 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParkDiffusion: Heterogeneous Multi-Agent Multi-Modal Trajectory Prediction for Automated Parking using Diffusion Models
May 01, 2025



Automated parking is a critical feature of Advanced Driver Assistance Systems (ADAS), where accurate trajectory prediction is essential to bridge perception and planning modules. Despite its significance, research in this domain remains relatively limited, with most existing studies concentrating on single-modal trajectory prediction of vehicles. In this work, we propose ParkDiffusion, a novel approach that predicts the trajectories of both vehicles and pedestrians in automated parking scenarios. ParkDiffusion employs diffusion models to capture the inherent uncertainty and multi-modality of future trajectories, incorporating several key innovations. First, we propose a dual map encoder that processes soft semantic cues and hard geometric constraints using a two-step cross-attention mechanism. Second, we introduce an adaptive agent type embedding module, which dynamically conditions the prediction process on the distinct characteristics of vehicles and pedestrians. Third, to ensure kinematic feasibility, our model outputs control signals that are subsequently used within a kinematic framework to generate physically feasible trajectories. We evaluate ParkDiffusion on the Dragon Lake Parking (DLP) dataset and the Intersections Drone (inD) dataset. Our work establishes a new baseline for heterogeneous trajectory prediction in parking scenarios, outperforming existing methods by a considerable margin.
Label-Efficient LiDAR Panoptic Segmentation
Mar 04, 2025



A main bottleneck of learning-based robotic scene understanding methods is the heavy reliance on extensive annotated training data, which often limits their generalization ability. In LiDAR panoptic segmentation, this challenge becomes even more pronounced due to the need to simultaneously address both semantic and instance segmentation from complex, high-dimensional point cloud data. In this work, we address the challenge of LiDAR panoptic segmentation with very few labeled samples by leveraging recent advances in label-efficient vision panoptic segmentation. To this end, we propose a novel method, Limited-Label LiDAR Panoptic Segmentation (L3PS), which requires only a minimal amount of labeled data. Our approach first utilizes a label-efficient 2D network to generate panoptic pseudo-labels from a small set of annotated images, which are subsequently projected onto point clouds. We then introduce a novel 3D refinement module that capitalizes on the geometric properties of point clouds. By incorporating clustering techniques, sequential scan accumulation, and ground point separation, this module significantly enhances the accuracy of the pseudo-labels, improving segmentation quality by up to +10.6 PQ and +7.9 mIoU. We demonstrate that these refined pseudo-labels can be used to effectively train off-the-shelf LiDAR segmentation networks. Through extensive experiments, we show that L3PS not only outperforms existing methods but also substantially reduces the annotation burden. We release the code of our work at https://l3ps.cs.uni-freiburg.de.
LiDAR Registration with Visual Foundation Models
Feb 26, 2025LiDAR registration is a fundamental task in robotic mapping and localization. A critical component of aligning two point clouds is identifying robust point correspondences using point descriptors. This step becomes particularly challenging in scenarios involving domain shifts, seasonal changes, and variations in point cloud structures. These factors substantially impact both handcrafted and learning-based approaches. In this paper, we address these problems by proposing to use DINOv2 features, obtained from surround-view images, as point descriptors. We demonstrate that coupling these descriptors with traditional registration algorithms, such as RANSAC or ICP, facilitates robust 6DoF alignment of LiDAR scans with 3D maps, even when the map was recorded more than a year before. Although conceptually straightforward, our method substantially outperforms more complex baseline techniques. In contrast to previous learning-based point descriptors, our method does not require domain-specific retraining and is agnostic to the point cloud structure, effectively handling both sparse LiDAR scans and dense 3D maps. We show that leveraging the additional camera data enables our method to outperform the best baseline by +24.8 and +17.3 registration recall on the NCLT and Oxford RobotCar datasets. We publicly release the registration benchmark and the code of our work on https://vfm-registration.cs.uni-freiburg.de.
