 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAgents: A Policy Server for Efficient VLA Inference
Jan 16, 2026The rapid emergence of Vision-Language-Action models (VLAs) has a significant impact on robotics. However, their deployment remains complex due to the fragmented interfaces and the inherent communication latency in distributed setups. To address this, we introduce VLAgents, a modular policy server that abstracts VLA inferencing behind a unified Gymnasium-style protocol. Crucially, its communication layer transparently adapts to the context by supporting both zero-copy shared memory for high-speed simulation and compressed streaming for remote hardware. In this work, we present the architecture of VLAgents and validate it by integrating seven policies -- including OpenVLA and Pi Zero. In a benchmark with both local and remote communication, we further demonstrate how it outperforms the default policy servers provided by OpenVLA, OpenPi, and LeRobot. VLAgents is available at https://github.com/RobotControlStack/vlagents
Robot Control Stack: A Lean Ecosystem for Robot Learning at Scale
Sep 18, 2025



Vision-Language-Action models (VLAs) mark a major shift in robot learning. They replace specialized architectures and task-tailored components of expert policies with large-scale data collection and setup-specific fine-tuning. In this machine learning-focused workflow that is centered around models and scalable training, traditional robotics software frameworks become a bottleneck, while robot simulations offer only limited support for transitioning from and to real-world experiments. In this work, we close this gap by introducing Robot Control Stack (RCS), a lean ecosystem designed from the ground up to support research in robot learning with large-scale generalist policies. At its core, RCS features a modular and easily extensible layered architecture with a unified interface for simulated and physical robots, facilitating sim-to-real transfer. Despite its minimal footprint and dependencies, it offers a complete feature set, enabling both real-world experiments and large-scale training in simulation. Our contribution is twofold: First, we introduce the architecture of RCS and explain its design principles. Second, we evaluate its usability and performance along the development cycle of VLA and RL policies. Our experiments also provide an extensive evaluation of Octo, OpenVLA, and Pi Zero on multiple robots and shed light on how simulation data can improve real-world policy performance. Our code, datasets, weights, and videos are available at: https://robotcontrolstack.github.io/
MetricNet: Recovering Metric Scale in Generative Navigation Policies
Sep 17, 2025Generative navigation policies have made rapid progress in improving end-to-end learned navigation. Despite their promising results, this paradigm has two structural problems. First, the sampled trajectories exist in an abstract, unscaled space without metric grounding. Second, the control strategy discards the full path, instead moving directly towards a single waypoint. This leads to short-sighted and unsafe actions, moving the robot towards obstacles that a complete and correctly scaled path would circumvent. To address these issues, we propose MetricNet, an effective add-on for generative navigation that predicts the metric distance between waypoints, grounding policy outputs in real-world coordinates. We evaluate our method in simulation with a new benchmarking framework and show that executing MetricNet-scaled waypoints significantly improves both navigation and exploration performance. Beyond simulation, we further validate our approach in real-world experiments. Finally, we propose MetricNav, which integrates MetricNet into a navigation policy to guide the robot away from obstacles while still moving towards the goal.
Multimodal Spatial Language Maps for Robot Navigation and Manipulation
Jun 07, 2025Grounding language to a navigating agent's observations can leverage pretrained multimodal foundation models to match perceptions to object or event descriptions. However, previous approaches remain disconnected from environment mapping, lack the spatial precision of geometric maps, or neglect additional modality information beyond vision. To address this, we propose multimodal spatial language maps as a spatial map representation that fuses pretrained multimodal features with a 3D reconstruction of the environment. We build these maps autonomously using standard exploration. We present two instances of our maps, which are visual-language maps (VLMaps) and their extension to audio-visual-language maps (AVLMaps) obtained by adding audio information. When combined with large language models (LLMs), VLMaps can (i) translate natural language commands into open-vocabulary spatial goals (e.g., "in between the sofa and TV") directly localized in the map, and (ii) be shared across different robot embodiments to generate tailored obstacle maps on demand. Building upon the capabilities above, AVLMaps extend VLMaps by introducing a unified 3D spatial representation integrating audio, visual, and language cues through the fusion of features from pretrained multimodal foundation models. This enables robots to ground multimodal goal queries (e.g., text, images, or audio snippets) to spatial locations for navigation. Additionally, the incorporation of diverse sensory inputs significantly enhances goal disambiguation in ambiguous environments. Experiments in simulation and real-world settings demonstrate that our multimodal spatial language maps enable zero-shot spatial and multimodal goal navigation and improve recall by 50% in ambiguous scenarios. These capabilities extend to mobile robots and tabletop manipulators, supporting navigation and interaction guided by visual, audio, and spatial cues.
