 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIX: Learning to Plan from Raw Pixels for End-to-End Autonomous Driving
Jul 24, 2025While end-to-end autonomous driving models show promising results, their practical deployment is often hindered by large model sizes, a reliance on expensive LiDAR sensors and computationally intensive BEV feature representations. This limits their scalability, especially for mass-market vehicles equipped only with cameras. To address these challenges, we propose PRIX (Plan from Raw Pixels). Our novel and efficient end-to-end driving architecture operates using only camera data, without explicit BEV representation and forgoing the need for LiDAR. PRIX leverages a visual feature extractor coupled with a generative planning head to predict safe trajectories from raw pixel inputs directly. A core component of our architecture is the Context-aware Recalibration Transformer (CaRT), a novel module designed to effectively enhance multi-level visual features for more robust planning. We demonstrate through comprehensive experiments that PRIX achieves state-of-the-art performance on the NavSim and nuScenes benchmarks, matching the capabilities of larger, multimodal diffusion planners while being significantly more efficient in terms of inference speed and model size, making it a practical solution for real-world deployment. Our work is open-source and the code will be at https://maxiuw.github.io/prix.
CleverDistiller: Simple and Spatially Consistent Cross-modal Distillation
Mar 12, 2025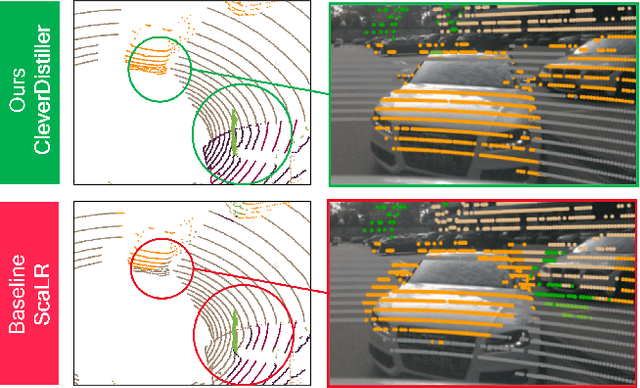
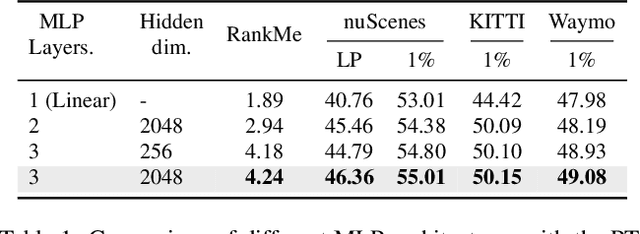
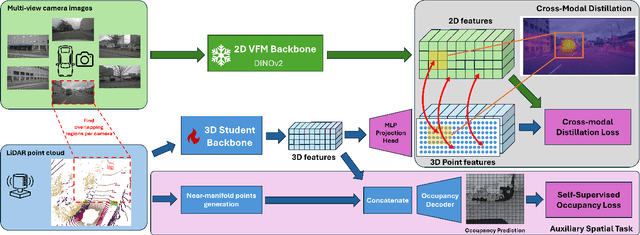
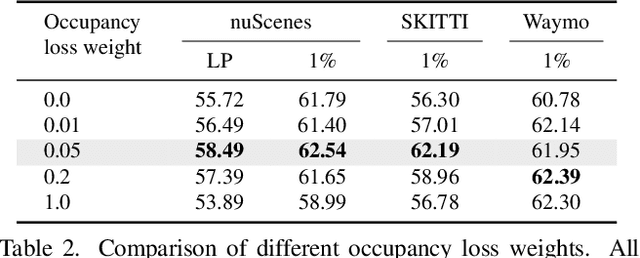
Vision foundation models (VFMs) such as DINO have led to a paradigm shift in 2D camera-based perception towards extracting generalized features to support many downstream tasks. Recent works introduce self-supervised cross-modal knowledge distillation (KD) as a way to transfer these powerful generalization capabilities into 3D LiDAR-based models. However, they either rely on highly complex distillation losses, pseudo-semantic maps, or limit KD to features useful for semantic segmentation only. In this work, we propose CleverDistiller, a self-supervised, cross-modal 2D-to-3D KD framework introducing a set of simple yet effective design choices: Unlike contrastive approaches relying on complex loss design choices, our method employs a direct feature