A Good Foundation is Worth Many Labels: Label-Efficient Panoptic Segmentation
May 29, 2024A key challenge for the widespread application of learning-based models for robotic perception is to significantly reduce the required amount of annotated training data while achieving accurate predictions. This is essential not only to decrease operating costs but also to speed up deployment time. In this work, we address this challenge for PAnoptic SegmenTation with fEw Labels (PASTEL) by exploiting the groundwork paved by visual foundation models. We leverage descriptive image features from such a model to train two lightweight network heads for semantic segmentation and object boundary detection, using very few annotated training samples. We then merge their predictions via a novel fusion module that yields panoptic maps based on normalized cut. To further enhance the performance, we utilize self-training on unlabeled images selected by a feature-driven similarity scheme. We underline the relevance of our approach by employing PASTEL to important robot perception use cases from autonomous driving and agricultural robotics. In extensive experiments, we demonstrate that PASTEL significantly outperforms previous methods for label-efficient segmentation even when using fewer annotations. The code of our work is publicly available at http://pastel.cs.uni-freiburg.de.
Efficient Robot Learning for Perception and Mapping
May 23, 2024Holistic scene understanding poses a fundamental contribution to the autonomous operation of a robotic agent in its environment. Key ingredients include a well-defined representation of the surroundings to capture its spatial structure as well as assigning semantic meaning while delineating individual objects. Classic components from the toolbox of roboticists to address these tasks are simultaneous localization and mapping (SLAM) and panoptic segmentation. Although recent methods demonstrate impressive advances, mostly due to employing deep learning, they commonly utilize in-domain training on large datasets. Since following such a paradigm substantially limits their real-world application, my research investigates how to minimize human effort in deploying perception-based robotic systems to previously unseen environments. In particular, I focus on leveraging continual learning and reducing human annotations for efficient learning. An overview of my work can be found at https://vniclas.github.io.
Automatic Target-Less Camera-LiDAR Calibration From Motion and Deep Point Correspondences
Apr 26, 2024



Sensor setups of robotic platforms commonly include both camera and LiDAR as they provide complementary information. However, fusing these two modalities typically requires a highly accurate calibration between them. In this paper, we propose MDPCalib which is a novel method for camera-LiDAR calibration that requires neither human supervision nor any specific target objects. Instead, we utilize sensor motion estimates from visual and LiDAR odometry as well as deep learning-based 2D-pixel-to-3D-point correspondences that are obtained without in-domain retraining. We represent the camera-LiDAR calibration as a graph optimization problem and minimize the costs induced by constraints from sensor motion and point correspondences. In extensive experiments, we demonstrate that our approach yields highly accurate extrinsic calibration parameters and is robust to random initialization. Additionally, our approach generalizes to a wide range of sensor setups, which we demonstrate by employing it on various robotic platforms including a self-driving perception car, a quadruped robot, and a UAV. To make our calibration method publicly accessible, we release the code on our project website at http://calibration.cs.uni-freiburg.de.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024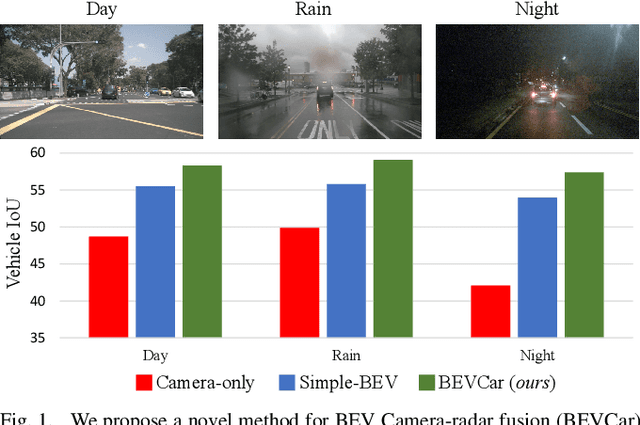
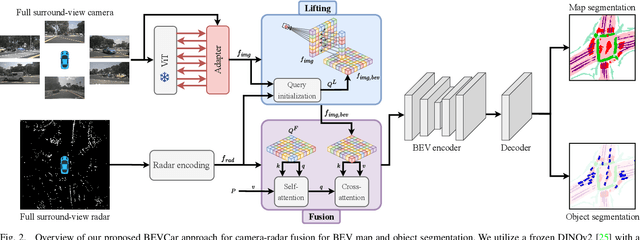
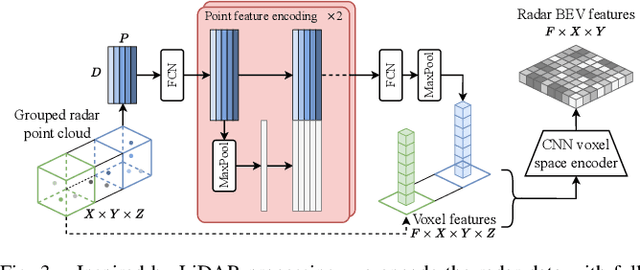
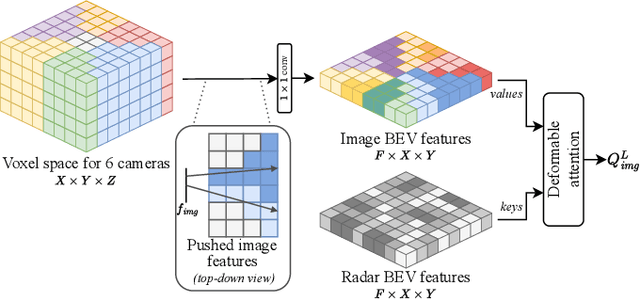
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
Collaborative Dynamic 3D Scene Graphs for Automated Driving
Sep 19, 2023



