 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Regret Approximation for Unsupervised Dynamic Environment Generation
Jan 21, 2026Unsupervised Environment Design (UED) seeks to automatically generate training curricula for reinforcement learning (RL) agents, with the goal of improving generalisation and zero-shot performance. However, designing effective curricula remains a difficult problem, particularly in settings where small subsets of environment parameterisations result in significant increases in the complexity of the required policy. Current methods struggle with a difficult credit assignment problem and rely on regret approximations that fail to identify challenging levels, both of which are compounded as the size of the environment grows. We propose Dynamic Environment Generation for UED (DEGen) to enable a denser level generator reward signal, reducing the difficulty of credit assignment and allowing for UED to scale to larger environment sizes. We also introduce a new regret approximation, Maximised Negative Advantage (MNA), as a significantly improved metric to optimise for, that better identifies more challenging levels. We show empirically that MNA outperforms current regret approximations and when combined with DEGen, consistently outperforms existing methods, especially as the size of the environment grows. We have made all our code available here: https://github.com/HarryMJMead/Dynamic-Environment-Generation-for-UED.
Gaussian Process Aggregation for Root-Parallel Monte Carlo Tree Search with Continuous Actions
Dec 10, 2025Monte Carlo Tree Search is a cornerstone algorithm for online planning, and its root-parallel variant is widely used when wall clock time is limited but best performance is desired. In environments with continuous action spaces, how to best aggregate statistics from different threads is an important yet underexplored question. In this work, we introduce a method that uses Gaussian Process Regression to obtain value estimates for promising actions that were not trialed in the environment. We perform a systematic evaluation across 6 different domains, demonstrating that our approach outperforms existing aggregation strategies while requiring a modest increase in inference time.
Neural Value Iteration
Nov 11, 2025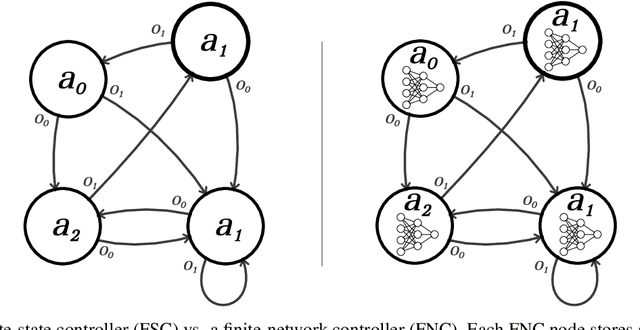