similarity loss in combination with a multi layer perceptron (MLP) projection head to allow the 3D network to learn complex semantic dependencies throughout the projection. Crucially, our approach does not depend on pseudo-semantic maps, allowing for direct knowledge transfer from a VFM without explicit semantic supervision. Additionally, we introduce the auxiliary self-supervised spatial task of occupancy prediction to enhance the semantic knowledge, obtained from a VFM through KD, with 3D spatial reasoning capabilities. Experiments on standard autonomous driving benchmarks for 2D-to-3D KD demonstrate that CleverDistiller achieves state-of-the-art performance in both semantic segmentation and 3D object detection (3DOD) by up to 10% mIoU, especially when fine tuning on really low data amounts, showing the effectiveness of our simple yet powerful KD strategy
S3PT: Scene Semantics and Structure Guided Clustering to Boost Self-Supervised Pre-Training for Autonomous Driving
Oct 30, 2024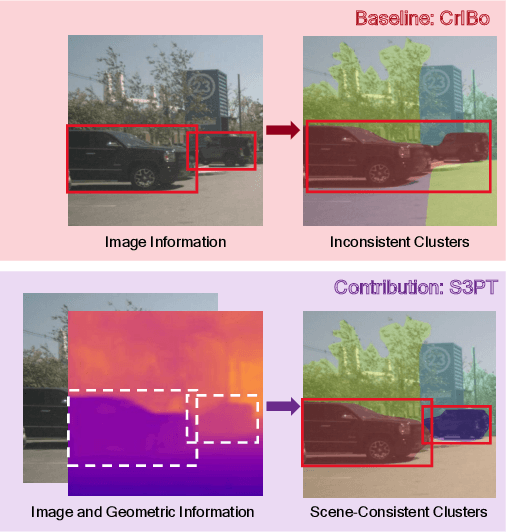
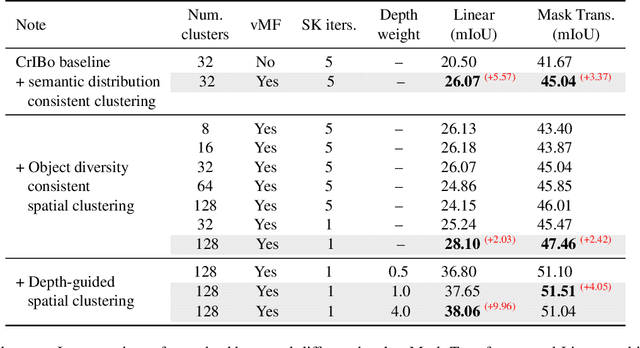
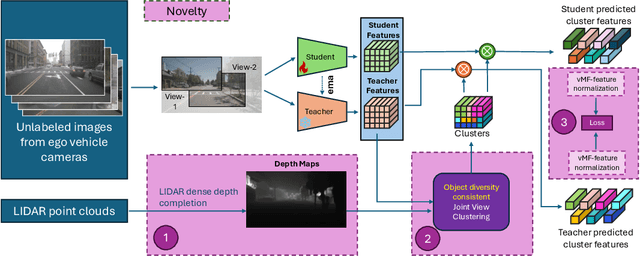
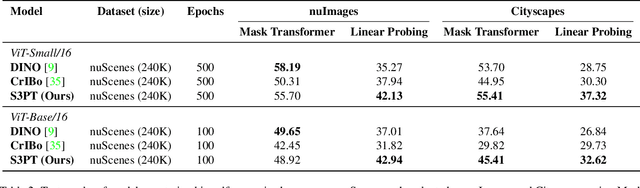
Recent self-supervised clustering-based pre-training techniques like DINO and Cribo have shown impressive results for downstream detection and segmentation tasks. However, real-world applications such as autonomous driving face challenges with imbalanced object class and size distributions and complex scene geometries. In this paper, we propose S3PT a novel scene semantics and structure guided clustering to provide more scene-consistent objectives for self-supervised training. Specifically, our contributions are threefold: First, we incorporate semantic distribution consistent clustering to encourage better representation of rare classes such as motorcycles or animals. Second, we introduce object diversity consistent spatial clustering, to handle imbalanced and diverse object sizes, ranging from large background areas to small objects such as pedestrians and traffic signs. Third, we propose a depth-guided spatial clustering to regularize learning based on geometric information of the scene, thus further refining region separation on the feature level. Our learned representations significantly improve performance in downstream semantic segmentation and 3D object detection tasks on the nuScenes, nuImages, and Cityscapes datasets and show promising domain translation properties.
