 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Culturally Grounded Natural Language Processing
Mar 27, 2026Recent progress in multilingual NLP is often taken as evidence of broader global inclusivity, but a growing literature shows that multilingual capability and cultural competence come apart. This paper synthesizes over 50 papers from 2020--2026 spanning multilingual performance inequality, cross-lingual transfer, culture-aware evaluation, cultural alignment, multimodal local-knowledge modeling, benchmark design critiques, and community-grounded data practices. Across this literature, training data coverage remains a strong determinant of performance, yet it is not sufficient: tokenization, prompt language, translated benchmark design, culturally specific supervision, and multimodal context all materially affect outcomes. Recent work on Global-MMLU, CDEval, WorldValuesBench, CulturalBench, CULEMO, CulturalVQA, GIMMICK, DRISHTIKON, WorldCuisines, CARE, CLCA, and newer critiques of benchmark design and community-grounded evaluation shows that strong multilingual models can still flatten local norms, misread culturally grounded cues, and underperform in lower-resource or community-specific settings. We argue that the field should move from treating languages as isolated rows in a benchmark spreadsheet toward modeling communicative ecologies: the institutions, scripts, translation pipelines, domains, modalities, and communities through which language is used. On that basis, we propose a research agenda for culturally grounded NLP centered on richer contextual metadata, culturally stratified evaluation, participatory alignment, within-language variation, and multimodal community-aware design.
Reliable Classroom AI via Neuro-Symbolic Multimodal Reasoning
Mar 24, 2026Classroom AI is rapidly expanding from low-level perception toward higher-level judgments about engagement, confusion, collaboration, and instructional quality. Yet classrooms are among the hardest real-world settings for multimodal vision: they are multi-party, noisy, privacy-sensitive, pedagogically diverse, and often multilingual. In this paper, we argue that classroom AI should be treated as a critical domain, where raw predictive accuracy is insufficient unless predictions are accompanied by verifiable evidence, calibrated uncertainty, and explicit deployment guardrails. We introduce NSCR, a neuro-symbolic framework that decomposes classroom analytics into four layers: perceptual grounding, symbolic abstraction, executable reasoning, and governance. NSCR adapts recent ideas from symbolic fact extraction and verifiable code generation to multimodal educational settings, enabling classroom observations from video, audio, ASR, and contextual metadata to be converted into typed facts and then composed by executable rules, programs, and policy constraints. Beyond the system design, we contribute a benchmark and evaluation protocol organized around five tasks: classroom state inference, discourse-grounded event linking, temporal early warning, collaboration analysis, and multilingual classroom reasoning. We further specify reliability metrics centered on abstention, calibration, robustness, construct alignment, and human usefulness. The paper does not report new empirical results; its contribution is a concrete framework and evaluation agenda intended to support more interpretable, privacy-aware, and pedagogically grounded multimodal AI for classrooms.
SymCode: A Neurosymbolic Approach to Mathematical Reasoning via Verifiable Code Generation
Oct 29, 2025Large Language Models (LLMs) often struggle with complex mathematical reasoning, where prose-based generation leads to unverified and arithmetically unsound solutions. Current prompting strategies like Chain of Thought still operate within this unreliable medium, lacking a mechanism for deterministic verification. To address these limitations, we introduce SymCode, a neurosymbolic framework that reframes mathematical problem-solving as a task of verifiable code generation using the SymPy library. We evaluate SymCode on challenging benchmarks, including MATH-500 and OlympiadBench, demonstrating significant accuracy improvements of up to 13.6 percentage points over baselines. Our analysis shows that SymCode is not only more token-efficient but also fundamentally shifts model failures from opaque logical fallacies towards transparent, programmatic errors. By grounding LLM reasoning in a deterministic symbolic engine, SymCode represents a key step towards more accurate and trustworthy AI in formal domains.
