 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Motion Forecasting
Mar 10, 2026Motion forecasting aims to predict the future trajectories of dynamic agents in the scene, enabling autonomous vehicles to effectively reason about scene evolution. Existing approaches operate under the closed-world regime and assume fixed object taxonomy as well as access to high-quality perception. Therefore, they struggle in real-world settings where perception is imperfect and object taxonomy evolves over time. In this work, we bridge this fundamental gap by introducing open-world motion forecasting, a novel setting in which new object classes are sequentially introduced over time and future object trajectories are estimated directly from camera images. We tackle this setting by proposing the first end-to-end class-incremental motion forecasting framework to mitigate catastrophic forgetting while simultaneously learning to forecast newly introduced classes. When a new class is introduced, our framework employs a pseudo-labeling strategy to first generate motion forecasting pseudo-labels for all known classes which are then processed by a vision-language model to filter inconsistent and over-confident predictions. Parallelly, our approach further mitigates catastrophic forgetting by using a novel replay sampling strategy that leverages query feature variance to sample previous sequences with informative motion patterns. Extensive evaluation on the nuScenes and Argoverse 2 datasets demonstrates that our approach successfully resists catastrophic forgetting and maintains performance on previously learned classes while improving adaptation to novel ones. Further, we demonstrate that our approach supports zero-shot transfer to real-world driving and naturally extends to end-to-end class-incremental planning, enabling continual adaptation of the full autonomous driving system. We provide the code at https://omen.cs.uni-freiburg.de .
Dataset Safety in Autonomous Driving: Requirements, Risks, and Assurance
Nov 11, 2025Dataset integrity is fundamental to the safety and reliability of AI systems, especially in autonomous driving. This paper presents a structured framework for developing safe datasets aligned with ISO/PAS 8800 guidelines. Using AI-based perception systems as the primary use case, it introduces the AI Data Flywheel and the dataset lifecycle, covering data collection, annotation, curation, and maintenance. The framework incorporates rigorous safety analyses to identify hazards and mitigate risks caused by dataset insufficiencies. It also defines processes for establishing dataset safety requirements and proposes verification and validation strategies to ensure compliance with safety standards. In addition to outlining best practices, the paper reviews recent research and emerging trends in dataset safety and autonomous vehicle development, providing insights into current challenges and future directions. By integrating these perspectives, the paper aims to advance robust, safety-assured AI systems for autonomous driving applications.