Low-Cost Teleoperation with Haptic Feedback through Vision-based Tactile Sensors for Rigid and Soft Object Manipulation
Mar 25, 2024



Haptic feedback is essential for humans to successfully perform complex and delicate manipulation tasks. A recent rise in tactile sensors has enabled robots to leverage the sense of touch and expand their capability drastically. However, many tasks still need human intervention/guidance. For this reason, we present a teleoperation framework designed to provide haptic feedback to human operators based on the data from camera-based tactile sensors mounted on the robot gripper. Partial autonomy is introduced to prevent slippage of grasped objects during task execution. Notably, we rely exclusively on low-cost off-the-shelf hardware to realize an affordable solution. We demonstrate the versatility of the framework on nine different objects ranging from rigid to soft and fragile ones, using three different operators on real hardware.
Happily Error After: Framework Development and User Study for Correcting Robot Perception Errors in Virtual Reality
Jun 26, 2023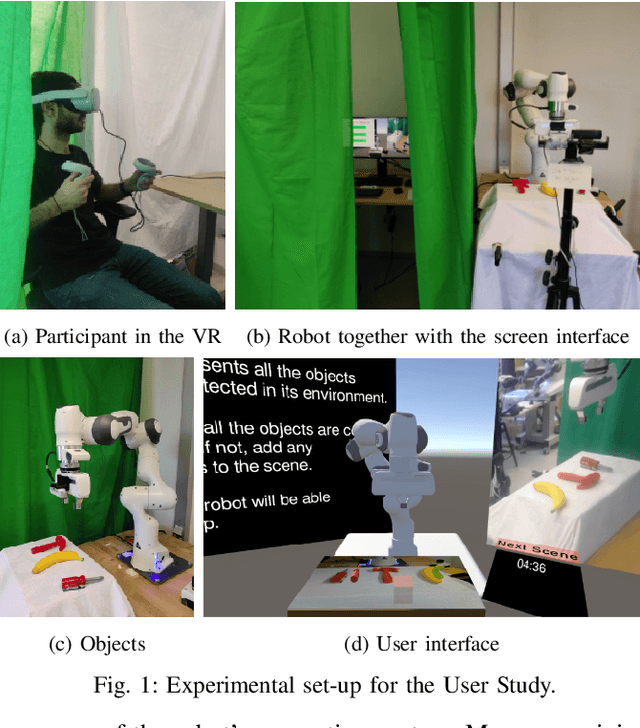
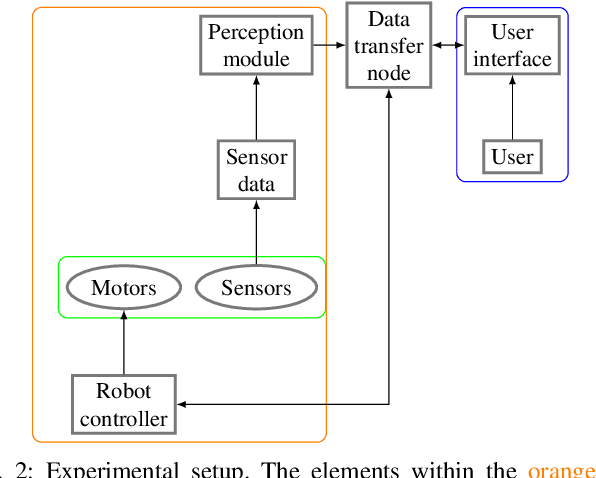
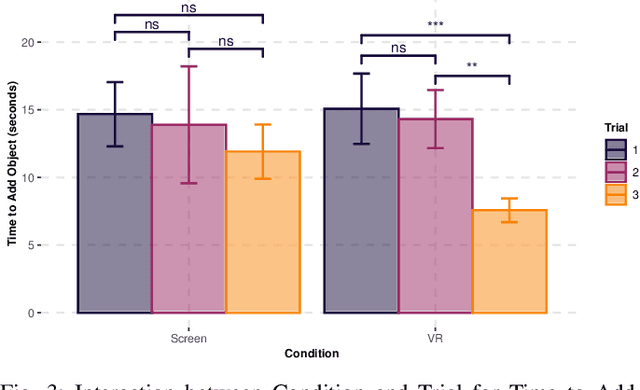
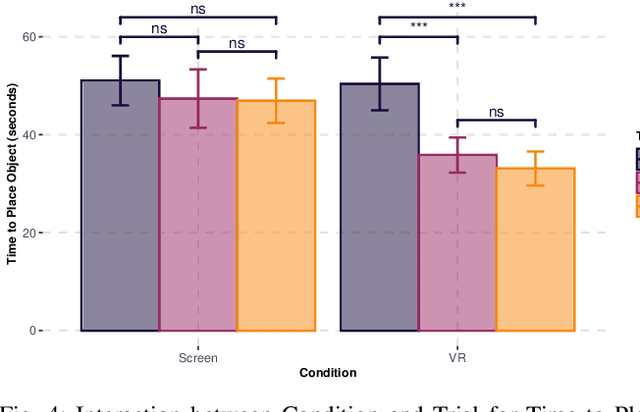
While we can see robots in more areas of our lives, they still make errors. One common cause of failure stems from the robot perception module when detecting objects. Allowing users to correct such errors can help improve the interaction and prevent the same errors in the future. Consequently, we investigate the effectiveness of a virtual reality (VR) framework for correcting perception errors of a Franka Panda robot. We conducted a user study with 56 participants who interacted with the robot using both VR and screen interfaces. Participants learned to collaborate with the robot faster in the VR interface compared to the screen interface. Additionally, participants found the VR interface more immersive, enjoyable, and expressed a preference for using it again. These findings suggest that VR interfaces may offer advantages over screen interfaces for human-robot interaction in erroneous environments.
