 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Activation Steering for Multilingual Language Models
Jan 23, 2026Large language models exhibit strong multilingual capabilities, yet significant performance gaps persist between dominant and non-dominant languages. Prior work attributes this gap to imbalances between shared and language-specific neurons in multilingual representations. We propose Cross-Lingual Activation Steering (CLAS), a training-free inference-time intervention that selectively modulates neuron activations. We evaluate CLAS on classification and generation benchmarks, achieving average improvements of 2.3% (Acc.) and 3.4% (F1) respectively, while maintaining high-resource language performance. We discover that effective transfer operates through functional divergence rather than strict alignment; performance gains correlate with increased language cluster separation. Our results demonstrate that targeted activation steering can unlock latent multilingual capacity in existing models without modification to model weights.
From Policy to Logic for Efficient and Interpretable Coverage Assessment
Jan 08, 2026Large Language Models (LLMs) have demonstrated strong capabilities in interpreting lengthy, complex legal and policy language. However, their reliability can be undermined by hallucinations and inconsistencies, particularly when analyzing subjective and nuanced documents. These challenges are especially critical in medical coverage policy review, where human experts must be able to rely on accurate information. In this paper, we present an approach designed to support human reviewers by making policy interpretation more efficient and interpretable. We introduce a methodology that pairs a coverage-aware retriever with symbolic rule-based reasoning to surface relevant policy language, organize it into explicit facts and rules, and generate auditable rationales. This hybrid system minimizes the number of LLM inferences required which reduces overall model cost. Notably, our approach achieves a 44% reduction in inference cost alongside a 4.5% improvement in F1 score, demonstrating both efficiency and effectiveness.
Self-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
MTQ-Eval: Multilingual Text Quality Evaluation for Language Models
Nov 12, 2025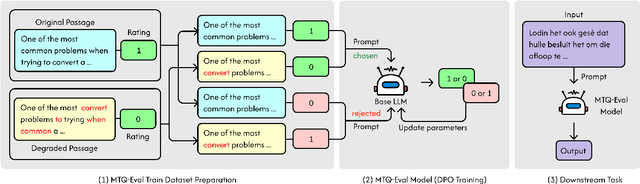



The use of large language models (LLMs) for evaluating outputs is becoming an increasingly effective and scalable approach. However, it remains uncertain whether this capability extends beyond task-specific evaluations to more general assessments of text quality, particularly in multilingual contexts. In this study, we introduce, MTQ-Eval, a novel framework for multilingual text quality evaluation that learns from examples of both high- and low-quality texts, adjusting its internal representations. To develop MTQ-Eval, we first automatically generate text quality preference data and then use it to train open-source base LLMs to align with ratings of high- and low-quality text. Our comprehensive evaluation across 115 languages demonstrates the improved performance of the proposed model. Upon further analysis, we find that this enhanced evaluation capability also leads to notable improvements in downstream tasks.
CAPO: Confidence Aware Preference Optimization Learning for Multilingual Preferences
Nov 10, 2025



Preference optimization is a critical post-training technique used to align large language models (LLMs) with human preferences, typically by fine-tuning on ranked response pairs. While methods like Direct Preference Optimization (DPO) have proven effective in English, they often fail to generalize robustly to multilingual settings. We propose a simple yet effective alternative, Confidence-Aware Preference Optimization (CAPO), which replaces DPO's fixed treatment of preference pairs with a dynamic loss scaling mechanism based on a relative reward. By modulating the learning signal according to the confidence in each preference pair, CAPO enhances robustness to noisy or low-margin comparisons, typically encountered in multilingual text. Empirically, CAPO outperforms existing preference optimization baselines by at least 16% in reward accuracy, and improves alignment by widening the gap between preferred and dispreferred responses across languages.
SymCode: A Neurosymbolic Approach to Mathematical Reasoning via Verifiable Code Generation
Oct 29, 2025Large Language Models (LLMs) often struggle with complex mathematical reasoning, where prose-based generation leads to unverified and arithmetically unsound solutions. Current prompting strategies like Chain of Thought still operate within this unreliable medium, lacking a mechanism for deterministic verification. To address these limitations, we introduce SymCode, a neurosymbolic framework that reframes mathematical problem-solving as a task of verifiable code generation using the SymPy library. We evaluate SymCode on challenging benchmarks, including MATH-500 and OlympiadBench, demonstrating significant accuracy improvements of up to 13.6 percentage points over baselines. Our analysis shows that SymCode is not only more token-efficient but also fundamentally shifts model failures from opaque logical fallacies towards transparent, programmatic errors. By grounding LLM reasoning in a deterministic symbolic engine, SymCode represents a key step towards more accurate and trustworthy AI in formal domains.
Correct-Detect: Balancing Performance and Ambiguity Through the Lens of Coreference Resolution in LLMs
Sep 17, 2025Large Language Models (LLMs) are intended to reflect human linguistic competencies. But humans have access to a broad and embodied context, which is key in detecting and resolving linguistic ambiguities, even in isolated text spans. A foundational case of semantic ambiguity is found in the task of coreference resolution: how is a pronoun related to an earlier person mention? This capability is implicit in nearly every downstream task, and the presence of ambiguity at this level can alter performance significantly. We show that LLMs can achieve good performance with minimal prompting in both coreference disambiguation and the detection of ambiguity in coreference, however, they cannot do both at the same time. We present the CORRECT-DETECT trade-off: though models have both capabilities and deploy them implicitly, successful performance balancing these two abilities remains elusive.
