundation without direct experience. We present PhysMem, a memory framework that enables VLM robot planners to learn physical principles from interaction at test time, without updating model parameters. The system records experiences, generates candidate hypotheses, and verifies them through targeted interaction before promoting validated knowledge to guide future decisions. A central design choice is verification before application: the system tests hypotheses against new observations rather than applying retrieved experience directly, reducing rigid reliance on prior experience when physical conditions change. We evaluate PhysMem on three real-world manipulation tasks and simulation benchmarks across four VLM backbones. On a controlled brick insertion task, principled abstraction achieves 76% success compared to 23% for direct experience retrieval, and real-world experiments show consistent improvement over 30-minute deployment sessions.
HBVLA: Pushing 1-Bit Post-Training Quantization for Vision-Language-Action Models
Feb 14, 2026Vision-Language-Action (VLA) models enable instruction-following embodied control, but their large compute and memory footprints hinder deployment on resource-constrained robots and edge platforms. While reducing weights to 1-bit precision through binarization can greatly improve efficiency, existing methods fail to narrow the distribution gap between binarized and full-precision weights, causing quantization errors to accumulate under long-horizon closed-loop execution and severely degrade actions. To fill this gap, we propose HBVLA, a VLA-tailored binarization framework. First, we use a policy-aware enhanced Hessian to identify weights that are truly critical for action generation. Then, we employ a sparse orthogonal transform for non-salient weights to induce a low-entropy intermediate state. Finally, we quantize both salient and non-salient weights in the Harr domain with group-wise 1-bit quantization. We have evaluated our approach on different VLAs: on LIBERO, quantized OpenVLA-OFT retains 92.2% of full-precision performance; on SimplerEnv, quantized CogAct retains 93.6%, significantly outperforming state-of-the-art binarization methods. We further validate our method on real-world evaluation suite and the results show that HBVLA incurs only marginal success-rate degradation compared to the full-precision model, demonstrating robust deployability under tight hardware constraints. Our work provides a practical foundation for ultra-low-bit quantization of VLAs, enabling more reliable deployment on hardware-limited robotic platforms.
K-Sort Eval: Efficient Preference Evaluation for Visual Generation via Corrected VLM-as-a-Judge
Feb 10, 2026The rapid development of visual generative models raises the need for more scalable and human-aligned evaluation methods. While the crowdsourced Arena platforms offer human preference assessments by collecting human votes, they are costly and time-consuming, inherently limiting their scalability. Leveraging vision-language model (VLMs) as substitutes for manual judgments presents a promising solution. However, the inherent hallucinations and biases of VLMs hinder alignment with human preferences, thus compromising evaluation reliability. Additionally, the static evaluation approach lead to low efficiency. In this paper, we propose K-Sort Eval, a reliable and efficient VLM-based evaluation framework that integrates posterior correction and dynamic matching. Specifically, we curate a high-quality dataset from thousands of human votes in K-Sort Arena, with each instance containing the outputs and rankings of K models. When evaluating a new model, it undergoes (K+1)-wise free-for-all comparisons with existing models, and the VLM provide the rankings. To enhance alignment and reliability, we propose a posterior correction method, which adaptively corrects the posterior probability in Bayesian updating based on the consistency between the VLM prediction and human supervision. Moreover, we propose a dynamic matching strategy, which balances uncertainty and diversity to maximize the expected benefit of each comparison, thus ensuring more efficient evaluation. Extensive experiments show that K-Sort Eval delivers evaluation results consistent with K-Sort Arena, typically requiring fewer than 90 model runs, demonstrating both its efficiency and reliability.
DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion
Jan 30, 2026Current speech language models generate responses directly without explicit reasoning, leading to errors that cannot be corrected once audio is produced. We introduce \textbf{``Silent Thought, Spoken Answer''} -- a paradigm where speech LLMs generate internal text reasoning alongside spoken responses, with thinking traces informing speech quality. To realize this, we present \method{}, the first diffusion-based speech-text language model supporting both understanding and generation, unifying discrete text and tokenized speech under a single masked diffusion framework. Unlike autoregressive approaches, \method{} jointly generates reasoning traces and speech tokens through iterative denoising, with modality-specific masking schedules. We also construct \dataset{}, the first speech QA dataset with paired text reasoning traces, containing 26K samples totaling 319 hours. Experiments show \method{} achieves state-of-the-art speech-to-speech QA accuracy, outperforming the best baseline by up to 9 points, while attaining the best TTS quality among generative models (6.2\% WER) and preserving language understanding (66.2\% MMLU). Ablations confirm that both the diffusion architecture and thinking traces contribute to these gains.