Towards a Robust Sensor Fusion Step for 3D Object Detection on Corrupted Data
Jun 12, 2023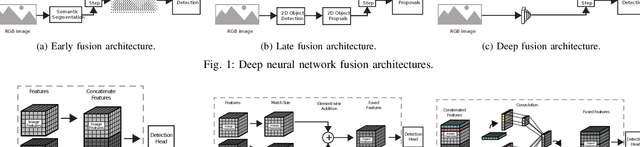
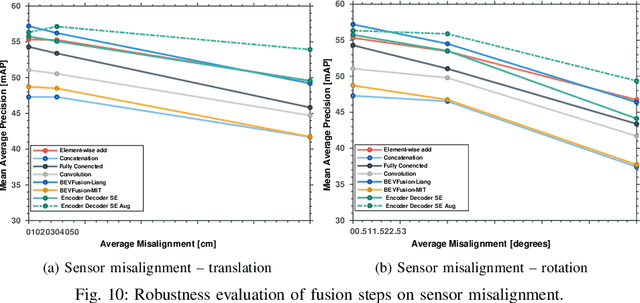
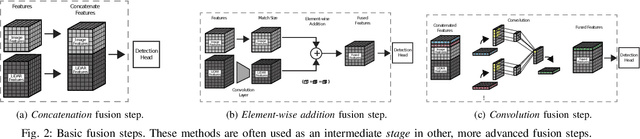
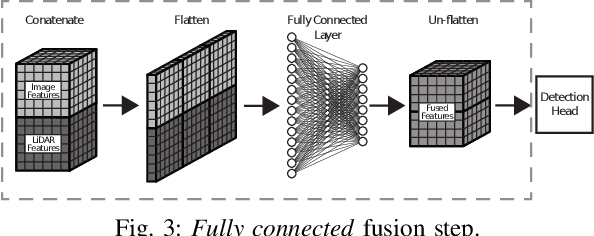
Multimodal sensor fusion methods for 3D object detection have been revolutionizing the autonomous driving research field. Nevertheless, most of these methods heavily rely on dense LiDAR data and accurately calibrated sensors which is often not the case in real-world scenarios. Data from LiDAR and cameras often come misaligned due to the miscalibration, decalibration, or different frequencies of the sensors. Additionally, some parts of the LiDAR data may be occluded and parts of the data may be missing due to hardware malfunction or weather conditions. This work presents a novel fusion step that addresses data corruptions and makes sensor fusion for 3D object detection more robust. Through extensive experiments, we demonstrate that our method performs on par with state-of-the-art approaches on normal data and outperforms them on misaligned data.
A Virtual Reality Framework for Human-Robot Collaboration in Cloth Folding
May 12, 2023We present a virtual reality (VR) framework to automate the data collection process in cloth folding tasks. The framework uses skeleton representations to help the user define the folding plans for different classes of garments, allowing for replicating the folding on unseen items of the same class. We evaluate the framework in the context of automating garment folding tasks. A quantitative analysis is performed on 3 classes of garments, demonstrating that the framework reduces the need for intervention by the user. We also compare skeleton representations with RGB and binary images in a classification task on a large dataset of clothing items, motivating the use of the framework for other classes of garments.
