 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Reservoir Computing for Chaotic Time Series Prediction
Jan 26, 2025Reservoir Computing was shown in recent years to be useful as efficient to learn networks in the field of time series tasks. Their randomized initialization, a computational benefit, results in drawbacks in theoretical analysis of large random graphs, because of which deterministic variations are an still open field of research. Building upon Next-Gen Reservoir Computing and the Temporal Convolution Derived Reservoir Computing, we propose a deterministic alternative to the higher-dimensional mapping therein, TCRC-LM and TCRC-CM, utilizing the parametrized but deterministic Logistic mapping and Chebyshev maps. To further enhance the predictive capabilities in the task of time series forecasting, we propose the novel utilization of the Lobachevsky function as non-linear activation function. As a result, we observe a new, fully deterministic network being able to outperform TCRCs and classical Reservoir Computing in the form of the prominent Echo State Networks by up to $99.99\%$ for the non-chaotic time series and $87.13\%$ for the chaotic ones.
Bootstrapping Corner Cases: High-Resolution Inpainting for Safety Critical Detect and Avoid for Automated Flying
Jan 14, 2025Modern machine learning techniques have shown tremendous potential, especially for object detection on camera images. For this reason, they are also used to enable safety-critical automated processes such as autonomous drone flights. We present a study on object detection for Detect and Avoid, a safety critical function for drones that detects air traffic during automated flights for safety reasons. An ill-posed problem is the generation of good and especially large data sets, since detection itself is the corner case. Most models suffer from limited ground truth in raw data, \eg recorded air traffic or frontal flight with a small aircraft. It often leads to poor and critical detection rates. We overcome this problem by using inpainting methods to bootstrap the dataset such that it explicitly contains the corner cases of the raw data. We provide an overview of inpainting methods and generative models and present an example pipeline given a small annotated dataset. We validate our method by generating a high-resolution dataset, which we make publicly available and present it to an independent object detector that was fully trained on real data.
Slim multi-scale convolutional autoencoder-based reduced-order models for interpretable features of a complex dynamical system
Jan 06, 2025

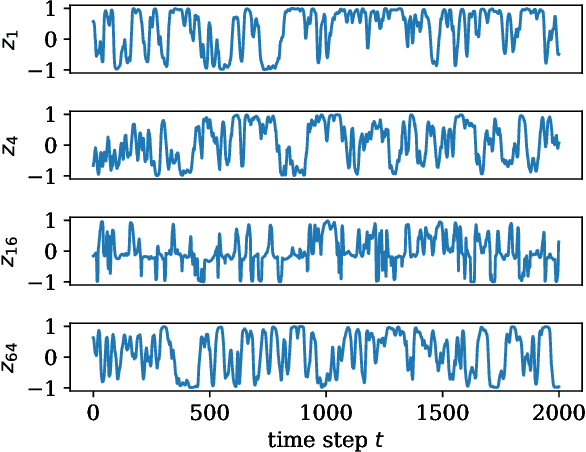

In recent years, data-driven deep learning models have gained significant interest in the analysis of turbulent dynamical systems. Within the context of reduced-order models (ROMs), convolutional autoencoders (CAEs) pose a universally applicable alternative to conventional approaches. They can learn nonlinear transformations directly from data, without prior knowledge of the system. However, the features generated by such models lack interpretability. Thus, the resulting model is a black-box which effectively reduces the complexity of the system, but does not provide insights into the meaning of the latent features. To address this critical issue, we introduce a novel interpretable CAE approach for high-dimensional fluid flow data that maintains the reconstruction quality of conventional CAEs and allows for feature interpretation. Our method can be easily integrated into any existing CAE architecture with minor modifications of the training process. We compare our approach to Proper Orthogonal Decomposition (POD) and two existing methods for interpretable CAEs. We apply all methods to three different experimental turbulent Rayleigh-B\'enard convection datasets with varying complexity. Our results show that the proposed method is lightweight, easy to train, and achieves relative reconstruction performance improvements of up to 6.4% over POD for 64 modes. The relative improvement increases to up to 229.8% as the number of modes decreases. Additionally, our method delivers interpretable features similar to those of POD and is significantly less resource-intensive than existing CAE approaches, using less than 2% of the parameters. These approaches either trade interpretability for reconstruction performance or only provide interpretability to a limited extend.
