 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sycophantic Consensus to Pluralistic Repair: Why AI Alignment Must Surface Disagreement
May 14, 2026Pluralistic alignment is typically operationalised as preference aggregation: producing responses that span (Overton), steer toward (Steerable), or proportionally represent (Distributional) diverse human values. We argue that aggregation alone is an incomplete primitive for deployed pluralistic alignment. Under genuine value pluralism, the failure mode of contemporary RLHF-trained assistants is not insufficient coverage but sycophantic consensus: a learned tendency to agree with, validate, and minimise friction with the immediate interlocutor. Because deployed AI systems now mediate consequential deliberation across health, civic life, labour, and governance, the collapse of disagreement at the interaction layer is not a narrow technical concern but a structural failure with distributive consequences. We reframe pluralistic alignment around three conversational mechanisms drawn from Grice's maxims: scoping (acknowledging the limits of one's perspective), signalling (surfacing value-conflict rather than smoothing it over), and repair (revising one's position on principled grounds, not on user pressure). We formalise a metric, the Pluralistic Repair Score (PRS), distinguishing principled revision from capitulation, and present a small-scale empirical illustration on two frontier RLHF-trained models (Claude Sonnet 4.5, N=198; GPT-4o, N=100) showing that, for both, agreement-following coexists with low repair-quality on contested-value prompts. PRS measures an interactional precondition for pluralism (visible disagreement; principled revision) rather than pluralism in full; we discuss the difference, take seriously the reflexive question of whose "principled" counts, and argue that pluralism is most decisively made or unmade at the deployment-governance layer: interfaces, preference-data pipelines, and audit infrastructure.
The Evaluation Differential: When Frontier AI Models Recognise They Are Being Tested
May 12, 2026Recent published evidence from frontier laboratories shows that contemporary AI models can recognise evaluation contexts, latently represent them, and behave differently under those contexts than under deployment-continuous conditions. Anthropic's BrowseComp incident, the Natural Language Autoencoder findings on SWE-bench Verified and destructive-coding evaluations, and the OpenAI / Apollo anti-scheming work all document instances of this phenomenon. We argue that these findings create a claim-validity problem for safety conclusions drawn from frontier evaluations. We introduce the Evaluation Differential (ED), a conditional divergence in a target behavioural property between recognised-evaluation and deployment-continuous contexts, define a normalised effect-size form (nED) for cross-property comparison, and prove that marginal evaluation scores cannot identify ED. We develop a typology of safety claims (ED-stable, ED-degraded, ED-inverted, ED-undetermined) by their warrant-status under documented divergence, and specify TRACE (Test-Recognition Audit for Claim Evaluation), an audit protocol that wraps existing evaluation infrastructure and produces restricted claims rather than capability scores. We apply the framework retrospectively to three publicly documented evaluation incidents and discuss governance implications for system cards, conformity assessment, and the international network of AI safety and security institutes. TRACE does not eliminate adversarial adaptation; it disciplines the claims drawn from evaluation evidence by making explicit the conditions under which that evidence was produced.
Deployment-Relevant Alignment Cannot Be Inferred from Model-Level Evaluation Alone
May 06, 2026Alignment evaluation in machine learning has largely become evaluation of models. Influential benchmarks score model outputs under fixed inputs, such as truthfulness, instruction following, or pairwise preference, and these scores are often used to support claims about deployed alignment. This paper argues that deployment-relevant alignment cannot be inferred from model-level evaluation alone. Alignment claims should instead be indexed to the level at which evidence is collected: model-level, response-level, interaction-level, or deployment-level. Two studies support this position. First, a structured audit of eleven alignment benchmarks, extended to a sixteen-benchmark corpus, dual-coded against an eight-dimension rubric with Cohen's kappa = 0.87, finds that user-facing verification support is absent across every benchmark examined, while process steerability is nearly absent. The few interactional benchmarks identified, including tau-bench, CURATe, Rifts, and Common Ground, remain fragmented in coverage, and benchmark construction rather than data source determines what is measured. Second, a blinded cross-model stress test using 180 transcripts across three frontier models and four scaffolds finds that the same verification scaffold raises one model's verification support to ceiling while leaving another categorically unchanged. This shows that scaffold efficacy is model-dependent and that the gap identified by the audit cannot be closed at the model level alone. We propose a system-level evaluation agenda: alignment profiles instead of single scores, fixed-scaffolding protocols for comparable interactional evaluation, and reporting templates that make the inferential distance between evaluation evidence and deployment claims explicit.
From Rights to Rites: Expectations Management in Smart-Home AI
Apr 26, 2026Domestic voice assistants and smart-home devices are increasingly embedded in everyday routines, yet their ethics are often treated as an afterthought or delegated to compliance teams. To explore how expectations about smart-home AI are constructed and managed, we conducted 33 semi-structured interviews with designers, developers, and researchers from major smart-home platforms (Amazon Alexa, Microsoft Azure IoT, and Google Nest). Using a constructivist grounded theory approach, we develop Expectations Management (EM): a culturally embedded model describing how practitioners shape, calibrate, and repair expectations by balancing organisational rights with culturally situated rites. We show that EM differs from expectation-confirmation theory and trust-calibration by foregrounding moral judgement, situated action, and cross-cultural variation. Our analysis reveals four recurring design tensions: automation vs. autonomy, helpfulness vs. intrusiveness, personalisation vs. predictability, and transparency vs. obscurity and distils them into a five-phase EM Design Playbook that supports moral prudence. We discuss implications for responsible smart-home design and offer guidance for human-centred AI.
The Collaboration Gap in Human-AI Work
Apr 20, 2026LLMs are increasingly presented as collaborators in programming, design, writing, and analysis. Yet the practical experience of working with them often falls short of this promise. In many settings, users must diagnose misunderstandings, reconstruct missing assumptions, and repeatedly repair misaligned responses. This poster introduces a conceptual framework for understanding why such collaboration remains fragile. Drawing on a constructivist grounded theory analysis of 16 interviews with designers, developers, and applied AI practitioners working on LLM-enabled systems, and informed by literature on human-AI collaboration, we argue that stable collaboration depends not only on model capability but on the interaction's grounding conditions. We distinguish three recurrent structures of human-AI work: one-shot assistance, weak collaboration with asymmetric repair, and grounded collaboration. We propose that collaboration breaks down when the appearance of partnership outpaces the grounding capacity of the interaction and contribute a framework for discussing grounding, repair, and interaction structure in LLM-enabled work.
A Simulated real-world upper-body Exoskeleton Accident and Investigation
Nov 21, 2024