Maps have played an indispensable role in enabling safe and automated driving. Although there have been many advances on different fronts ranging from SLAM to semantics, building an actionable hierarchical semantic representation of urban dynamic scenes from multiple agents is still a challenging problem. In this work, we present Collaborative URBan Scene Graphs (CURB-SG) that enable higher-order reasoning and efficient querying for many functions of automated driving. CURB-SG leverages panoptic LiDAR data from multiple agents to build large-scale maps using an effective graph-based collaborative SLAM approach that detects inter-agent loop closures. To semantically decompose the obtained 3D map, we build a lane graph from the paths of ego agents and their panoptic observations of other vehicles. Based on the connectivity of the lane graph, we segregate the environment into intersecting and non-intersecting road areas. Subsequently, we construct a multi-layered scene graph that includes lane information, the position of static landmarks and their assignment to certain map sections, other vehicles observed by the ego agents, and the pose graph from SLAM including 3D panoptic point clouds. We extensively evaluate CURB-SG in urban scenarios using a photorealistic simulator. We release our code at http://curb.cs.uni-freiburg.de.
Few-Shot Panoptic Segmentation With Foundation Models
Sep 19, 2023Current state-of-the-art methods for panoptic segmentation require an immense amount of annotated training data that is both arduous and expensive to obtain posing a significant challenge for their widespread adoption. Concurrently, recent breakthroughs in visual representation learning have sparked a paradigm shift leading to the advent of large foundation models that can be trained with completely unlabeled images. In this work, we propose to leverage such task-agnostic image features to enable few-shot panoptic segmentation by presenting Segmenting Panoptic Information with Nearly 0 labels (SPINO). In detail, our method combines a DINOv2 backbone with lightweight network heads for semantic segmentation and boundary estimation. We show that our approach, albeit being trained with only ten annotated images, predicts high-quality pseudo-labels that can be used with any existing panoptic segmentation method. Notably, we demonstrate that SPINO achieves competitive results compared to fully supervised baselines while using less than 0.3% of the ground truth labels, paving the way for learning complex visual recognition tasks leveraging foundation models. To illustrate its general applicability, we further deploy SPINO on real-world robotic vision systems for both outdoor and indoor environments. To foster future research, we make the code and trained models publicly available at http://spino.cs.uni-freiburg.de.
CoDEPS: Online Continual Learning for Depth Estimation and Panoptic Segmentation
Mar 17, 2023Operating a robot in the open world requires a high level of robustness with respect to previously unseen environments. Optimally, the robot is able to adapt by itself to new conditions without human supervision, e.g., automatically adjusting its perception system to changing lighting conditions. In this work, we address the task of continual learning for deep learning-based monocular depth estimation and panoptic segmentation in new environments in an online manner. We introduce CoDEPS to perform continual learning involving multiple real-world domains while mitigating catastrophic forgetting by leveraging experience replay. In particular, we propose a novel domain-mixing strategy to generate pseudo-labels to adapt panoptic segmentation. Furthermore, we explicitly address the limited storage capacity of robotic systems by proposing sampling strategies for constructing a fixed-size replay buffer based on rare semantic class sampling and image diversity. We perform extensive evaluations of CoDEPS on various real-world datasets demonstrating that it successfully adapts to unseen environments without sacrificing performance on previous domains while achieving state-of-the-art results. The code of our work is publicly available at http://codeps.cs.uni-freiburg.de.