What you see is what you get: A VR Framework for Correcting Robot Errors
Jan 17, 2023
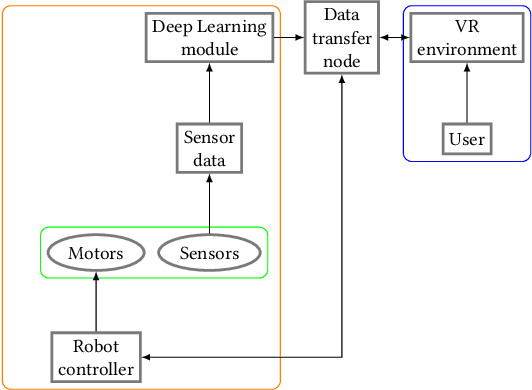
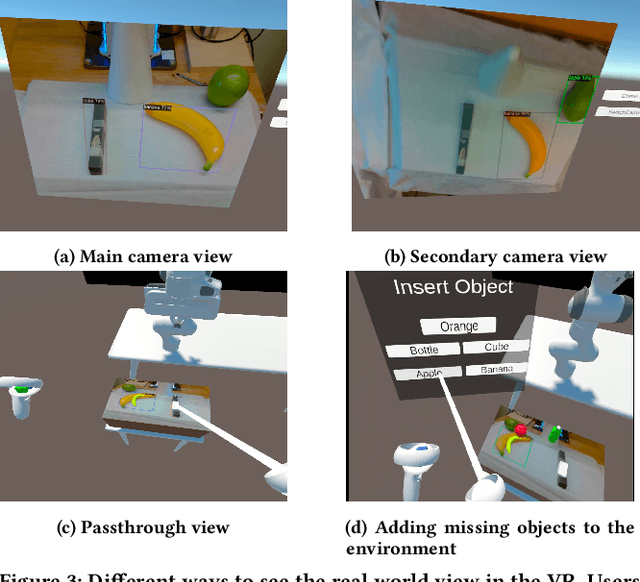
Many solutions tailored for intuitive visualization or teleoperation of virtual, augmented and mixed (VAM) reality systems are not robust to robot failures, such as the inability to detect and recognize objects in the environment or planning unsafe trajectories. In this paper, we present a novel virtual reality (VR) framework where users can (i) recognize when the robot has failed to detect a real-world object, (ii) correct the error in VR, (iii) modify proposed object trajectories and, (iv) implement behaviors on a real-world robot. Finally, we propose a user study aimed at testing the efficacy of our framework. Project materials can be found in the OSF repository.
FCMpy: A Python Module for Constructing and Analyzing Fuzzy Cognitive Maps
Nov 24, 2021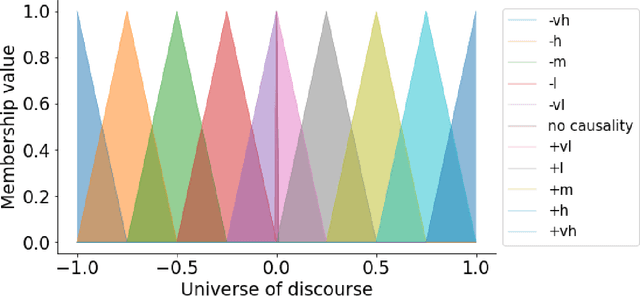


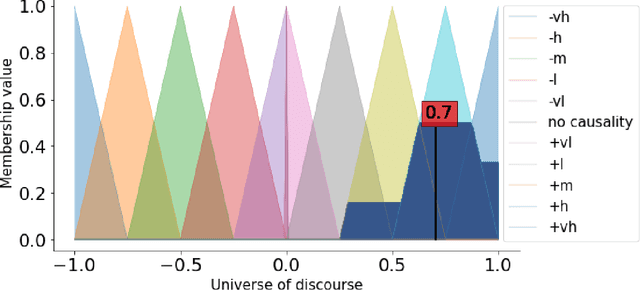
FCMpy is an open source package in Python for building and analyzing Fuzzy Cognitive Maps. More specifically, the package allows 1) deriving fuzzy causal weights from qualitative data, 2) simulating the system behavior, 3) applying machine learning algorithms (e.g., Nonlinear Hebbian Learning, Active Hebbian Learning, Genetic Algorithms and Deterministic Learning) to adjust the FCM causal weight matrix and to solve classification problems, and 4) implementing scenario analysis by simulating hypothetical interventions (i.e., analyzing what-if scenarios).