Privacy Preserving Federated Learning with Convolutional Variational Bottlenecks
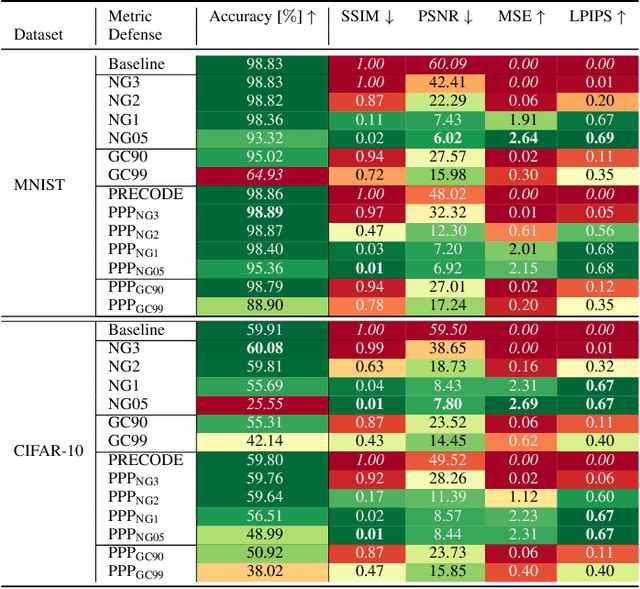
Sep 08, 2023Gradient inversion attacks are an ubiquitous threat in federated learning as they exploit gradient leakage to reconstruct supposedly private training data. Recent work has proposed to prevent gradient leakage without loss of model utility by incorporating a PRivacy EnhanCing mODulE (PRECODE) based on variational modeling. Without further analysis, it was shown that PRECODE successfully protects against gradient inversion attacks. In this paper, we make multiple contributions. First, we investigate the effect of PRECODE on gradient inversion attacks to reveal its underlying working principle. We show that variational modeling introduces stochasticity into the gradients of PRECODE and the subsequent layers in a neural network. The stochastic gradients of these layers prevent iterative gradient inversion attacks from converging. Second, we formulate an attack that disables the privacy preserving effect of PRECODE by purposefully omitting stochastic gradients during attack optimization. To preserve the privacy preserving effect of PRECODE, our analysis reveals that variational modeling must be placed early in the network. However, early placement of PRECODE is typically not feasible due to reduced model utility and the exploding number of additional model parameters. Therefore, as a third contribution, we propose a novel privacy module -- the Convolutional Variational Bottleneck (CVB) -- that can be placed early in a neural network without suffering from these drawbacks. We conduct an extensive empirical study on three seminal model architectures and six image classification datasets. We find that all architectures are susceptible to gradient leakage attacks, which can be prevented by our proposed CVB. Compared to PRECODE, we show that our novel privacy module requires fewer trainable parameters, and thus computational and communication costs, to effectively preserve privacy.
LiDAR-BEVMTN: Real-Time LiDAR Bird's-Eye View Multi-Task Perception Network for Autonomous Driving
Jul 17, 2023



LiDAR is crucial for robust 3D scene perception in autonomous driving. LiDAR perception has the largest body of literature after camera perception. However, multi-task learning across tasks like detection, segmentation, and motion estimation using LiDAR remains relatively unexplored, especially on automotive-grade embedded platforms. We present a real-time multi-task convolutional neural network for LiDAR-based object detection, semantics, and motion segmentation. The unified architecture comprises a shared encoder and task-specific decoders, enabling joint representation learning. We propose a novel Semantic Weighting and Guidance (SWAG) module to transfer semantic features for improved object detection selectively. Our heterogeneous training scheme combines diverse datasets and exploits complementary cues between tasks. The work provides the first embedded implementation unifying these key perception tasks from LiDAR point clouds achieving 3ms latency on the embedded NVIDIA Xavier platform. We achieve state-of-the-art results for two tasks, semantic and motion segmentation, and close to state-of-the-art performance for 3D object detection. By maximizing hardware efficiency and leveraging multi-task synergies, our method delivers an accurate and efficient solution tailored for real-world automated driving deployment. Qualitative results can be seen at https://youtu.be/H-hWRzv2lIY.