The Impact of Model Scaling on Seen and Unseen Language Performance
Jan 10, 2025
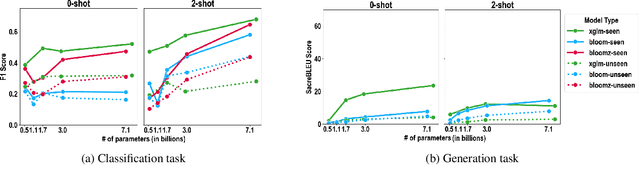
The rapid advancement of Large Language Models (LLMs), particularly those trained on multilingual corpora, has intensified the need for a deeper understanding of their performance across a diverse range of languages and model sizes. Our research addresses this critical need by studying the performance and scaling behavior of multilingual LLMs in text classification and machine translation tasks across 204 languages. We systematically examine both seen and unseen languages across three model families of varying sizes in zero-shot and few-shot settings. Our findings show significant differences in scaling behavior between zero-shot and two-shot scenarios, with striking disparities in performance between seen and unseen languages. Model scale has little effect on zero-shot performance, which remains mostly flat. However, in two-shot settings, larger models show clear linear improvements in multilingual text classification. For translation tasks, however, only the instruction-tuned model showed clear benefits from scaling. Our analysis also suggests that overall resource levels, not just the proportions of pretraining languages, are better predictors of model performance, shedding light on what drives multilingual LLM effectiveness.
Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models
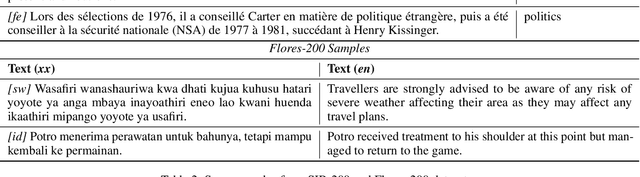
Dec 17, 2024Multilingual language models (MLLMs) are crucial for handling text across various languages, yet they often show performance disparities due to differences in resource availability and linguistic characteristics. While the impact of pre-train data percentage and model size on performance is well-known, our study reveals additional critical factors that significantly influence MLLM effectiveness. Analyzing a wide range of features, including geographical, linguistic, and resource-related aspects, we focus on the SIB-200 dataset for classification and the Flores-200 dataset for machine translation, using regression models and SHAP values across 204 languages. Our findings identify token similarity and country similarity as pivotal factors, alongside pre-train data and model size, in enhancing model performance. Token similarity facilitates cross-lingual transfer, while country similarity highlights the importance of shared cultural and linguistic contexts. These insights offer valuable guidance for developing more equitable and effective multilingual language models, particularly for underrepresented languages.
Fair Summarization: Bridging Quality and Diversity in Extractive Summaries
Nov 13, 2024



Fairness in multi-document summarization of user-generated content remains a critical challenge in natural language processing (NLP). Existing summarization methods often fail to ensure equitable representation across different social groups, leading to biased outputs. In this paper, we introduce two novel methods for fair extractive summarization: FairExtract, a clustering-based approach, and FairGPT, which leverages GPT-3.5-turbo with fairness constraints. We evaluate these methods using Divsumm summarization dataset of White-aligned, Hispanic, and African-American dialect tweets and compare them against relevant baselines. The results obtained using a comprehensive set of summarization quality metrics such as SUPERT, BLANC, SummaQA, BARTScore, and UniEval, as well as a fairness metric F, demonstrate that FairExtract and FairGPT achieve superior fairness while maintaining competitive summarization quality. Additionally, we introduce composite metrics (e.g., SUPERT+F, BLANC+F) that integrate quality and fairness into a single evaluation framework, offering a more nuanced understanding of the trade-offs between these objectives. This work highlights the importance of fairness in summarization and sets a benchmark for future research in fairness-aware NLP models.
Multilingual Evaluation of Long Context Retrieval and Reasoning
Sep 26, 2024Recent large language models (LLMs) demonstrate impressive capabilities in handling long contexts, some exhibiting near-perfect recall on synthetic retrieval tasks. However, these evaluations have mainly focused on English text and involved a single target sentence within lengthy contexts. Our work investigates how LLM performance generalizes to multilingual settings with multiple hidden target sentences. We comprehensively evaluate several long-context LLMs on retrieval and reasoning tasks across five languages: English, Vietnamese, Indonesian, Swahili, and Somali. These languages share the Latin script but belong to distinct language families and resource levels. Our analysis reveals a significant performance gap between languages. The best-performing models such as Gemini-1.5 and GPT-4o, achieve around 96% accuracy in English to around 36% in Somali with a single target sentence. However, this accuracy drops to 40% in English and 0% in Somali when dealing with three target sentences. Our findings highlight the challenges long-context LLMs face when processing longer contexts, an increase in the number of target sentences, or languages of lower resource levels.
