 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Safety in Autonomous Driving: Requirements, Risks, and Assurance
Nov 11, 2025Dataset integrity is fundamental to the safety and reliability of AI systems, especially in autonomous driving. This paper presents a structured framework for developing safe datasets aligned with ISO/PAS 8800 guidelines. Using AI-based perception systems as the primary use case, it introduces the AI Data Flywheel and the dataset lifecycle, covering data collection, annotation, curation, and maintenance. The framework incorporates rigorous safety analyses to identify hazards and mitigate risks caused by dataset insufficiencies. It also defines processes for establishing dataset safety requirements and proposes verification and validation strategies to ensure compliance with safety standards. In addition to outlining best practices, the paper reviews recent research and emerging trends in dataset safety and autonomous vehicle development, providing insights into current challenges and future directions. By integrating these perspectives, the paper aims to advance robust, safety-assured AI systems for autonomous driving applications.
CleverDistiller: Simple and Spatially Consistent Cross-modal Distillation
Mar 12, 2025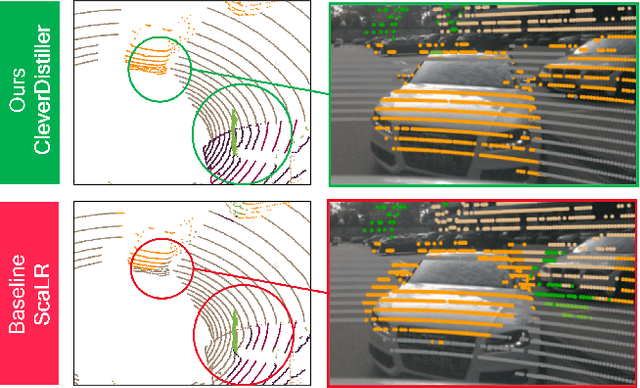
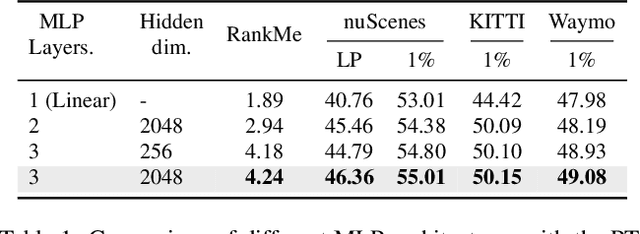
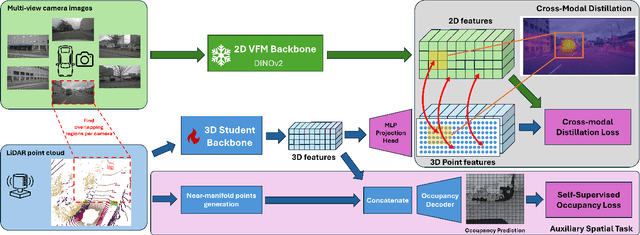
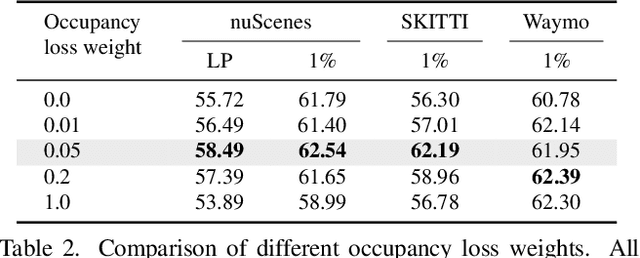
Vision foundation models (VFMs) such as DINO have led to a paradigm shift in 2D camera-based perception towards extracting generalized features to support many downstream tasks. Recent works introduce self-supervised cross-modal knowledge distillation (KD) as a way to transfer these powerful generalization capabilities into 3D LiDAR-based models. However, they either rely on highly complex distillation losses, pseudo-semantic maps, or limit KD to features useful for semantic segmentation only. In this work, we propose CleverDistiller, a self-supervised, cross-modal 2D-to-3D KD framework introducing a set of simple yet effective design choices: Unlike contrastive approaches relying on complex loss design choices, our method employs a direct feature similarity loss in combination with a multi layer perceptron (MLP) projection head to allow the 3D network to learn complex semantic