Flipped Classroom: Effective Teaching for Time Series Forecasting
Oct 17, 2022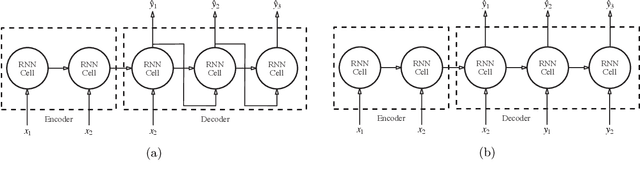
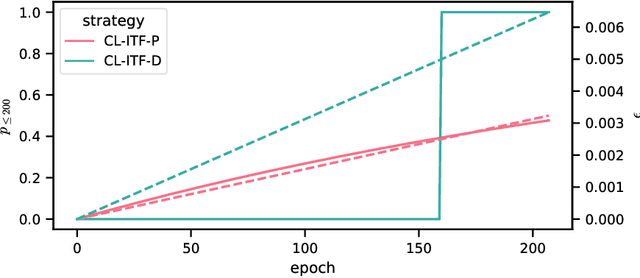
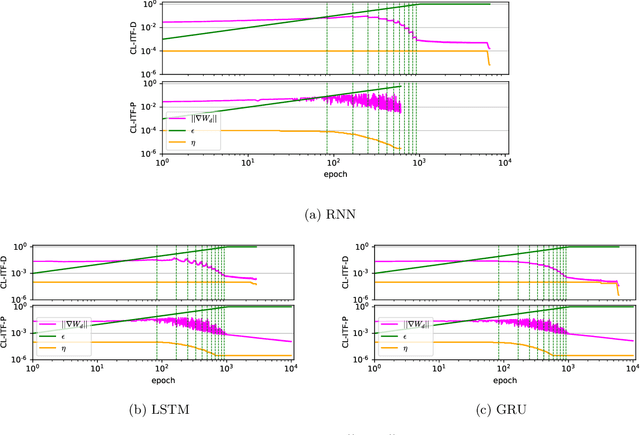
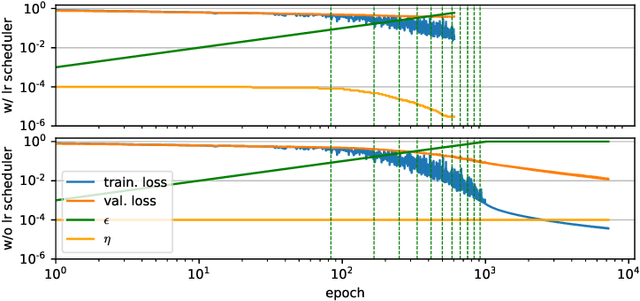
Sequence-to-sequence models based on LSTM and GRU are a most popular choice for forecasting time series data reaching state-of-the-art performance. Training such models can be delicate though. The two most common training strategies within this context are teacher forcing (TF) and free running (FR). TF can be used to help the model to converge faster but may provoke an exposure bias issue due to a discrepancy between training and inference phase. FR helps to avoid this but does not necessarily lead to better results, since it tends to make the training slow and unstable instead. Scheduled sampling was the first approach tackling these issues by picking the best from both worlds and combining it into a curriculum learning (CL) strategy. Although scheduled sampling seems to be a convincing alternative to FR and TF, we found that, even if parametrized carefully, scheduled sampling may lead to premature termination of the training when applied for time series forecasting. To mitigate the problems of the above approaches we formalize CL strategies along the training as well as the training iteration scale. We propose several new curricula, and systematically evaluate their performance in two experimental sets. For our experiments, we utilize six datasets generated from prominent chaotic systems. We found that the newly proposed increasing training scale curricula with a probabilistic iteration scale curriculum consistently outperforms previous training strategies yielding an NRMSE improvement of up to 81% over FR or TF training. For some datasets we additionally observe a reduced number of training iterations. We observed that all models trained with the new curricula yield higher prediction stability allowing for longer prediction horizons.