Towards Personalized Explanations for Health Simulations: A Mixed-Methods Framework for Stakeholder-Centric Summarization
Sep 04, 2025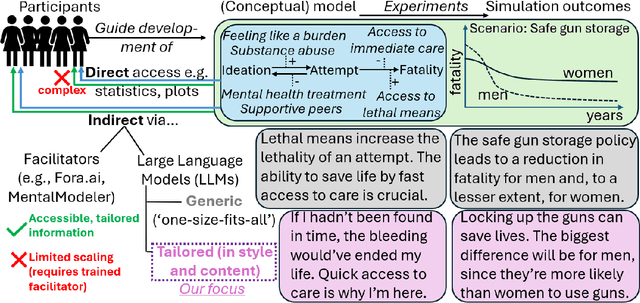
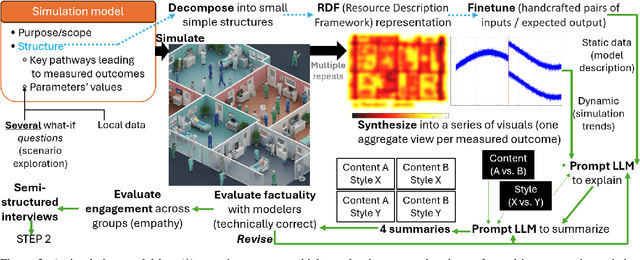
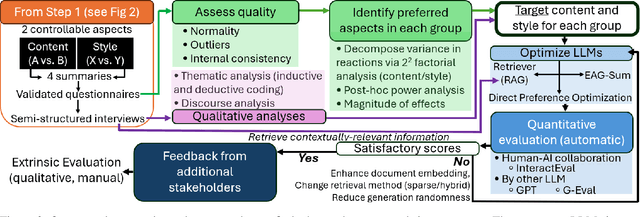
Modeling & Simulation (M&S) approaches such as agent-based models hold significant potential to support decision-making activities in health, with recent examples including the adoption of vaccines, and a vast literature on healthy eating behaviors and physical activity behaviors. These models are potentially usable by different stakeholder groups, as they support policy-makers to estimate the consequences of potential interventions and they can guide individuals in making healthy choices in complex environments. However, this potential may not be fully realized because of the models' complexity, which makes them inaccessible to the stakeholders who could benefit the most. While Large Language Models (LLMs) can translate simulation outputs and the design of models into text, current approaches typically rely on one-size-fits-all summaries that fail to reflect the varied informational needs and stylistic preferences of clinicians, policymakers, patients, caregivers, and health advocates. This limitation stems from a fundamental gap: we lack a systematic understanding of what these stakeholders need from explanations and how to tailor them accordingly. To address this gap, we present a step-by-step framework to identify stakeholder needs and guide LLMs in generating tailored explanations of health simulations. Our procedure uses a mixed-methods design by first eliciting the explanation needs and stylistic preferences of diverse health stakeholders, then optimizing the ability of LLMs to generate tailored outputs (e.g., via controllable attribute tuning), and then evaluating through a comprehensive range of metrics to further improve the tailored generation of summaries.
MFTCXplain: A Multilingual Benchmark Dataset for Evaluating the Moral Reasoning of LLMs through Hate Speech Multi-hop Explanation
Jun 23, 2025Ensuring the moral reasoning capabilities of Large Language Models (LLMs) is a growing concern as these systems are used in socially sensitive tasks. Nevertheless, current evaluation benchmarks present two major shortcomings: a lack of annotations that justify moral classifications, which limits transparency and interpretability; and a predominant focus on English, which constrains the assessment of moral reasoning across diverse cultural settings. In this paper, we introduce MFTCXplain, a multilingual benchmark dataset for evaluating the moral reasoning of LLMs via hate speech multi-hop explanation using Moral Foundation Theory (MFT). The dataset comprises 3,000 tweets across Portuguese, Italian, Persian, and English, annotated with binary hate speech labels, moral categories, and text span-level rationales. Empirical results highlight a misalignment between LLM outputs and human annotations in moral reasoning tasks. While LLMs perform well in hate speech detection (F1 up to 0.836), their ability to predict moral sentiments is notably weak (F1 < 0.35). Furthermore, rationale alignment remains limited mainly in underrepresented languages. These findings show the limited capacity of current LLMs to internalize and reflect human moral reasoning.
Who Relies More on World Knowledge and Bias for Syntactic Ambiguity Resolution: Humans or LLMs?
Mar 13, 2025This study explores how recent large language models (LLMs) navigate relative clause attachment {ambiguity} and use world knowledge biases for disambiguation in six typologically diverse languages: English, Chinese, Japanese, Korean, Russian, and Spanish. We describe the process of creating a novel dataset -- MultiWho -- for fine-grained evaluation of relative clause attachment preferences in ambiguous and unambiguous contexts. Our experiments with three LLMs indicate that, contrary to humans, LLMs consistently exhibit a preference for local attachment, displaying limited responsiveness to syntactic variations or language-specific attachment patterns. Although LLMs performed well in unambiguous cases, they rigidly prioritized world knowledge biases, lacking the flexibility of human language processing. These findings highlight the need for more diverse, pragmatically nuanced multilingual training to improve LLMs' handling of complex structures and human-like comprehension.