 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Guide to Large Language Models in Modeling and Simulation: From Core Techniques to Critical Challenges
Feb 05, 2026Large language models (LLMs) have rapidly become familiar tools to researchers and practitioners. Concepts such as prompting, temperature, or few-shot examples are now widely recognized, and LLMs are increasingly used in Modeling & Simulation (M&S) workflows. However, practices that appear straightforward may introduce subtle issues, unnecessary complexity, or may even lead to inferior results. Adding more data can backfire (e.g., deteriorating performance through model collapse or inadvertently wiping out existing guardrails), spending time on fine-tuning a model can be unnecessary without a prior assessment of what it already knows, setting the temperature to 0 is not sufficient to make LLMs deterministic, providing a large volume of M&S data as input can be excessive (LLMs cannot attend to everything) but naive simplifications can lose information. We aim to provide comprehensive and practical guidance on how to use LLMs, with an emphasis on M&S applications. We discuss common sources of confusion, including non-determinism, knowledge augmentation (including RAG and LoRA), decomposition of M&S data, and hyper-parameter settings. We emphasize principled design choices, diagnostic strategies, and empirical evaluation, with the goal of helping modelers make informed decisions about when, how, and whether to rely on LLMs.
Towards Personalized Explanations for Health Simulations: A Mixed-Methods Framework for Stakeholder-Centric Summarization
Sep 04, 2025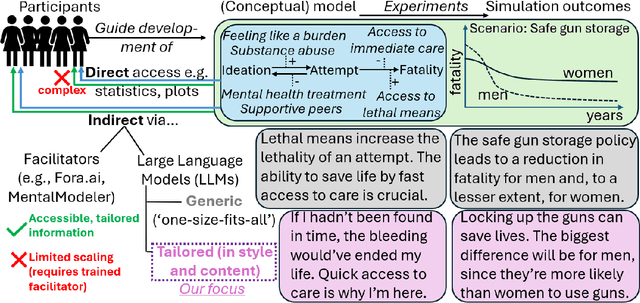
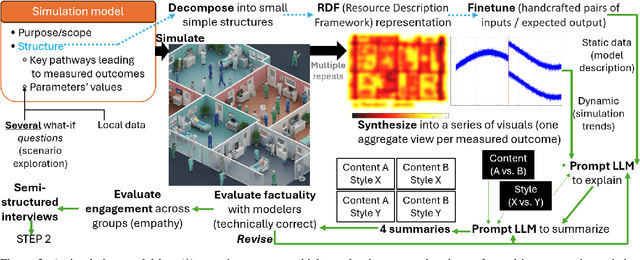
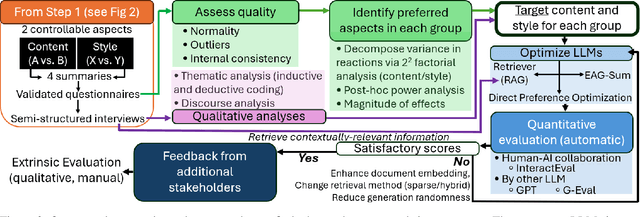
Modeling & Simulation (M&S) approaches such as agent-based models hold significant potential to support decision-making activities in health, with recent examples including the adoption of vaccines, and a vast literature on healthy eating behaviors and physical activity behaviors. These models are potentially usable by different stakeholder groups, as they support policy-makers to estimate the consequences of potential interventions and they can guide individuals in making healthy choices in complex environments. However, this potential may not be fully realized because of the models' complexity, which makes them inaccessible to the stakeholders who could benefit the most. While Large Language Models (LLMs) can translate simulation outputs and the design of models into text, current approaches typically rely on one-size-fits-all summaries that fail to reflect the varied informational needs and stylistic preferences of clinicians, policymakers, patients, caregivers, and health advocates. This limitation stems from a fundamental gap: we lack a systematic understanding of what these stakeholders need from explanations and how to tailor them accordingly. To address this gap, we present a step-by-step framework to identify stakeholder needs and guide LLMs in generating tailored explanations of health simulations. Our procedure uses a mixed-methods design by first eliciting the explanation needs and stylistic preferences of diverse health stakeholders, then optimizing the ability of LLMs to generate tailored outputs (e.g., via controllable attribute tuning), and then evaluating through a comprehensive range of metrics to further improve the tailored generation of summaries.
Accelerating Hybrid Agent-Based Models and Fuzzy Cognitive Maps: How to Combine Agents who Think Alike?
Sep 01, 2024While Agent-Based Models can create detailed artificial societies based on individual differences and local context, they can be computationally intensive. Modelers may offset these costs through a parsimonious use of the model, for example by using smaller population sizes (which limits analyses in sub-populations), running fewer what-if scenarios, or accepting more uncertainty by performing fewer simulations. Alternatively, researchers may accelerate simulations via hardware solutions (e.g., GPU parallelism) or approximation approaches that operate a tradeoff between accuracy and compute time. In this paper, we present an approximation that combines agents who `think alike', thus reducing the population size and the compute time. Our innovation relies on representing agent behaviors as networks of rules (Fuzzy Cognitive Maps) and empirically evaluating different measures of distance between these networks. Then, we form groups of think-alike agents via community detection and simplify them to a representative agent. Case studies show that our simplifications remain accuracy.
