 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemBBC: Exploring the Multilingual Maze
Paper and Code
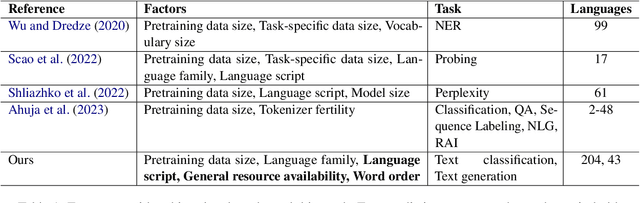


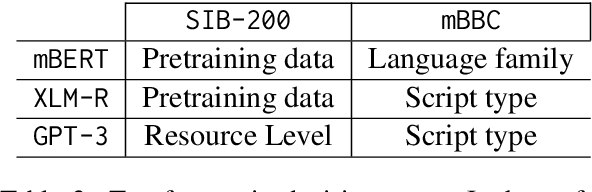
Multilingual language models have gained significant attention in recent years, enabling the development of applications that cater to diverse linguistic contexts. In this paper, we present a comprehensive evaluation of three prominent multilingual language models: mBERT, XLM-R, and GPT-3. Using the self-supervised task of next token prediction, we assess their performance across a diverse set of languages, with a focus on understanding the impact of resource availability, word order, language family, and script type on model accuracy. Our findings reveal that resource availability plays a crucial role in model performance, with higher resource levels leading to improved accuracy. We also identify the complex relationship between resource availability, language families, and script types, highlighting the need for further investigation into language-specific characteristics and structural variations. Additionally, our statistical inference analysis identifies significant features contributing to model performance, providing insights for model selection and deployment. Our study contributes to a deeper understanding of multilingual language models and informs future research and development to enhance their performance and generalizability across languages and linguistic contexts.