dependencies throughout the projection. Crucially, our approach does not depend on pseudo-semantic maps, allowing for direct knowledge transfer from a VFM without explicit semantic supervision. Additionally, we introduce the auxiliary self-supervised spatial task of occupancy prediction to enhance the semantic knowledge, obtained from a VFM through KD, with 3D spatial reasoning capabilities. Experiments on standard autonomous driving benchmarks for 2D-to-3D KD demonstrate that CleverDistiller achieves state-of-the-art performance in both semantic segmentation and 3D object detection (3DOD) by up to 10% mIoU, especially when fine tuning on really low data amounts, showing the effectiveness of our simple yet powerful KD strategy
S3PT: Scene Semantics and Structure Guided Clustering to Boost Self-Supervised Pre-Training for Autonomous Driving
Oct 30, 2024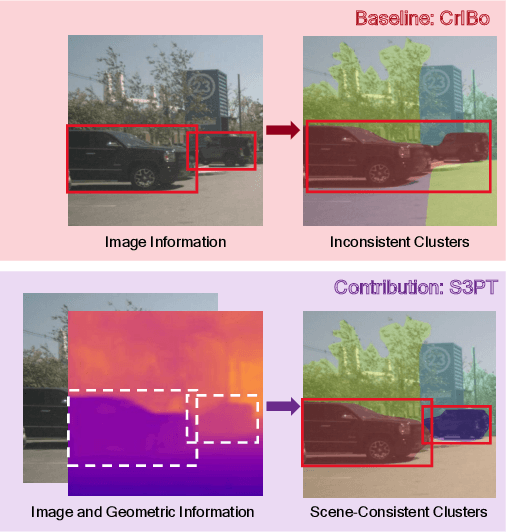
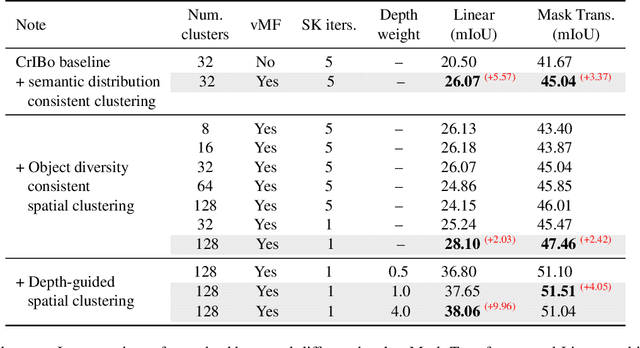
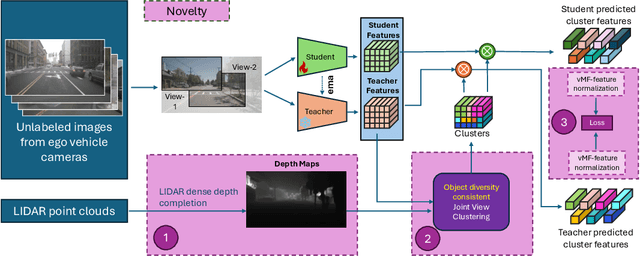
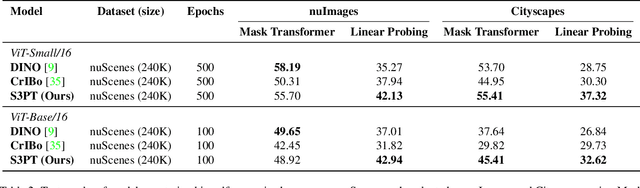
Recent self-supervised clustering-based pre-training techniques like DINO and Cribo have shown impressive results for downstream detection and segmentation tasks. However, real-world applications such as autonomous driving face challenges with imbalanced object class and size distributions and complex scene geometries. In this paper, we propose S3PT a novel scene semantics and structure guided clustering to provide more scene-consistent objectives for self-supervised training. Specifically, our contributions are threefold: First, we incorporate semantic distribution consistent clustering to encourage better representation of rare classes such as motorcycles or animals. Second, we introduce object diversity consistent spatial clustering, to handle imbalanced and diverse object sizes, ranging from large background areas to small objects such as pedestrians and traffic signs. Third, we propose a depth-guided spatial clustering to regularize learning based on geometric information of the scene, thus further refining region separation on the feature level. Our learned representations significantly improve performance in downstream semantic segmentation and 3D object detection tasks on the nuScenes, nuImages, and Cityscapes datasets and show promising domain translation properties.
LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
May 29, 2024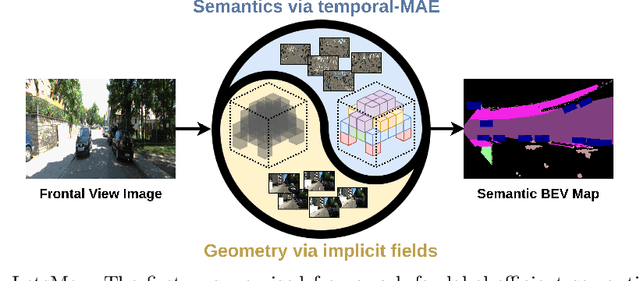
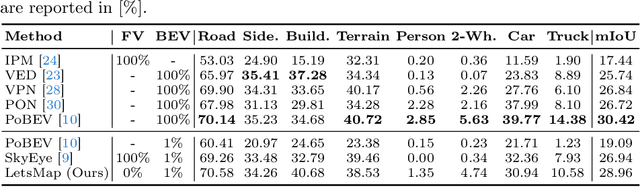
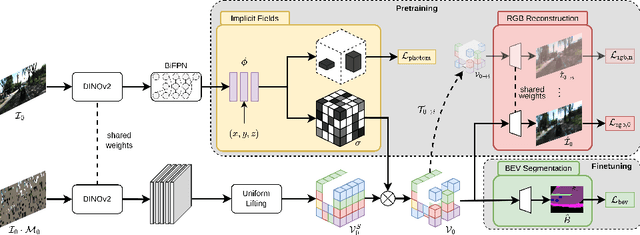
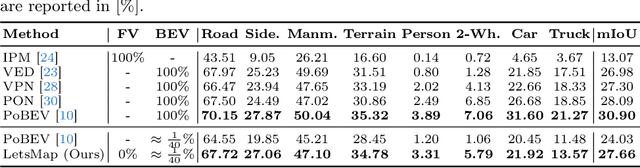
Semantic Bird's Eye View (BEV) maps offer a rich representation with strong occlusion reasoning for various decision making tasks in autonomous driving. However, most BEV mapping approaches employ a fully supervised learning paradigm that relies on large amounts of human-annotated BEV ground truth data. In this work, we address this limitation by proposing the first unsupervised representation learning approach to generate semantic BEV maps from a monocular frontal view (FV) image in a label-efficient manner. Our approach pretrains the network to independently reason about scene geometry and scene semantics using two disjoint neural pathways in an unsupervised manner and then finetunes it for the task of semantic BEV mapping using only a small fraction of labels in the BEV. We achieve label-free pretraining by exploiting spatial and temporal consistency of FV images to learn scene geometry while relying on a novel temporal masked autoencoder formulation to encode the scene representation. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach performs on par with the existing state-of-the-art approaches while using only 1% of BEV labels and no additional labeled data.
FisheyeDetNet: 360° Surround view Fisheye Camera based Object Detection System for Autonomous Driving
Apr 27, 2024



Object detection is a mature problem in autonomous driving with pedestrian detection being one of the first deployed algorithms. It has been comprehensively studied in the literature. However, object detection is relatively less explored for fisheye cameras used for surround-view near field sensing. The standard bounding box representation fails in fisheye cameras due to heavy radial distortion, particularly in the periphery. To mitigate this, we explore extending the standard object detection output representation of bounding box. We design rotated bounding boxes, ellipse, generic polygon as polar arc/angle representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model FisheyeDetNet with polygon outperforms others and achieves a mAP score of 49.5 % on Valeo fisheye surround-view dataset for automated driving applications. This dataset has 60K images captured from 4 surround-view cameras across Europe, North America and Asia. To the best of our knowledge, this is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios.
DaF-BEVSeg: Distortion-aware Fisheye Camera based Bird's Eye View Segmentation with Occlusion Reasoning
Apr 09, 2024



Semantic segmentation is an effective way to perform scene understanding. Recently, segmentation in 3D Bird's Eye View (BEV) space has become popular as its directly used by drive policy. However, there is limited work on BEV segmentation for surround-view fisheye cameras, commonly used in commercial vehicles. As this task has no real-world public dataset and existing synthetic datasets do not handle amodal regions due to occlusion, we create a synthetic dataset using the Cognata simulator comprising diverse road types, weather, and lighting conditions. We generalize the BEV segmentation to work with any camera model; this is useful for mixing diverse cameras. We implement a baseline by applying cylindrical rectification on the fisheye images and using a standard LSS-based BEV segmentation model. We demonstrate that we can achieve better performance without undistortion, which has the adverse effects of increased runtime due to pre-processing, reduced field-of-view, and resampling artifacts. Further, we introduce a distortion-aware learnable BEV pooling strategy that is more effective for the fisheye cameras. We extend the model with an occlusion reasoning module, which is critical for estimating in BEV space. Qualitative performance of DaF-BEVSeg is showcased in the video at https://streamable.com/ge4v51.