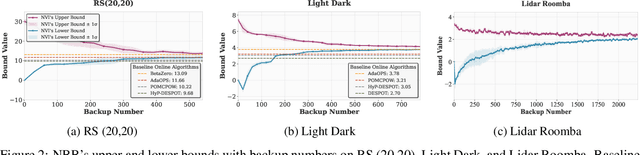
The value function of a POMDP exhibits the piecewise-linear-convex (PWLC) property and can be represented as a finite set of hyperplanes, known as $α$-vectors. Most state-of-the-art POMDP solvers (offline planners) follow the point-based value iteration scheme, which performs Bellman backups on $α$-vectors at reachable belief points until convergence. However, since each $α$-vector is $|S|$-dimensional, these methods quickly become intractable for large-scale problems due to the prohibitive computational cost of Bellman backups. In this work, we demonstrate that the PWLC property allows a POMDP's value function to be alternatively represented as a finite set of neural networks. This insight enables a novel POMDP planning algorithm called \emph{Neural Value Iteration}, which combines the generalization capability of neural networks with the classical value iteration framework. Our approach achieves near-optimal solutions even in extremely large POMDPs that are intractable for existing offline solvers.
Scalable Solution Methods for Dec-POMDPs with Deterministic Dynamics
Aug 29, 2025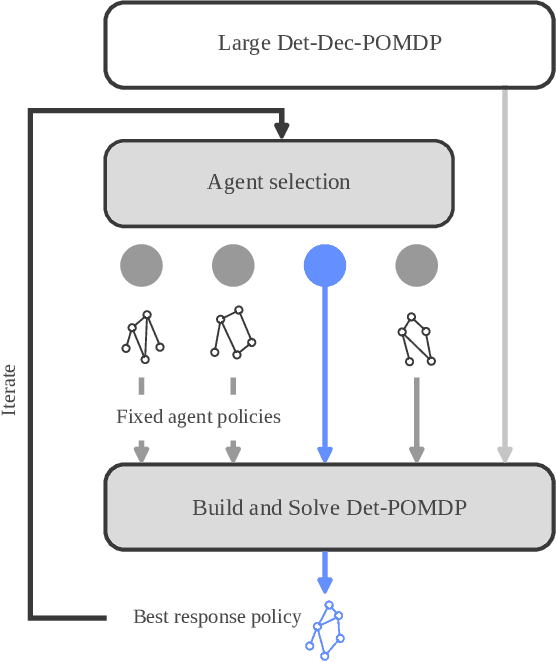
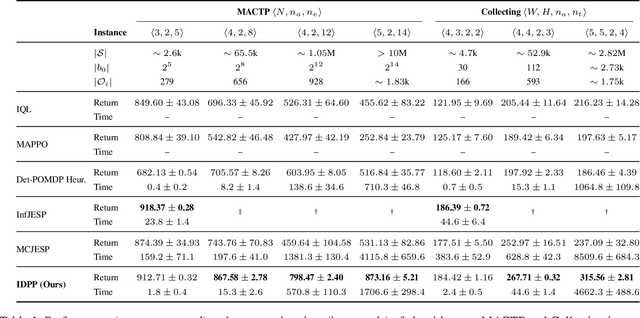
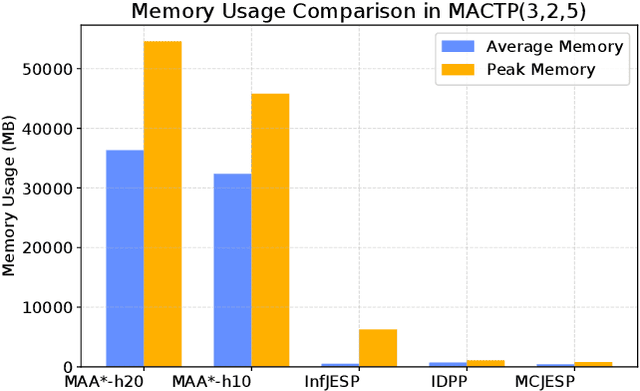
Many high-level multi-agent planning problems, including multi-robot navigation and path planning, can be effectively modeled using deterministic actions and observations. In this work, we focus on such domains and introduce the class of Deterministic Decentralized POMDPs (Det-Dec-POMDPs). This is a subclass of Dec-POMDPs characterized by deterministic transitions and observations conditioned on the state and joint actions. We then propose a practical solver called Iterative Deterministic POMDP Planning (IDPP). This method builds on the classic Joint Equilibrium Search for Policies framework and is specifically optimized to handle large-scale Det-Dec-POMDPs that current Dec-POMDP solvers are unable to address efficiently.
Partially Observable Monte-Carlo Graph Search
Jul 28, 2025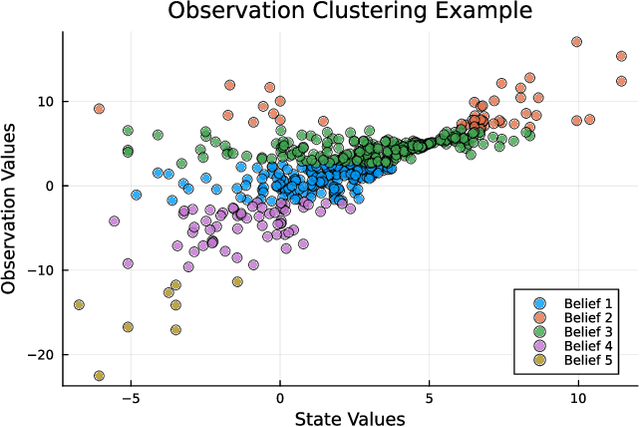