Generalizability of Code Clone Detection on CodeBERT
Sep 01, 2022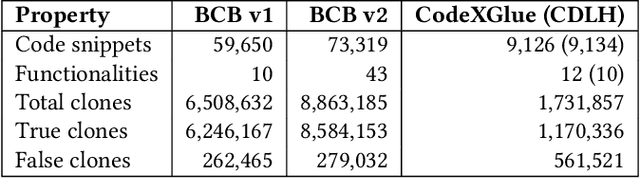
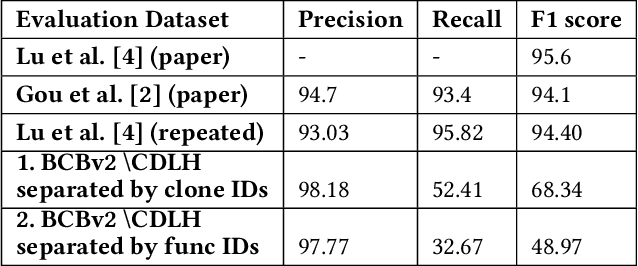
Transformer networks such as CodeBERT already achieve outstanding results for code clone detection in benchmark datasets, so one could assume that this task has already been solved. However, code clone detection is not a trivial task. Semantic code clones, in particular, are challenging to detect. We show that the generalizability of CodeBERT decreases by evaluating two different subsets of Java code clones from BigCloneBench. We observe a significant drop in F1 score when we evaluate different code snippets and functionality IDs than those used for model building.
Dropout is NOT All You Need to Prevent Gradient Leakage
Aug 12, 2022



Gradient inversion attacks on federated learning systems reconstruct client training data from exchanged gradient information. To defend against such attacks, a variety of defense mechanisms were proposed. However, they usually lead to an unacceptable trade-off between privacy and model utility. Recent observations suggest that dropout could mitigate gradient leakage and improve model utility if added to neural networks. Unfortunately, this phenomenon has not been systematically researched yet. In this work, we thoroughly analyze the effect of dropout on iterative gradient inversion attacks. We find that state of the art attacks are not able to reconstruct the client data due to the stochasticity induced by dropout during model training. Nonetheless, we argue that dropout does not offer reliable protection if the dropout induced stochasticity is adequately modeled during attack optimization. Consequently, we propose a novel Dropout Inversion Attack (DIA) that jointly optimizes for client data and dropout masks to approximate the stochastic client model. We conduct an extensive systematic evaluation of our attack on four seminal model architectures and three image classification datasets of increasing complexity. We find that our proposed attack bypasses the protection seemingly induced by dropout and reconstructs client data with high fidelity. Our work demonstrates that privacy inducing changes to model architectures alone cannot be assumed to reliably protect from gradient leakage and therefore should be combined with complementary defense mechanisms.
Combining Variational Modeling with Partial Gradient Perturbation to Prevent Deep Gradient Leakage
Aug 09, 2022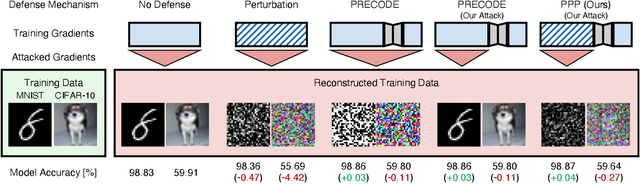
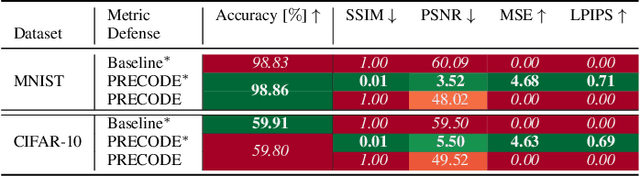

Exploiting gradient leakage to reconstruct supposedly private training data, gradient inversion attacks are an ubiquitous threat in collaborative learning of neural networks. To prevent gradient leakage without suffering from severe loss in model performance, recent work proposed a PRivacy EnhanCing mODulE (PRECODE) based on variational modeling as extension for arbitrary model architectures. In this work, we investigate the effect of PRECODE on gradient inversion attacks to reveal its underlying working principle. We show that variational modeling induces stochasticity on PRECODE's and its subsequent layers' gradients that prevents gradient attacks from convergence. By purposefully omitting those stochastic gradients during attack optimization, we formulate an attack that can disable PRECODE's privacy preserving effects. To ensure privacy preservation against such targeted attacks, we propose PRECODE with Partial Perturbation (PPP), as strategic combination of variational modeling and partial gradient perturbation. We conduct an extensive empirical study on four seminal model architectures and two image classification datasets. We find all architectures to be prone to gradient leakage, which can be prevented by PPP. In result, we show that our approach requires less gradient perturbation to effectively preserve privacy without harming model performance.
