 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleverDistiller: Simple and Spatially Consistent Cross-modal Distillation
Mar 12, 2025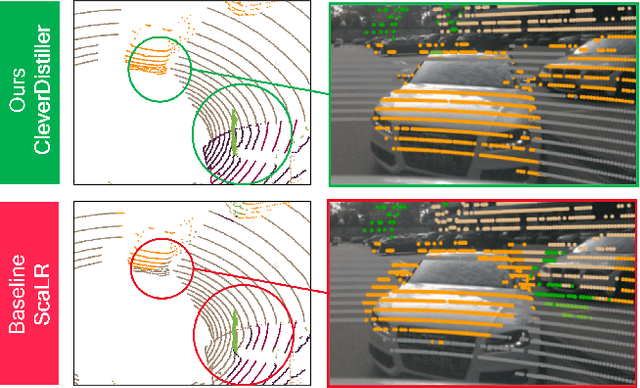
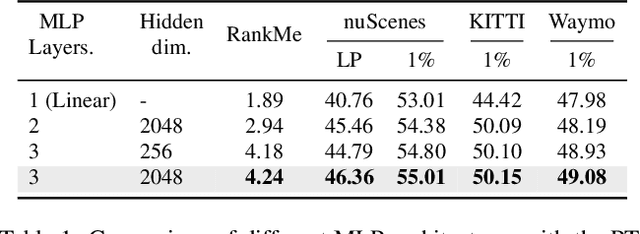
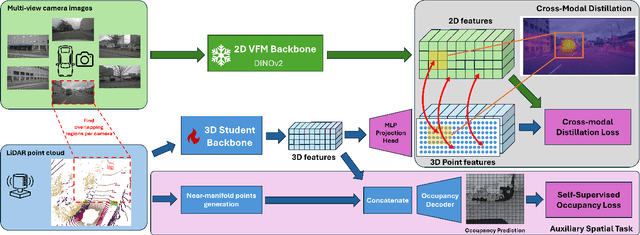
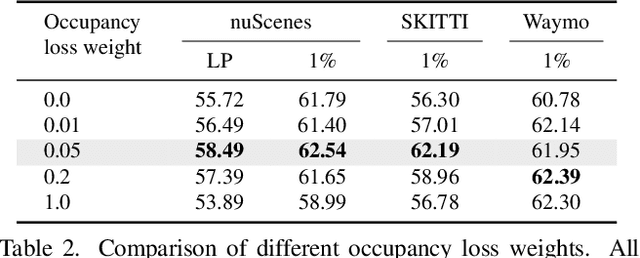
Vision foundation models (VFMs) such as DINO have led to a paradigm shift in 2D camera-based perception towards extracting generalized features to support many downstream tasks. Recent works introduce self-supervised cross-modal knowledge distillation (KD) as a way to transfer these powerful generalization capabilities into 3D LiDAR-based models. However, they either rely on highly complex distillation losses, pseudo-semantic maps, or limit KD to features useful for semantic segmentation only. In this work, we propose CleverDistiller, a self-supervised, cross-modal 2D-to-3D KD framework introducing a set of simple yet effective design choices: Unlike contrastive approaches relying on complex loss design choices, our method employs a direct feature similarity loss in combination with a multi layer perceptron (MLP) projection head to allow the 3D network to learn complex semantic dependencies throughout the projection. Crucially, our approach does not depend on pseudo-semantic maps, allowing for direct knowledge transfer from a VFM without explicit semantic supervision. Additionally, we introduce the auxiliary self-supervised spatial task of occupancy prediction to enhance the semantic knowledge, obtained from a VFM through KD, with 3D spatial reasoning capabilities. Experiments on standard autonomous driving benchmarks for 2D-to-3D KD demonstrate that CleverDistiller achieves state-of-the-art performance in both semantic segmentation and 3D object detection (3DOD) by up to 10% mIoU, especially when fine tuning on really low data amounts, showing the effectiveness of our simple yet powerful KD strategy
