 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Activation Steering for Multilingual Language Models
Jan 23, 2026Large language models exhibit strong multilingual capabilities, yet significant performance gaps persist between dominant and non-dominant languages. Prior work attributes this gap to imbalances between shared and language-specific neurons in multilingual representations. We propose Cross-Lingual Activation Steering (CLAS), a training-free inference-time intervention that selectively modulates neuron activations. We evaluate CLAS on classification and generation benchmarks, achieving average improvements of 2.3% (Acc.) and 3.4% (F1) respectively, while maintaining high-resource language performance. We discover that effective transfer operates through functional divergence rather than strict alignment; performance gains correlate with increased language cluster separation. Our results demonstrate that targeted activation steering can unlock latent multilingual capacity in existing models without modification to model weights.
From Policy to Logic for Efficient and Interpretable Coverage Assessment
Jan 08, 2026Large Language Models (LLMs) have demonstrated strong capabilities in interpreting lengthy, complex legal and policy language. However, their reliability can be undermined by hallucinations and inconsistencies, particularly when analyzing subjective and nuanced documents. These challenges are especially critical in medical coverage policy review, where human experts must be able to rely on accurate information. In this paper, we present an approach designed to support human reviewers by making policy interpretation more efficient and interpretable. We introduce a methodology that pairs a coverage-aware retriever with symbolic rule-based reasoning to surface relevant policy language, organize it into explicit facts and rules, and generate auditable rationales. This hybrid system minimizes the number of LLM inferences required which reduces overall model cost. Notably, our approach achieves a 44% reduction in inference cost alongside a 4.5% improvement in F1 score, demonstrating both efficiency and effectiveness.
MTQ-Eval: Multilingual Text Quality Evaluation for Language Models
Nov 12, 2025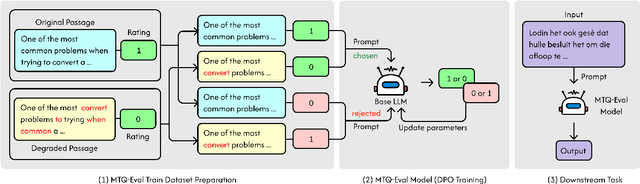



The use of large language models (LLMs) for evaluating outputs is becoming an increasingly effective and scalable approach. However, it remains uncertain whether this capability extends beyond task-specific evaluations to more general assessments of text quality, particularly in multilingual contexts. In this study, we introduce, MTQ-Eval, a novel framework for multilingual text quality evaluation that learns from examples of both high- and low-quality texts, adjusting its internal representations. To develop MTQ-Eval, we first automatically generate text quality preference data and then use it to train open-source base LLMs to align with ratings of high- and low-quality text. Our comprehensive evaluation across 115 languages demonstrates the improved performance of the proposed model. Upon further analysis, we find that this enhanced evaluation capability also leads to notable improvements in downstream tasks.
CAPO: Confidence Aware Preference Optimization Learning for Multilingual Preferences
Nov 10, 2025