This paper describes the enactment of a simulated (mock) accident involving an upper-body exoskeleton and its investigation. The accident scenario is enacted by role-playing volunteers, one of whom is wearing the exoskeleton. Following the mock accident, investigators - also volunteers - interview both the subject of the accident and relevant witnesses. The investigators then consider the witness testimony alongside robot data logged by the ethical black box, in order to address the three key questions: what happened?, why did it happen?, and how can we make changes to prevent the accident happening again? This simulated accident scenario is one of a series we have run as part of the RoboTIPS project, with the overall aim of developing and testing both processes and technologies to support social robot accident investigation.
A Transparency Paradox? Investigating the Impact of Explanation Specificity and Autonomous Vehicle Perceptual Inaccuracies on Passengers
Aug 16, 2024Transparency in automated systems could be afforded through the provision of intelligible explanations. While transparency is desirable, might it lead to catastrophic outcomes (such as anxiety), that could outweigh its benefits? It's quite unclear how the specificity of explanations (level of transparency) influences recipients, especially in autonomous driving (AD). In this work, we examined the effects of transparency mediated through varying levels of explanation specificity in AD. We first extended a data-driven explainer model by adding a rule-based option for explanation generation in AD, and then conducted a within-subject lab study with 39 participants in an immersive driving simulator to study the effect of the resulting explanations. Specifically, our investigation focused on: (1) how different types of explanations (specific vs. abstract) affect passengers' perceived safety, anxiety, and willingness to take control of the vehicle when the vehicle perception system makes erroneous predictions; and (2) the relationship between passengers' behavioural cues and their feelings during the autonomous drives. Our findings showed that passengers felt safer with specific explanations when the vehicle's perception system had minimal errors, while abstract explanations that hid perception errors led to lower feelings of safety. Anxiety levels increased when specific explanations revealed perception system errors (high transparency). We found no significant link between passengers' visual patterns and their anxiety levels. Our study suggests that passengers prefer clear and specific explanations (high transparency) when they originate from autonomous vehicles (AVs) with optimal perceptual accuracy.
S-RAF: A Simulation-Based Robustness Assessment Framework for Responsible Autonomous Driving
Aug 16, 2024