Time-Annealed Perturbation Sampling: Diverse Generation for Diffusion Language Models
Jan 30, 2026Diffusion language models (Diffusion-LMs) introduce an explicit temporal dimension into text generation, yet how this structure can be leveraged to control generation diversity for exploring multiple valid semantic or reasoning paths remains underexplored. In this paper, we show that Diffusion-LMs, like diffusion models in image generation, exhibit a temporal division of labor: early denoising steps largely determine the global semantic structure, while later steps focus on local lexical refinement. Building on this insight, we propose Time-Annealed Perturbation Sampling (TAPS), a training-free inference strategy that encourages semantic branching early in the diffusion process while progressively reducing perturbations to preserve fluency and instruction adherence. TAPS is compatible with both non-autoregressive and semi-autoregressive Diffusion backbones, demonstrated on LLaDA and TraDo in our paper, and consistently improves output diversity across creative writing and reasoning benchmarks without compromising generation quality.
MoST: Mixing Speech and Text with Modality-Aware Mixture of Experts
Jan 15, 2026We present MoST (Mixture of Speech and Text), a novel multimodal large language model that seamlessly integrates speech and text processing through our proposed Modality-Aware Mixture of Experts (MAMoE) architecture. While current multimodal models typically process diverse modality representations with identical parameters, disregarding their inherent representational differences, we introduce specialized routing pathways that direct tokens to modality-appropriate experts based on input type. MAMoE simultaneously enhances modality-specific learning and cross-modal understanding through two complementary components: modality-specific expert groups that capture domain-specific patterns and shared experts that facilitate information transfer between modalities. Building on this architecture, we develop an efficient transformation pipeline that adapts the pretrained MoE language model through strategic post-training on ASR and TTS datasets, followed by fine-tuning with a carefully curated speech-text instruction dataset. A key feature of this pipeline is that it relies exclusively on fully accessible, open-source datasets to achieve strong performance and data efficiency. Comprehensive evaluations across ASR, TTS, audio language modeling, and spoken question answering benchmarks show that MoST consistently outperforms existing models of comparable parameter counts. Our ablation studies confirm that the modality-specific routing mechanism and shared experts design significantly contribute to performance gains across all tested domains. To our knowledge, MoST represents the first fully open-source speech-text LLM built on a Mixture of Experts architecture. \footnote{We release MoST model, training code, inference code, and training data at https://github.com/NUS-HPC-AI-Lab/MoST
Neural Value Iteration
Nov 11, 2025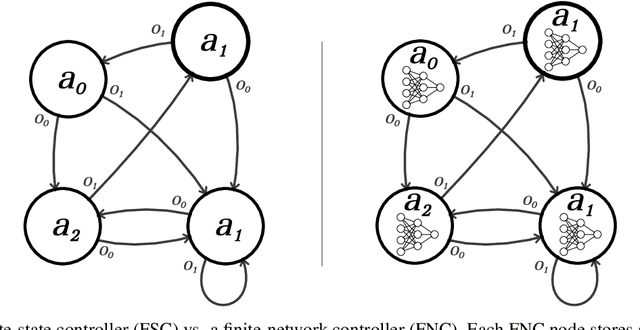

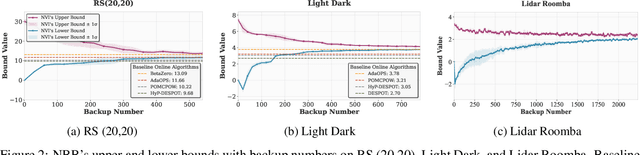
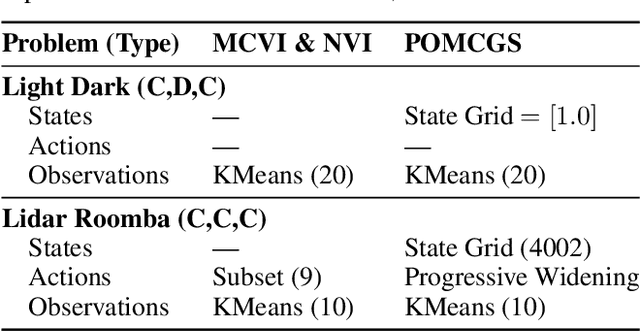
The value function of a POMDP exhibits the piecewise-linear-convex (PWLC) property and can be represented as a finite set of hyperplanes, known as $α$-vectors. Most state-of-the-art POMDP solvers (offline planners) follow the point-based value iteration scheme, which performs Bellman backups on $α$-vectors at reachable belief points until convergence. However, since each $α$-vector is $|S|$-dimensional, these methods quickly become intractable for large-scale problems due to the prohibitive computational cost of Bellman backups. In this work, we demonstrate that the PWLC property allows a POMDP's value function to be alternatively represented as a finite set of neural networks. This insight enables a novel POMDP planning algorithm called \emph{Neural Value Iteration}, which combines the generalization capability of neural networks with the classical value iteration framework. Our approach achieves near-optimal solutions even in extremely large POMDPs that are intractable for existing offline solvers.