Narrating Causal Graphs with Large Language Models
Mar 11, 2024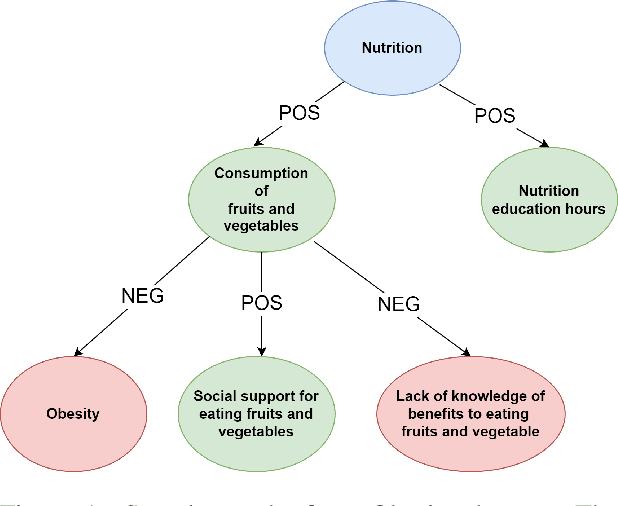
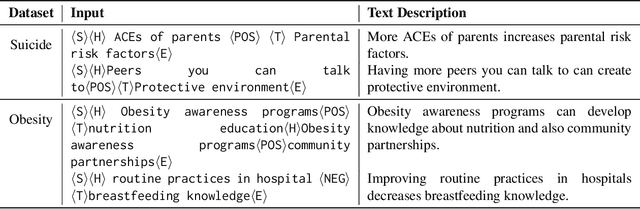

The use of generative AI to create text descriptions from graphs has mostly focused on knowledge graphs, which connect concepts using facts. In this work we explore the capability of large pretrained language models to generate text from causal graphs, where salient concepts are represented as nodes and causality is represented via directed, typed edges. The causal reasoning encoded in these graphs can support applications as diverse as healthcare or marketing. Using two publicly available causal graph datasets, we empirically investigate the performance of four GPT-3 models under various settings. Our results indicate that while causal text descriptions improve with training data, compared to fact-based graphs, they are harder to generate under zero-shot settings. Results further suggest that users of generative AI can deploy future applications faster since similar performances are obtained when training a model with only a few examples as compared to fine-tuning via a large curated dataset.
GPT-Based Models Meet Simulation: How to Efficiently Use Large-Scale Pre-Trained Language Models Across Simulation Tasks
Jun 21, 2023The disruptive technology provided by large-scale pre-trained language models (LLMs) such as ChatGPT or GPT-4 has received significant attention in several application domains, often with an emphasis on high-level opportunities and concerns. This paper is the first examination regarding the use of LLMs for scientific simulations. We focus on four modeling and simulation tasks, each time assessing the expected benefits and limitations of LLMs while providing practical guidance for modelers regarding the steps involved. The first task is devoted to explaining the structure of a conceptual model to promote the engagement of participants in the modeling process. The second task focuses on summarizing simulation outputs, so that model users can identify a preferred scenario. The third task seeks to broaden accessibility to simulation platforms by conveying the insights of simulation visualizations via text. Finally, the last task evokes the possibility of explaining simulation errors and providing guidance to resolve them.
FCMpy: A Python Module for Constructing and Analyzing Fuzzy Cognitive Maps
Nov 24, 2021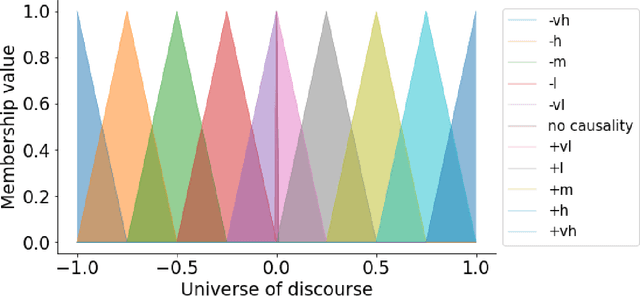


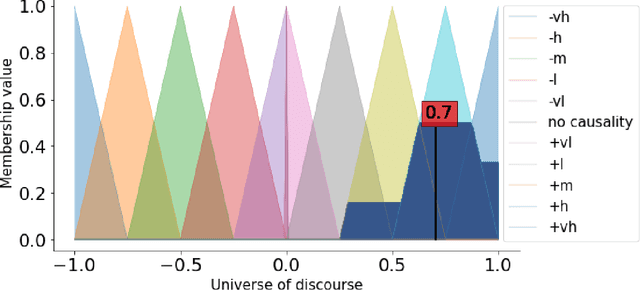
FCMpy is an open source package in Python for building and analyzing Fuzzy Cognitive Maps. More specifically, the package allows 1) deriving fuzzy causal weights from qualitative data, 2) simulating the system behavior, 3) applying machine learning algorithms (e.g., Nonlinear Hebbian Learning, Active Hebbian Learning, Genetic Algorithms and Deterministic Learning) to adjust the FCM causal weight matrix and to solve classification problems, and 4) implementing scenario analysis by simulating hypothetical interventions (i.e., analyzing what-if scenarios).