S3PT: Scene Semantics and Structure Guided Clustering to Boost Self-Supervised Pre-Training for Autonomous Driving
Oct 30, 2024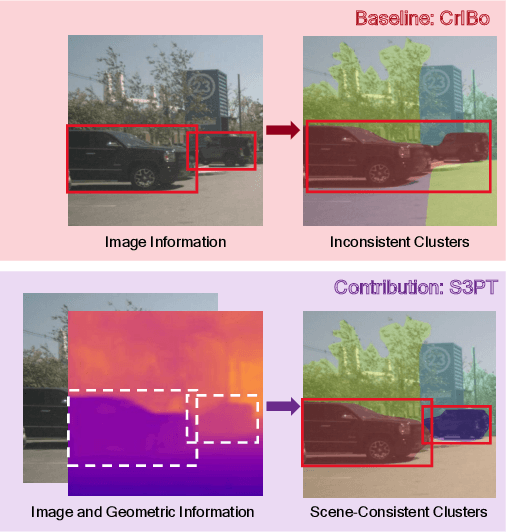
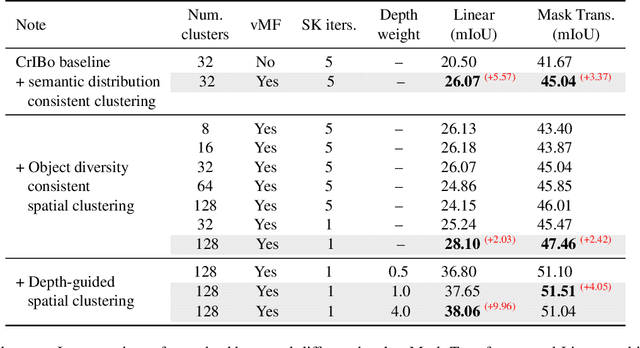
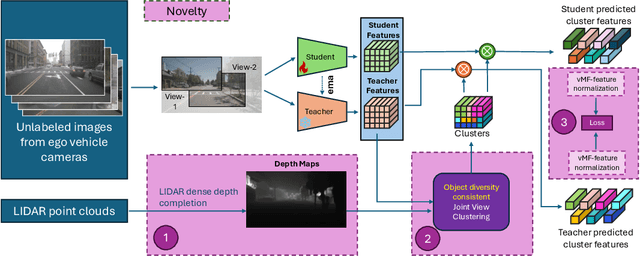
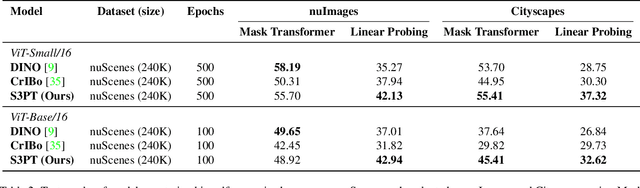
Recent self-supervised clustering-based pre-training techniques like DINO and Cribo have shown impressive results for downstream detection and segmentation tasks. However, real-world applications such as autonomous driving face challenges with imbalanced object class and size distributions and complex scene geometries. In this paper, we propose S3PT a novel scene semantics and structure guided clustering to provide more scene-consistent objectives for self-supervised training. Specifically, our contributions are threefold: First, we incorporate semantic distribution consistent clustering to encourage better representation of rare classes such as motorcycles or animals. Second, we introduce object diversity consistent spatial clustering, to handle imbalanced and diverse object sizes, ranging from large background areas to small objects such as pedestrians and traffic signs. Third, we propose a depth-guided spatial clustering to regularize learning based on geometric information of the scene, thus further refining region separation on the feature level. Our learned representations significantly improve performance in downstream semantic segmentation and 3D object detection tasks on the nuScenes, nuImages, and Cityscapes datasets and show promising domain translation properties.