Augmented Reality for RObots (ARRO): Pointing Visuomotor Policies Towards Visual Robustness
May 13, 2025Visuomotor policies trained on human expert demonstrations have recently shown strong performance across a wide range of robotic manipulation tasks. However, these policies remain highly sensitive to domain shifts stemming from background or robot embodiment changes, which limits their generalization capabilities. In this paper, we present ARRO, a novel calibration-free visual representation that leverages zero-shot open-vocabulary segmentation and object detection models to efficiently mask out task-irrelevant regions of the scene without requiring additional training. By filtering visual distractors and overlaying virtual guides during both training and inference, ARRO improves robustness to scene variations and reduces the need for additional data collection. We extensively evaluate ARRO with Diffusion Policy on several tabletop manipulation tasks in both simulation and real-world environments, and further demonstrate its compatibility and effectiveness with generalist robot policies, such as Octo and OpenVLA. Across all settings in our evaluation, ARRO yields consistent performance gains, allows for selective masking to choose between different objects, and shows robustness even to challenging segmentation conditions. Videos showcasing our results are available at: augmented-reality-for-robots.github.io
LUMOS: Language-Conditioned Imitation Learning with World Models
Mar 13, 2025We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model. Videos, dataset and code are available at http://lumos.cs.uni-freiburg.de.
LLM-Pack: Intuitive Grocery Handling for Logistics Applications
Mar 11, 2025Robotics and automation are increasingly influential in logistics but remain largely confined to traditional warehouses. In grocery retail, advancements such as cashier-less supermarkets exist, yet customers still manually pick and pack groceries. While there has been a substantial focus in robotics on the bin picking problem, the task of packing objects and groceries has remained largely untouched. However, packing grocery items in the right order is crucial for preventing product damage, e.g., heavy objects should not be placed on top of fragile ones. However, the exact criteria for the right packing order are hard to define, in particular given the huge variety of objects typically found in stores. In this paper, we introduce LLM-Pack, a novel approach for grocery packing. LLM-Pack leverages language and vision foundation models for identifying groceries and generating a packing sequence that mimics human packing strategy. LLM-Pack does not require dedicated training to handle new grocery items and its modularity allows easy upgrades of the underlying foundation models. We extensively evaluate our approach to demonstrate its performance. We will make the source code of LLMPack publicly available upon the publication of this manuscript.
REGRACE: A Robust and Efficient Graph-based Re-localization Algorithm using Consistency Evaluation
Mar 05, 2025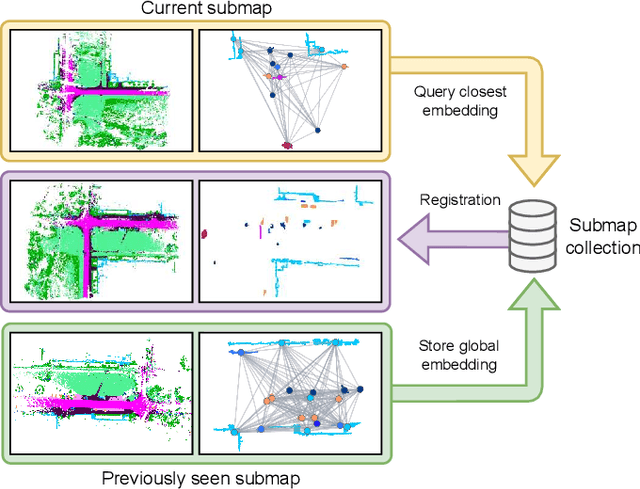
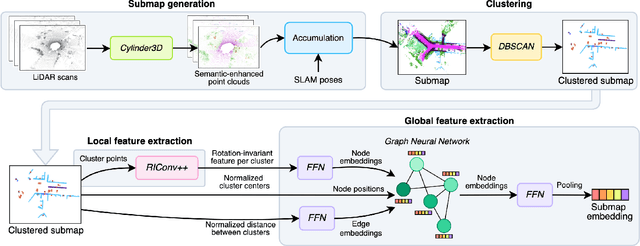
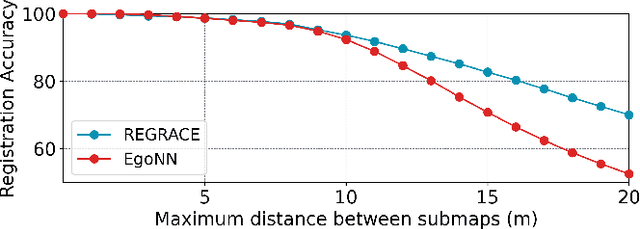
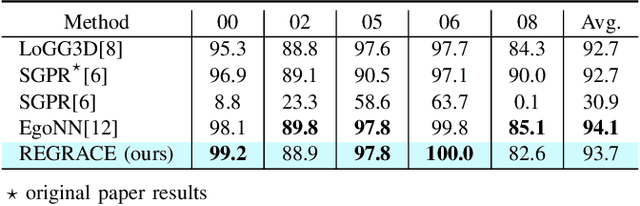