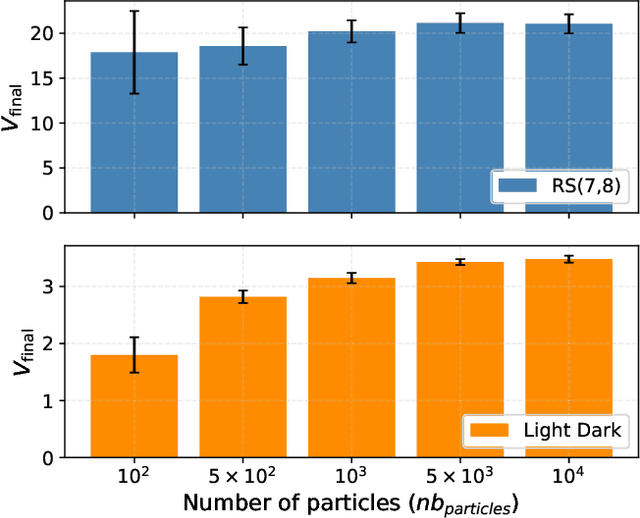

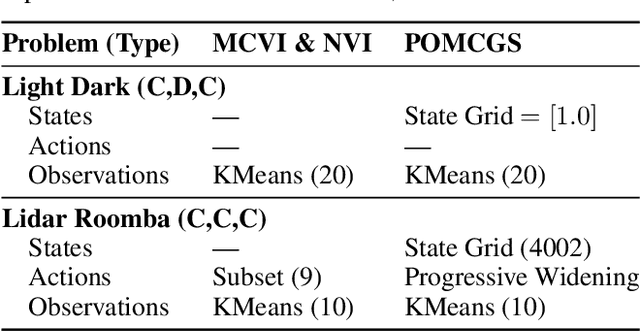
Currently, large partially observable Markov decision processes (POMDPs) are often solved by sampling-based online methods which interleave planning and execution phases. However, a pre-computed offline policy is more desirable in POMDP applications with time or energy constraints. But previous offline algorithms are not able to scale up to large POMDPs. In this article, we propose a new sampling-based algorithm, the partially observable Monte-Carlo graph search (POMCGS) to solve large POMDPs offline. Different from many online POMDP methods, which progressively develop a tree while performing (Monte-Carlo) simulations, POMCGS folds this search tree on the fly to construct a policy graph, so that computations can be drastically reduced, and users can analyze and validate the policy prior to embedding and executing it. Moreover, POMCGS, together with action progressive widening and observation clustering methods provided in this article, is able to address certain continuous POMDPs. Through experiments, we demonstrate that POMCGS can generate policies on the most challenging POMDPs, which cannot be computed by previous offline algorithms, and these policies' values are competitive compared with the state-of-the-art online POMDP algorithms.
A Finite-State Controller Based Offline Solver for Deterministic POMDPs
May 01, 2025



Deterministic partially observable Markov decision processes (DetPOMDPs) often arise in planning problems where the agent is uncertain about its environmental state but can act and observe deterministically. In this paper, we propose DetMCVI, an adaptation of the Monte Carlo Value Iteration (MCVI) algorithm for DetPOMDPs, which builds policies in the form of finite-state controllers (FSCs). DetMCVI solves large problems with a high success rate, outperforming existing baselines for DetPOMDPs. We also verify the performance of the algorithm in a real-world mobile robot forest mapping scenario.
Return Capping: Sample-Efficient CVaR Policy Gradient Optimisation
Apr 29, 2025When optimising for conditional value at risk (CVaR) using policy gradients (PG), current methods rely on discarding a large proportion of trajectories, resulting in poor sample efficiency. We propose a reformulation of the CVaR optimisation problem by capping the total return of trajectories used in training, rather than simply discarding them, and show that this is equivalent to the original problem if the cap is set appropriately. We show, with empirical results in an number of environments, that this reformulation of the problem results in consistently improved performance compared to baselines.
Decremental Dynamics Planning for Robot Navigation
Mar 26, 2025Most, if not all, robot navigation systems employ a decomposed planning framework that includes global and local planning. To trade-off onboard computation and plan quality, current systems have to limit all robot dynamics considerations only within the local planner, while leveraging an extremely simplified robot representation (e.g., a point-mass holonomic model without dynamics) in the global level. However, such an artificial decomposition based on either full or zero consideration of robot dynamics can lead to gaps between the two levels, e.g., a global path based on a holonomic point-mass model may not be realizable by a non-holonomic robot, especially in highly constrained obstacle environments. Motivated by such a limitation, we propose a novel paradigm, Decremental Dynamics Planning that integrates dynamic constraints into the entire planning process, with a focus on high-fidelity dynamics modeling at the beginning and a gradual fidelity reduction as the planning progresses. To validate the effectiveness of this paradigm, we augment three different planners with DDP and show overall improved planning performance. We also develop a new DDP-based navigation system, which achieves first place in the simulation phase of the 2025 BARN Challenge. Both simulated and physical experiments validate DDP's hypothesized benefits.
Generating Causal Explanations of Vehicular Agent Behavioural Interactions with Learnt Reward Profiles
Mar 18, 2025

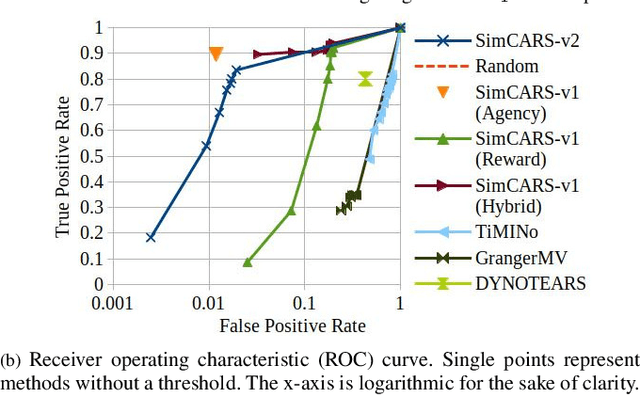

Transparency and explainability are important features that responsible autonomous vehicles should possess, particularly when interacting with humans, and causal reasoning offers a strong basis to provide these qualities. However, even if one assumes agents act to maximise some concept of reward, it is difficult to make accurate causal inferences of agent planning without capturing what is of importance to the agent. Thus our work aims to learn a weighting of reward metrics for agents such that explanations for agent interactions can be causally inferred. We validate our approach quantitatively and qualitatively across three real-world driving datasets, demonstrating a functional improvement over previous methods and competitive performance across evaluation metrics.
LUMOS: Language-Conditioned Imitation Learning with World Models
Mar 13, 2025We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model. Videos, dataset and code are available at http://lumos.cs.uni-freiburg.de.