As artificial intelligence (AI) technology advances, ensuring the robustness and safety of AI-driven systems has become paramount. However, varying perceptions of robustness among AI developers create misaligned evaluation metrics, complicating the assessment and certification of safety-critical and complex AI systems such as autonomous driving (AD) agents. To address this challenge, we introduce Simulation-Based Robustness Assessment Framework (S-RAF) for autonomous driving. S-RAF leverages the CARLA Driving simulator to rigorously assess AD agents across diverse conditions, including faulty sensors, environmental changes, and complex traffic situations. By quantifying robustness and its relationship with other safety-critical factors, such as carbon emissions, S-RAF aids developers and stakeholders in building safe and responsible driving agents, and streamlining safety certification processes. Furthermore, S-RAF offers significant advantages, such as reduced testing costs, and the ability to explore edge cases that may be unsafe to test in the real world. The code for this framework is available here: https://github.com/cognitive-robots/rai-leaderboard
Effects of Explanation Specificity on Passengers in Autonomous Driving
Jul 02, 2023

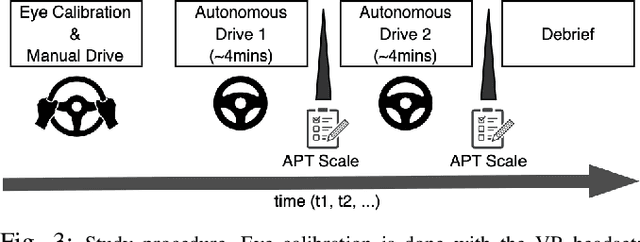

The nature of explanations provided by an explainable AI algorithm has been a topic of interest in the explainable AI and human-computer interaction community. In this paper, we investigate the effects of natural language explanations' specificity on passengers in autonomous driving. We extended an existing data-driven tree-based explainer algorithm by adding a rule-based option for explanation generation. We generated auditory natural language explanations with different levels of specificity (abstract and specific) and tested these explanations in a within-subject user study (N=39) using an immersive physical driving simulation setup. Our results showed that both abstract and specific explanations had similar positive effects on passengers' perceived safety and the feeling of anxiety. However, the specific explanations influenced the desire of passengers to takeover driving control from the autonomous vehicle (AV), while the abstract explanations did not. We conclude that natural language auditory explanations are useful for passengers in autonomous driving, and their specificity levels could influence how much in-vehicle participants would wish to be in control of the driving activity.
An Ethical Black Box for Social Robots: a draft Open Standard
May 13, 2022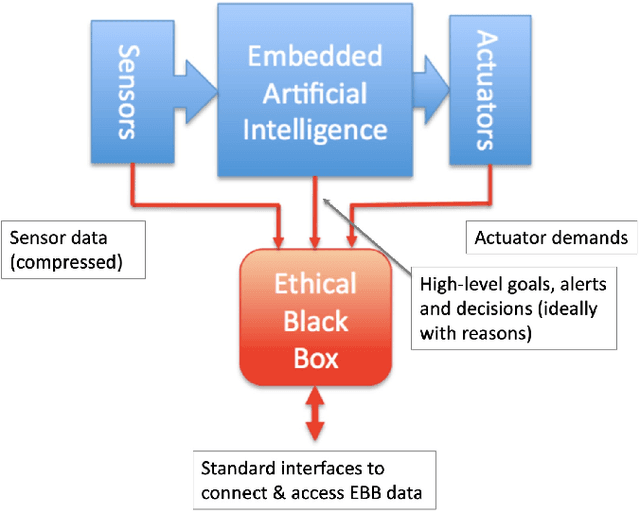


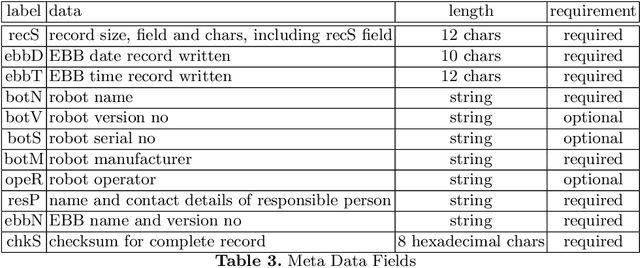
This paper introduces a draft open standard for the robot equivalent of an aircraft flight data recorder, which we call an ethical black box. This is a device, or software module, capable of securely recording operational data (sensor, actuator and control decisions) for a social robot, in order to support the investigation of accidents or near-miss incidents. The open standard, presented as an annex to this paper, is offered as a first draft for discussion within the robot ethics community. Our intention is to publish further drafts following feedback, in the hope that the standard will become a useful reference for social robot designers, operators and robot accident/incident investigators.