An Algebra to Merge Heterogeneous Classifiers
Jan 22, 2015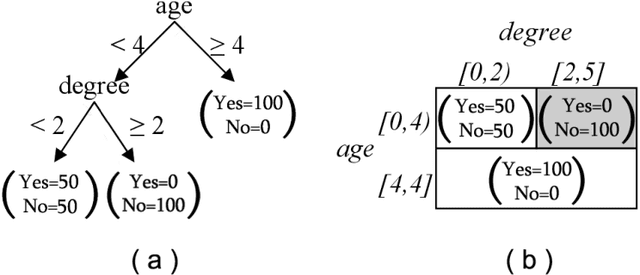
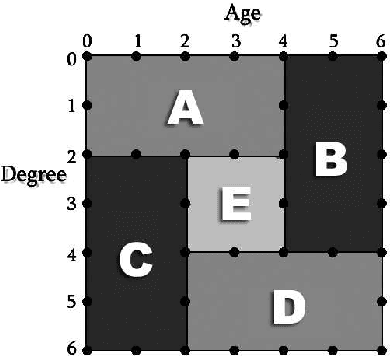
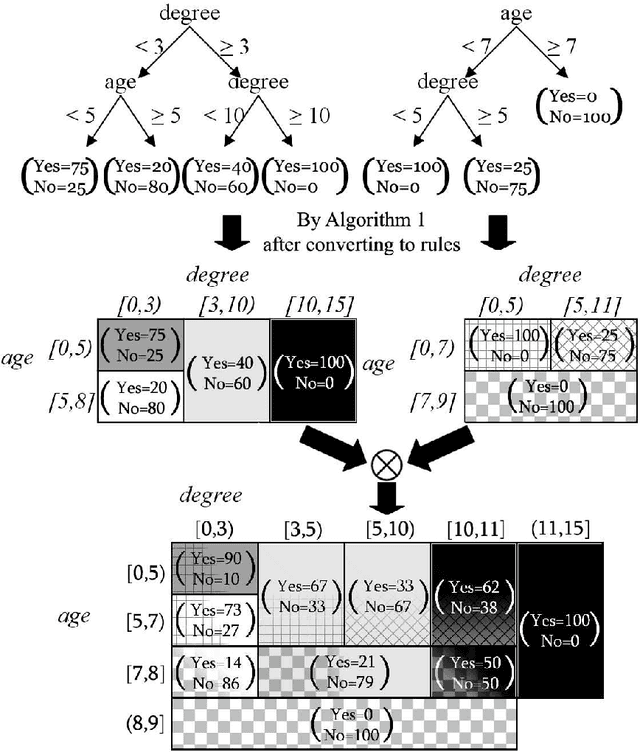
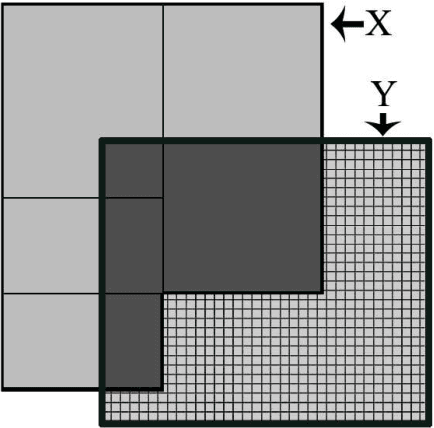
In distributed classification, each learner observes its environment and deduces a classifier. As a learner has only a local view of its environment, classifiers can be exchanged among the learners and integrated, or merged, to improve accuracy. However, the operation of merging is not defined for most classifiers. Furthermore, the classifiers that have to be merged may be of different types in settings such as ad-hoc networks in which several generations of sensors may be creating classifiers. We introduce decision spaces as a framework for merging possibly different classifiers. We formally study the merging operation as an algebra, and prove that it satisfies a desirable set of properties. The impact of time is discussed for the two main data mining settings. Firstly, decision spaces can naturally be used with non-stationary distributions, such as the data collected by sensor networks, as the impact of a model decays over time. Secondly, we introduce an approach for stationary distributions, such as homogeneous databases partitioned over different learners, which ensures that all models have the same impact. We also present a method that uses storage flexibly to achieve different types of decay for non-stationary distributions. Finally, we show that the algebraic approach developed for merging can also be used to analyze the behaviour of other operators.