What Drives Performance in Multilingual Language Models?
Apr 29, 2024This study investigates the factors influencing the performance of multilingual large language models (MLLMs) across diverse languages. We study 6 MLLMs, including masked language models, autoregressive models, and instruction-tuned LLMs, on the SIB-200 dataset, a topic classification dataset encompassing 204 languages. Our analysis considers three scenarios: ALL languages, SEEN languages (present in the model's pretraining data), and UNSEEN languages (not present or documented in the model's pretraining data in any meaningful way). We examine the impact of factors such as pretraining data size, general resource availability, language family, and script type on model performance. Decision tree analysis reveals that pretraining data size is the most influential factor for SEEN languages. However, interestingly, script type and language family are crucial for UNSEEN languages, highlighting the importance of cross-lingual transfer learning. Notably, model size and architecture do not significantly alter the most important features identified. Our findings provide valuable insights into the strengths and limitations of current MLLMs and hope to guide the development of more effective and equitable multilingual NLP systems.
mBBC: Exploring the Multilingual Maze
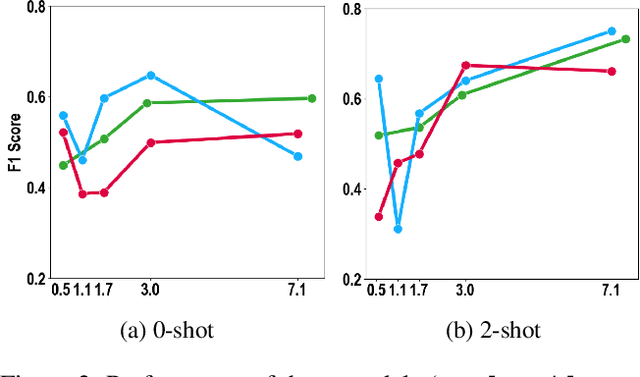
Oct 09, 2023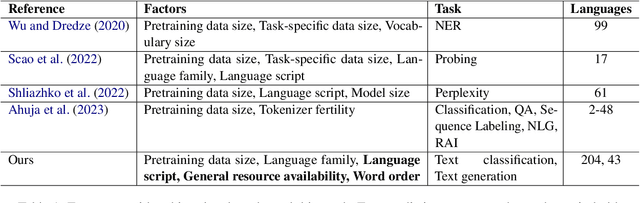


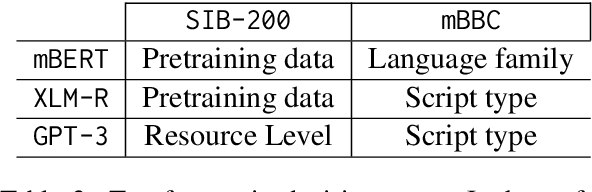
Multilingual language models have gained significant attention in recent years, enabling the development of applications that cater to diverse linguistic contexts. In this paper, we present a comprehensive evaluation of three prominent multilingual language models: mBERT, XLM-R, and GPT-3. Using the self-supervised task of next token prediction, we assess their performance across a diverse set of languages, with a focus on understanding the impact of resource availability, word order, language family, and script type on model accuracy. Our findings reveal that resource availability plays a crucial role in model performance, with higher resource levels leading to improved accuracy. We also identify the complex relationship between resource availability, language families, and script types, highlighting the need for further investigation into language-specific characteristics and structural variations. Additionally, our statistical inference analysis identifies significant features contributing to model performance, providing insights for model selection and deployment. Our study contributes to a deeper understanding of multilingual language models and informs future research and development to enhance their performance and generalizability across languages and linguistic contexts.