Direct data-driven forecast of local turbulent heat flux in Rayleigh-Bénard convection
Feb 26, 2022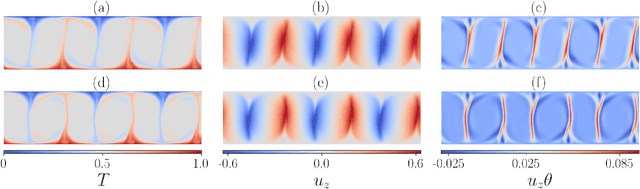
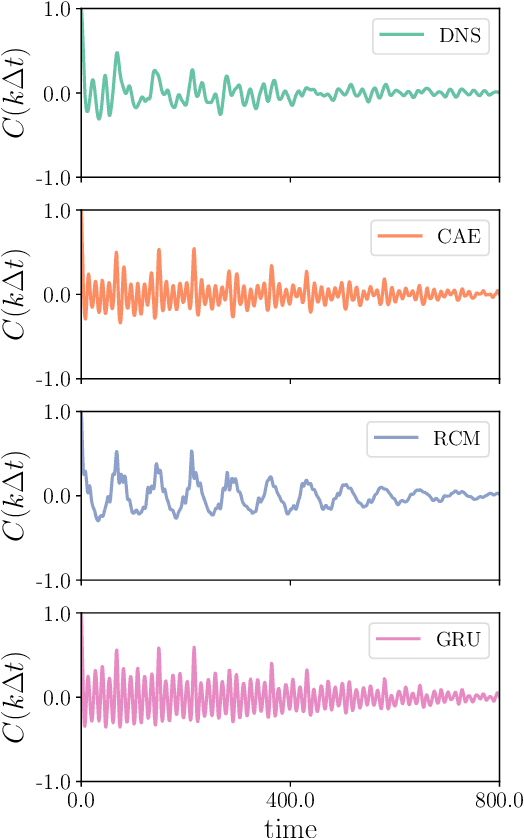
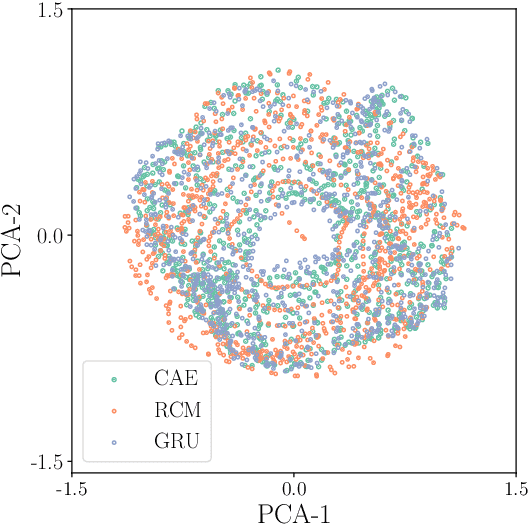
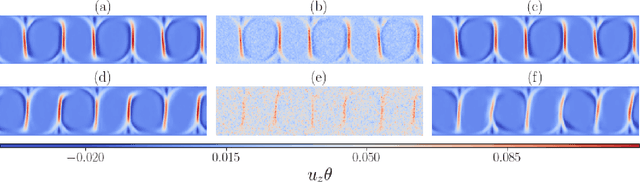
A combined convolutional autoencoder-recurrent neural network machine learning model is presented to analyse and forecast the dynamics and low-order statistics of the local convective heat flux field in a two-dimensional turbulent Rayleigh-B\'{e}nard convection flow at Prandtl number ${\rm Pr}=7$ and Rayleigh number ${\rm Ra}=10^7$. Two recurrent neural networks are applied for the temporal advancement of flow data in the reduced latent data space, a reservoir computing model in the form of an echo state network and a recurrent gated unit. Thereby, the present work exploits the modular combination of three different machine learning algorithms to build a fully data-driven and reduced model for the dynamics of the turbulent heat transfer in a complex thermally driven flow. The convolutional autoencoder with 12 hidden layers is able to reduce the dimensionality of the turbulence data to about 0.2 \% of their original size. Our results indicate a fairly good accuracy in the first- and second-order statistics of the convective heat flux. The algorithm is also able to reproduce the intermittent plume-mixing dynamics at the upper edges of the thermal boundary layers with some deviations. The same holds for the probability density function of the local convective heat flux with differences in the far tails. Furthermore, we demonstrate the noise resilience of the framework which suggests the present model might be applicable as a reduced dynamical model that delivers transport fluxes and their variations to the coarse grid cells of larger-scale computational models, such as global circulation models for the atmosphere and ocean.