Preference optimization is a critical post-training technique used to align large language models (LLMs) with human preferences, typically by fine-tuning on ranked response pairs. While methods like Direct Preference Optimization (DPO) have proven effective in English, they often fail to generalize robustly to multilingual settings. We propose a simple yet effective alternative, Confidence-Aware Preference Optimization (CAPO), which replaces DPO's fixed treatment of preference pairs with a dynamic loss scaling mechanism based on a relative reward. By modulating the learning signal according to the confidence in each preference pair, CAPO enhances robustness to noisy or low-margin comparisons, typically encountered in multilingual text. Empirically, CAPO outperforms existing preference optimization baselines by at least 16% in reward accuracy, and improves alignment by widening the gap between preferred and dispreferred responses across languages.
The Impact of Model Scaling on Seen and Unseen Language Performance
Jan 10, 2025
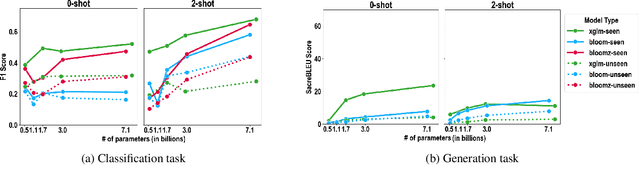
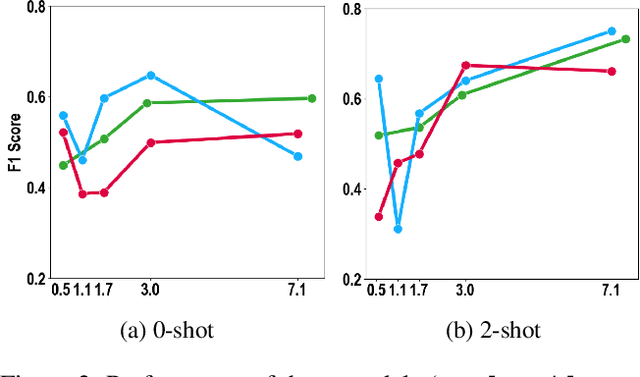
The rapid advancement of Large Language Models (LLMs), particularly those trained on multilingual corpora, has intensified the need for a deeper understanding of their performance across a diverse range of languages and model sizes. Our research addresses this critical need by studying the performance and scaling behavior of multilingual LLMs in text classification and machine translation tasks across 204 languages. We systematically examine both seen and unseen languages across three model families of varying sizes in zero-shot and few-shot settings. Our findings show significant differences in scaling behavior between zero-shot and two-shot scenarios, with striking disparities in performance between seen and unseen languages. Model scale has little effect on zero-shot performance, which remains mostly flat. However, in two-shot settings, larger models show clear linear improvements in multilingual text classification. For translation tasks, however, only the instruction-tuned model showed clear benefits from scaling. Our analysis also suggests that overall resource levels, not just the proportions of pretraining languages, are better predictors of model performance, shedding light on what drives multilingual LLM effectiveness.
Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models
Dec 17, 2024Multilingual language models (MLLMs) are crucial for handling text across various languages, yet they often show performance disparities due to differences in resource availability and linguistic characteristics. While the impact of pre-train data percentage and model size on performance is well-known, our study reveals additional critical factors that significantly influence MLLM effectiveness. Analyzing a wide range of features, including geographical, linguistic, and resource-related aspects, we focus on the SIB-200 dataset for classification and the Flores-200 dataset for machine translation, using regression models and SHAP values across 204 languages. Our findings identify token similarity and country similarity as pivotal factors, alongside pre-train data and model size, in enhancing model performance. Token similarity facilitates cross-lingual transfer, while country similarity highlights the importance of shared cultural and linguistic contexts. These insights offer valuable guidance for developing more equitable and effective multilingual language models, particularly for underrepresented languages.
Multilingual Evaluation of Long Context Retrieval and Reasoning
Sep 26, 2024Recent large language models (LLMs) demonstrate impressive capabilities in handling long contexts, some exhibiting near-perfect recall on synthetic retrieval tasks. However, these evaluations have mainly focused on English text and involved a single target sentence within lengthy contexts. Our work investigates how LLM performance generalizes to multilingual settings with multiple hidden target sentences. We comprehensively evaluate several long-context LLMs on retrieval and reasoning tasks across five languages: English, Vietnamese, Indonesian, Swahili, and Somali. These languages share the Latin script but belong to distinct language families and resource levels. Our analysis reveals a significant performance gap between languages. The best-performing models such as Gemini-1.5 and GPT-4o, achieve around 96% accuracy in English to around 36% in Somali with a single target sentence. However, this accuracy drops to 40% in English and 0% in Somali when dealing with three target sentences. Our findings highlight the challenges long-context LLMs face when processing longer contexts, an increase in the number of target sentences, or languages of lower resource levels.
Generating Continuations in Multilingual Idiomatic Contexts
Nov 04, 2023