Loop closures are essential for correcting odometry drift and creating consistent maps, especially in the context of large-scale navigation. Current methods using dense point clouds for accurate place recognition do not scale well due to computationally expensive scan-to-scan comparisons. Alternative object-centric approaches are more efficient but often struggle with sensitivity to viewpoint variation. In this work, we introduce REGRACE, a novel approach that addresses these challenges of scalability and perspective difference in re-localization by using LiDAR-based submaps. We introduce rotation-invariant features for each labeled object and enhance them with neighborhood context through a graph neural network. To identify potential revisits, we employ a scalable bag-of-words approach, pooling one learned global feature per submap. Additionally, we define a revisit with geometrical consistency cues rather than embedding distance, allowing us to recognize far-away loop closures. Our evaluations demonstrate that REGRACE achieves similar results compared to state-of-the-art place recognition and registration baselines while being twice as fast.
Label-Efficient LiDAR Panoptic Segmentation
Mar 04, 2025



A main bottleneck of learning-based robotic scene understanding methods is the heavy reliance on extensive annotated training data, which often limits their generalization ability. In LiDAR panoptic segmentation, this challenge becomes even more pronounced due to the need to simultaneously address both semantic and instance segmentation from complex, high-dimensional point cloud data. In this work, we address the challenge of LiDAR panoptic segmentation with very few labeled samples by leveraging recent advances in label-efficient vision panoptic segmentation. To this end, we propose a novel method, Limited-Label LiDAR Panoptic Segmentation (L3PS), which requires only a minimal amount of labeled data. Our approach first utilizes a label-efficient 2D network to generate panoptic pseudo-labels from a small set of annotated images, which are subsequently projected onto point clouds. We then introduce a novel 3D refinement module that capitalizes on the geometric properties of point clouds. By incorporating clustering techniques, sequential scan accumulation, and ground point separation, this module significantly enhances the accuracy of the pseudo-labels, improving segmentation quality by up to +10.6 PQ and +7.9 mIoU. We demonstrate that these refined pseudo-labels can be used to effectively train off-the-shelf LiDAR segmentation networks. Through extensive experiments, we show that L3PS not only outperforms existing methods but also substantially reduces the annotation burden. We release the code of our work at https://l3ps.cs.uni-freiburg.de.
LiDAR Registration with Visual Foundation Models
Feb 26, 2025LiDAR registration is a fundamental task in robotic mapping and localization. A critical component of aligning two point clouds is identifying robust point correspondences using point descriptors. This step becomes particularly challenging in scenarios involving domain shifts, seasonal changes, and variations in point cloud structures. These factors substantially impact both handcrafted and learning-based approaches. In this paper, we address these problems by proposing to use DINOv2 features, obtained from surround-view images, as point descriptors. We demonstrate that coupling these descriptors with traditional registration algorithms, such as RANSAC or ICP, facilitates robust 6DoF alignment of LiDAR scans with 3D maps, even when the map was recorded more than a year before. Although conceptually straightforward, our method substantially outperforms more complex baseline techniques. In contrast to previous learning-based point descriptors, our method does not require domain-specific retraining and is agnostic to the point cloud structure, effectively handling both sparse LiDAR scans and dense 3D maps. We show that leveraging the additional camera data enables our method to outperform the best baseline by +24.8 and +17.3 registration recall on the NCLT and Oxford RobotCar datasets. We publicly release the registration benchmark and the code of our work on https://vfm-registration.cs.uni-freiburg.de.