CleverDistiller: Simple and Spatially Consistent Cross-modal Distillation
Mar 12, 2025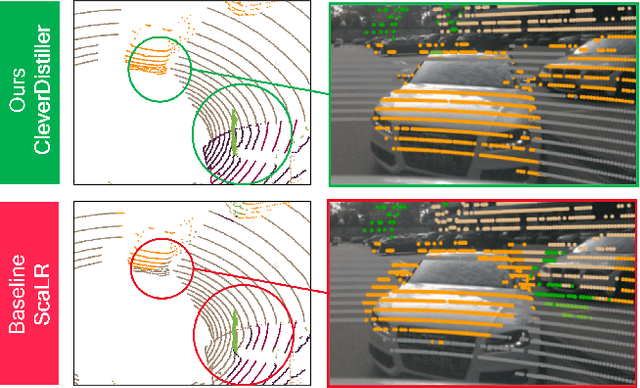
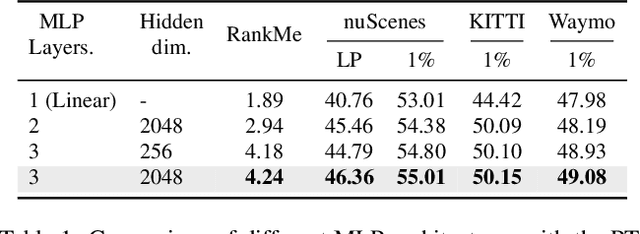
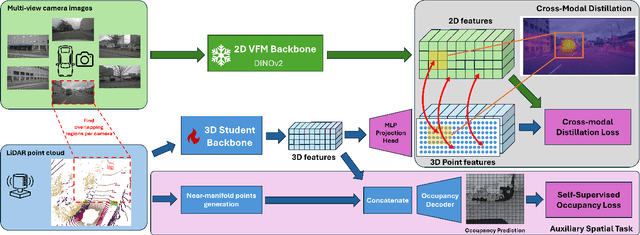
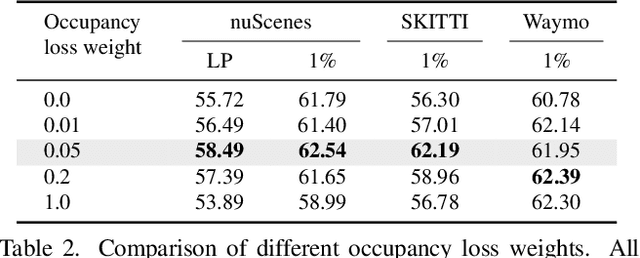
Vision foundation models (VFMs) such as DINO have led to a paradigm shift in 2D camera-based perception towards extracting generalized features to support many downstream tasks. Recent works introduce self-supervised cross-modal knowledge distillation (KD) as a way to transfer these powerful generalization capabilities into 3D LiDAR-based models. However, they either rely on highly complex distillation losses, pseudo-semantic maps, or limit KD to features useful for semantic segmentation only. In this work, we propose CleverDistiller, a self-supervised, cross-modal 2D-to-3D KD framework introducing a set of simple yet effective design choices: Unlike contrastive approaches relying on complex loss design choices, our method employs a direct feature similarity loss in combination with a multi layer perceptron (MLP) projection head to allow the 3D network to learn complex semantic dependencies throughout the projection. Crucially, our approach does not depend on pseudo-semantic maps, allowing for direct knowledge transfer from a VFM without explicit semantic supervision. Additionally, we introduce the auxiliary self-supervised spatial task of occupancy prediction to enhance the semantic knowledge, obtained from a VFM through KD, with 3D spatial reasoning capabilities. Experiments on standard autonomous driving benchmarks for 2D-to-3D KD demonstrate that CleverDistiller achieves state-of-the-art performance in both semantic segmentation and 3D object detection (3DOD) by up to 10% mIoU, especially when fine tuning on really low data amounts, showing the effectiveness of our simple yet powerful KD strategy
LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
May 29, 2024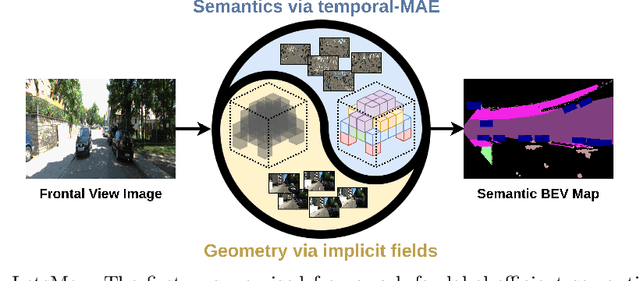
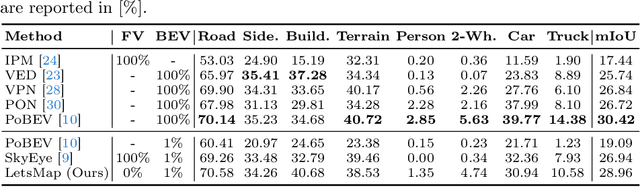
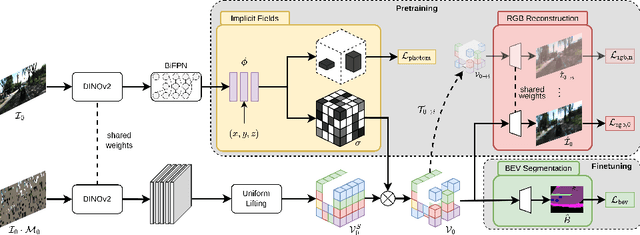
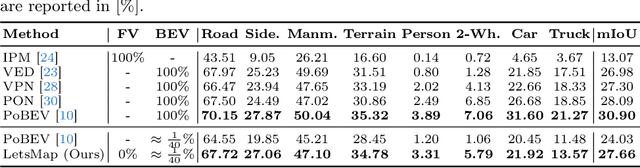
Semantic Bird's Eye View (BEV) maps offer a rich representation with strong occlusion reasoning for various decision making tasks in autonomous driving. However, most BEV mapping approaches employ a fully supervised learning paradigm that relies on large amounts of human-annotated BEV ground truth data. In this work, we address this limitation by proposing the first unsupervised representation learning approach to generate semantic BEV maps from a monocular frontal view (FV) image in a label-efficient manner. Our approach pretrains the network to independently reason about scene geometry and scene semantics using two disjoint neural pathways in an unsupervised manner and then finetunes it for the task of semantic BEV mapping using only a small fraction of labels in the BEV. We achieve label-free pretraining by exploiting spatial and temporal consistency of FV images to learn scene geometry while relying on a novel temporal masked autoencoder formulation to encode the scene representation. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach performs on par with the existing state-of-the-art approaches while using only 1% of BEV labels and no additional labeled data.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024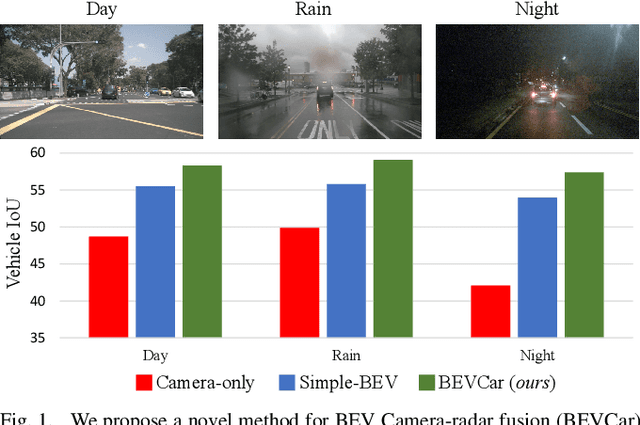