The ability to process idiomatic or literal multiword expressions is a crucial aspect of understanding and generating any language. The task of generating contextually relevant continuations for narratives containing idiomatic (or literal) expressions can allow us to test the ability of generative language models (LMs) in understanding nuanced language containing non-compositional figurative text. We conduct a series of experiments using datasets in two distinct languages (English and Portuguese) under three different training settings (zero-shot, few-shot, and fine-tuned). Our results suggest that the models are only slightly better at generating continuations for literal contexts than idiomatic contexts, with exceedingly small margins. Furthermore, the models studied in this work perform equally well across both languages, indicating the robustness of generative models in performing this task.
Estimating Semantic Similarity between In-Domain and Out-of-Domain Samples
Jun 01, 2023



Prior work typically describes out-of-domain (OOD) or out-of-distribution (OODist) samples as those that originate from dataset(s) or source(s) different from the training set but for the same task. When compared to in-domain (ID) samples, the models have been known to usually perform poorer on OOD samples, although this observation is not consistent. Another thread of research has focused on OOD detection, albeit mostly using supervised approaches. In this work, we first consolidate and present a systematic analysis of multiple definitions of OOD and OODist as discussed in prior literature. Then, we analyze the performance of a model under ID and OOD/OODist settings in a principled way. Finally, we seek to identify an unsupervised method for reliably identifying OOD/OODist samples without using a trained model. The results of our extensive evaluation using 12 datasets from 4 different tasks suggest the promising potential of unsupervised metrics in this task.
Classifying YouTube Comments Based on Sentiment and Type of Sentence
Oct 31, 2021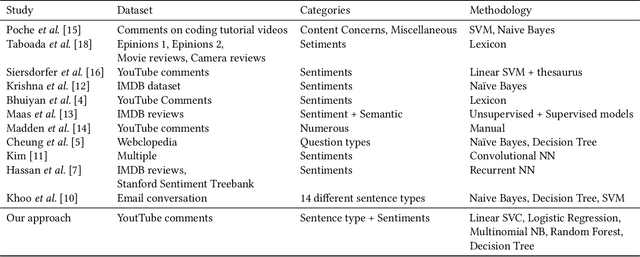
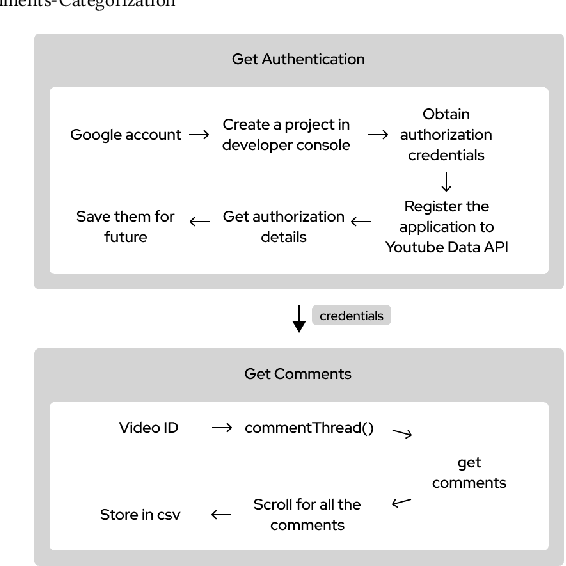


As a YouTube channel grows, each video can potentially collect enormous amounts of comments that provide direct feedback from the viewers. These comments are a major means of understanding viewer expectations and improving channel engagement. However, the comments only represent a general collection of user opinions about the channel and the content. Many comments are poorly constructed, trivial, and have improper spellings and grammatical errors. As a result, it is a tedious job to identify the comments that best interest the content creators. In this paper, we extract and classify the raw comments into different categories based on both sentiment and sentence types that will help YouTubers find relevant comments for growing their viewership. Existing studies have focused either on sentiment analysis (positive and negative) or classification of sub-types within the same sentence types (e.g., types of questions) on a text corpus. These have limited application on non-traditional text corpus like YouTube comments. We address this challenge of text extraction and classification from YouTube comments using well-known statistical measures and machine learning models. We evaluate each combination of statistical measure and the machine learning model using cross validation and $F_1$ scores. The results show that our approach that incorporates conventional methods performs well on the classification task, validating its potential in assisting content creators increase viewer engagement on their channel.