Impact of Video Compression Artifacts on Fisheye Camera Visual Perception Tasks
Mar 25, 2024



Autonomous driving systems require extensive data collection schemes to cover the diverse scenarios needed for building a robust and safe system. The data volumes are in the order of Exabytes and have to be stored for a long period of time (i.e., more than 10 years of the vehicle's life cycle). Lossless compression doesn't provide sufficient compression ratios, hence, lossy video compression has been explored. It is essential to prove that lossy video compression artifacts do not impact the performance of the perception algorithms. However, there is limited work in this area to provide a solid conclusion. In particular, there is no such work for fisheye cameras, which have high radial distortion and where compression may have higher artifacts. Fisheye cameras are commonly used in automotive systems for 3D object detection task. In this work, we provide the first analysis of the impact of standard video compression codecs on wide FOV fisheye camera images. We demonstrate that the achievable compression with negligible impact depends on the dataset and temporal prediction of the video codec. We propose a radial distortion-aware zonal metric to evaluate the performance of artifacts in fisheye images. In addition, we present a novel method for estimating affine mode parameters of the latest VVC codec, and suggest some areas for improvement in video codecs for the application to fisheye imagery.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024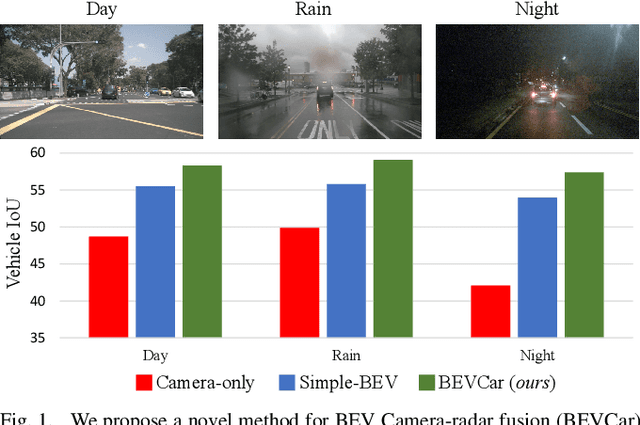
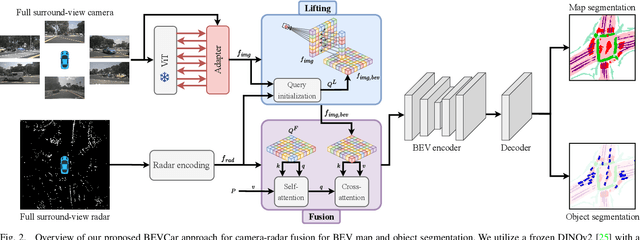
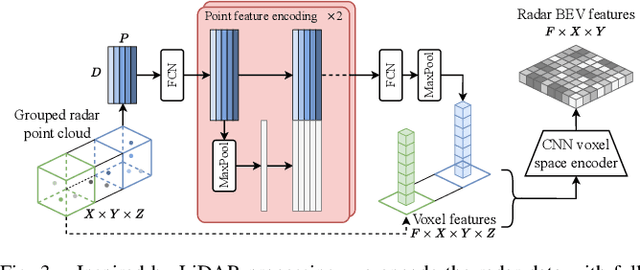
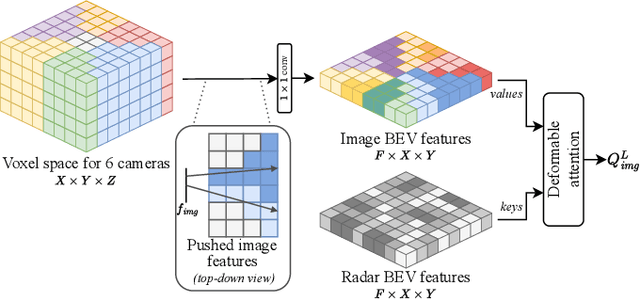
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
Neural Rendering based Urban Scene Reconstruction for Autonomous Driving
Feb 09, 2024Dense 3D reconstruction has many applications in automated driving including automated annotation validation, multimodal data augmentation, providing ground truth annotations for systems lacking LiDAR, as well as enhancing auto-labeling accuracy. LiDAR provides highly accurate but sparse depth, whereas camera images enable estimation of dense depth but noisy particularly at long ranges. In this paper, we harness the strengths of both sensors and propose a multimodal 3D scene reconstruction using a framework combining neural implicit surfaces and radiance fields. In particular, our method estimates dense and accurate 3D structures and creates an implicit map representation based on signed distance fields, which can be further rendered into RGB images, and depth maps. A mesh can be extracted from the learned signed distance field and culled based on occlusion. Dynamic objects are efficiently filtered on the fly during sampling using 3D object detection models. We demonstrate qualitative and quantitative results on challenging automotive scenes.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.