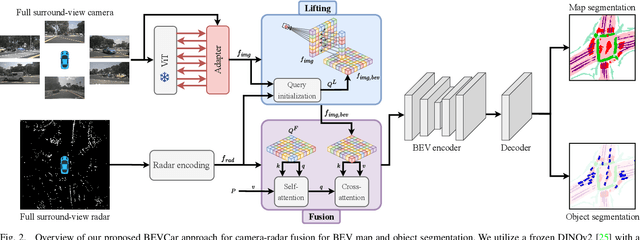
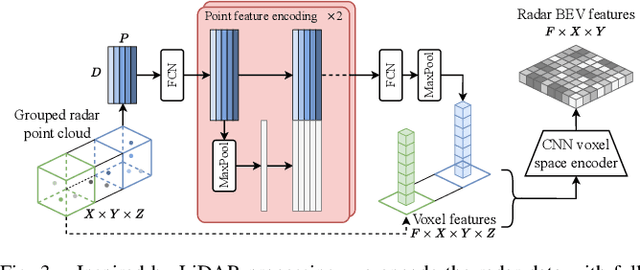
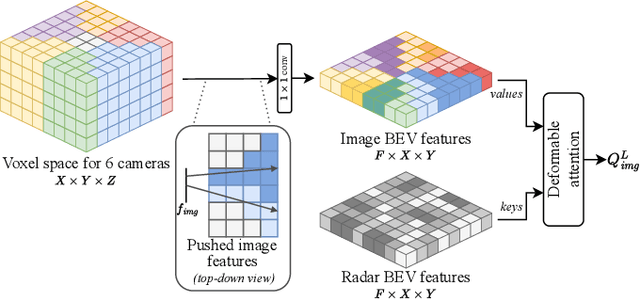
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
Evaluating the effect of data augmentation and BALD heuristics on distillation of Semantic-KITTI dataset
Feb 21, 2023Active Learning (AL) has remained relatively unexplored for LiDAR perception tasks in autonomous driving datasets. In this study we evaluate Bayesian active learning methods applied to the task of dataset distillation or core subset selection (subset with near equivalent performance as full dataset). We also study the effect of application of data augmentation (DA) within Bayesian AL based dataset distillation. We perform these experiments on the full Semantic-KITTI dataset. We extend our study over our existing work only on 1/4th of the same dataset. Addition of DA and BALD have a negative impact over the labeling efficiency and thus the capacity to distill datasets. We demonstrate key issues in designing a functional AL framework and finally conclude with a review of challenges in real world active learning.
Navya3DSeg -- Navya 3D Semantic Segmentation Dataset & split generation for autonomous vehicles
Feb 16, 2023



Autonomous driving (AD) perception today relies heavily on deep learning based architectures requiring large scale annotated datasets with their associated costs for curation and annotation. The 3D semantic data are useful for core perception tasks such as obstacle detection and ego-vehicle localization. We propose a new dataset, Navya 3D Segmentation (Navya3DSeg), with a diverse label space corresponding to a large scale production grade operational domain, including rural, urban, industrial sites and universities from 13 countries. It contains 23 labeled sequences and 25 supplementary sequences without labels, designed to explore self-supervised and semi-supervised semantic segmentation benchmarks on point clouds. We also propose a novel method for sequential dataset split generation based on iterative multi-label stratification, and demonstrated to achieve a +1.2% mIoU improvement over the original split proposed by SemanticKITTI dataset. A complete benchmark for semantic segmentation task was performed, with state of the art methods. Finally, we demonstrate an active learning (AL) based dataset distillation framework. We introduce a novel heuristic-free sampling method called distance sampling in the context of AL. A detailed presentation on the dataset is available at https://www.youtube.com/watch?v=5m6ALIs-s20 .
Self-Supervised 3D Monocular Object Detection by Recycling Bounding Boxes
Jun 25, 2022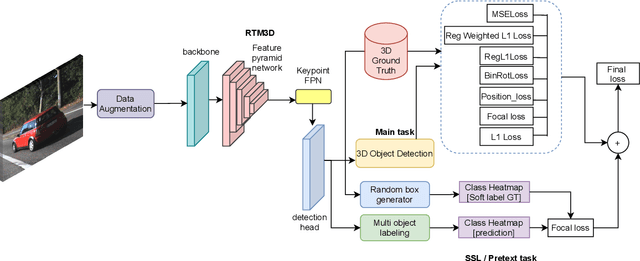
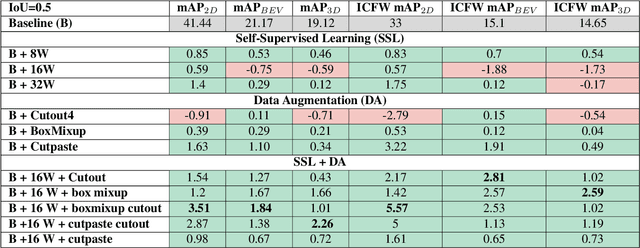
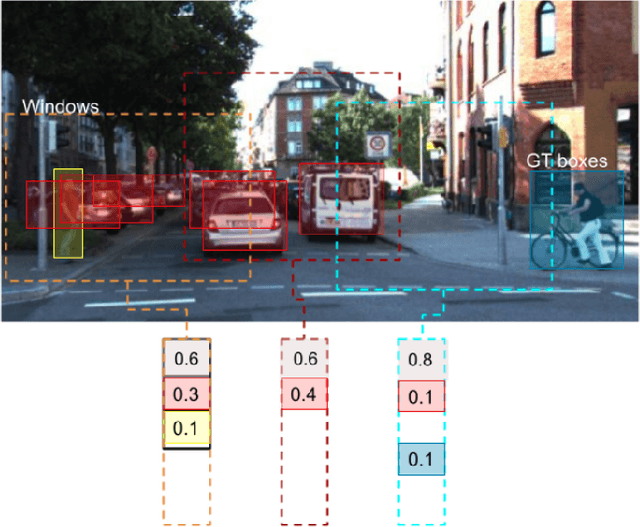

Modern object detection architectures are moving towards employing self-supervised learning (SSL) to improve performance detection with related pretext tasks. Pretext tasks for monocular 3D object detection have not yet been explored yet in literature. The paper studies the application of established self-supervised bounding box recycling by labeling random windows as the pretext task. The classifier head of the 3D detector is trained to classify random windows containing different proportions of the ground truth objects, thus handling the foreground-background imbalance. We evaluate the pretext task using the RTM3D detection model as baseline, with and without the application of data augmentation. We demonstrate improvements of between 2-3 % in mAP 3D and 0.9-1.5 % BEV scores using SSL over the baseline scores. We propose the inverse class frequency re-weighted (ICFW) mAP score that highlights improvements in detection for low frequency classes in a class imbalanced dataset with long tails. We demonstrate improvements in ICFW both mAP 3D and BEV scores to take into account the class imbalance in the KITTI validation dataset. We see 4-5 % increase in ICFW metric with the pretext task.
Simulation-to-Reality domain adaptation for offline 3D object annotation on pointclouds with correlation alignment
Feb 06, 2022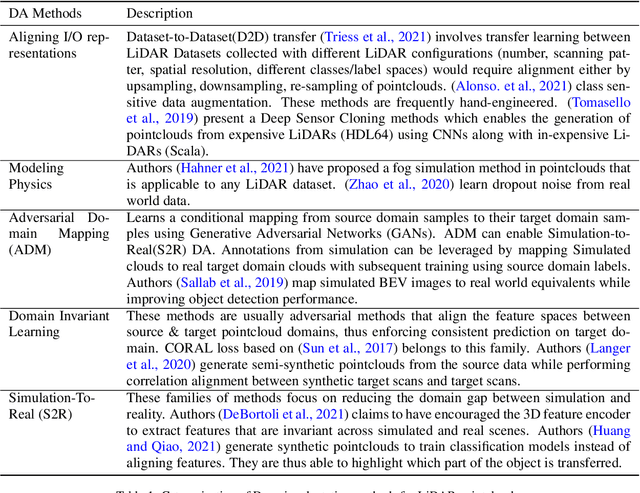
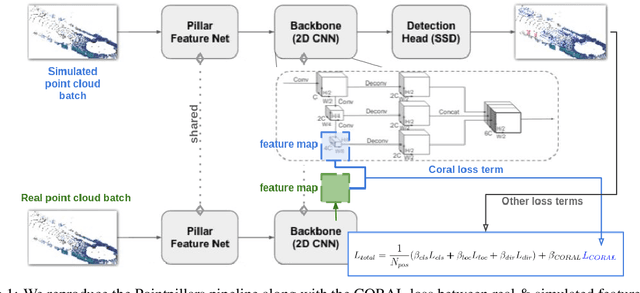
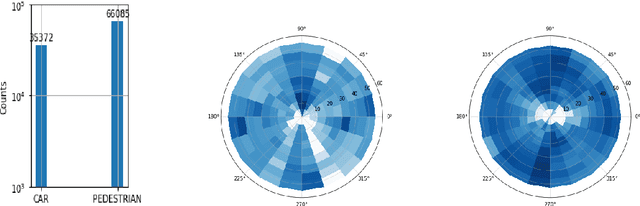
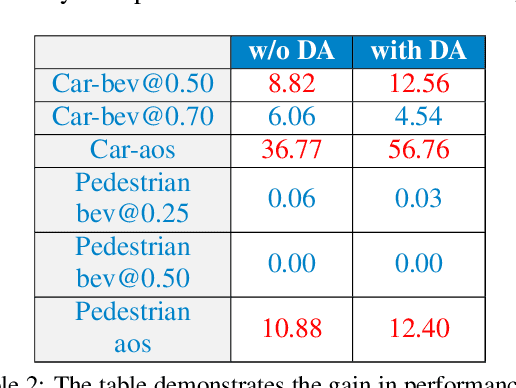
Annotating objects with 3D bounding boxes in LiDAR pointclouds is a costly human driven process in an autonomous driving perception system. In this paper, we present a method to semi-automatically annotate real-world pointclouds collected by deployment vehicles using simulated data. We train a 3D object detector model on labeled simulated data from CARLA jointly with real world pointclouds from our target vehicle. The supervised object detection loss is augmented with a CORAL loss term to reduce the distance between labeled simulated and unlabeled real pointcloud feature representations. The goal here is to learn representations that are invariant to simulated (labeled) and real-world (unlabeled) target domains. We also provide an updated survey on domain adaptation methods for pointclouds.
LiDAR dataset distillation within bayesian active learning framework: Understanding the effect of data augmentation
Feb 06, 2022


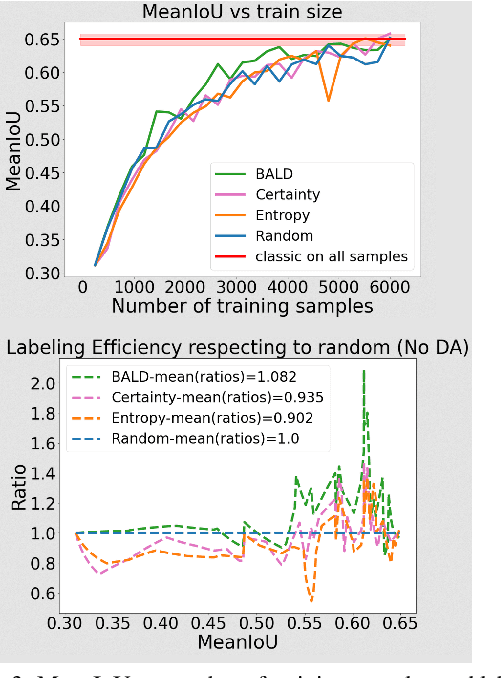
Autonomous driving (AD) datasets have progressively grown in size in the past few years to enable better deep representation learning. Active learning (AL) has re-gained attention recently to address reduction of annotation costs and dataset size. AL has remained relatively unexplored for AD datasets, especially on point cloud data from LiDARs. This paper performs a principled evaluation of AL based dataset distillation on (1/4th) of the large Semantic-KITTI dataset. Further on, the gains in model performance due to data augmentation (DA) are demonstrated across different subsets of the AL loop. We also demonstrate how DA improves the selection of informative samples to annotate. We observe that data augmentation achieves full dataset accuracy using only 60\% of samples from the selected dataset configuration. This provides faster training time and subsequent gains in annotation costs.