 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizability of Code Clone Detection on CodeBERT
Sep 01, 2022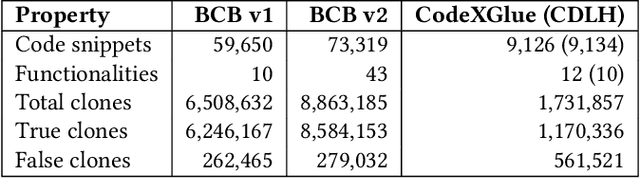
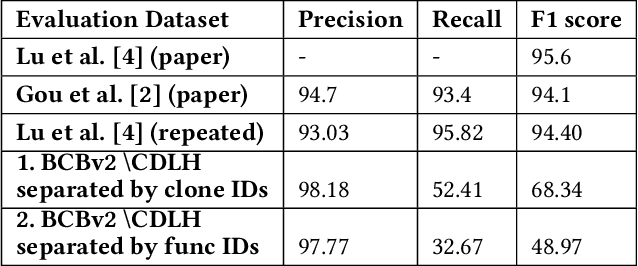
Transformer networks such as CodeBERT already achieve outstanding results for code clone detection in benchmark datasets, so one could assume that this task has already been solved. However, code clone detection is not a trivial task. Semantic code clones, in particular, are challenging to detect. We show that the generalizability of CodeBERT decreases by evaluating two different subsets of Java code clones from BigCloneBench. We observe a significant drop in F1 score when we evaluate different code snippets and functionality IDs than those used for model building.
Cross-Domain Evaluation of a Deep Learning-Based Type Inference System
Aug 19, 2022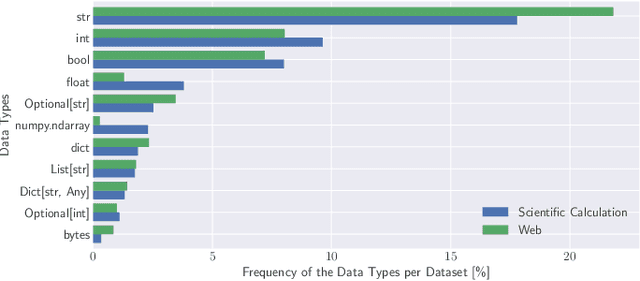
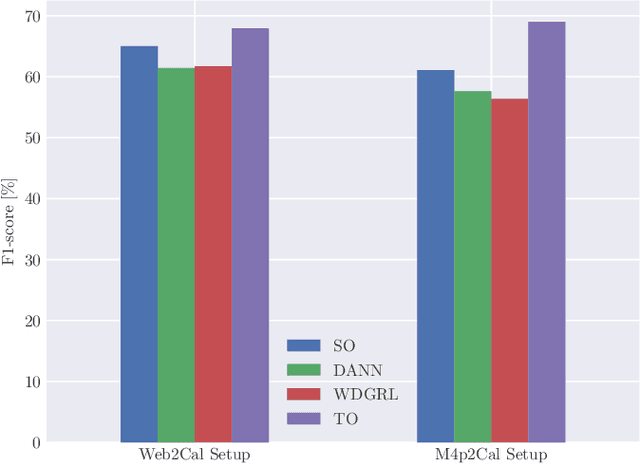
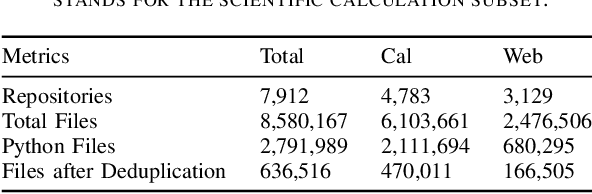

Optional type annotations allow for enriching dynamic programming languages with static typing features like better Integrated Development Environment (IDE) support, more precise program analysis, and early detection and prevention of type-related runtime errors. Machine learning-based type inference promises interesting results for automating this task. However, the practical usage of such systems depends on their ability to generalize across different domains, as they are often applied outside their training domain. In this work, we investigate the generalization ability of Type4Py as a representative for state-of-the-art deep learning-based type inference systems, by conducting extensive cross-domain experiments. Thereby, we address the following problems: dataset shifts, out-of-vocabulary words, unknown classes, and rare classes. To perform such experiments, we use the datasets ManyTypes4Py and CrossDomainTypes4Py. The latter we introduce in this paper. Our dataset has over 1,000,000 type annotations and enables cross-domain evaluation of type inference systems in different domains of software projects using data from the two domains web development and scientific calculation. Through our experiments, we detect shifts in the dataset and that it has a long-tailed distribution with many rare and unknown data types which decreases the performance of the deep learning-based type inference system drastically. In this context, we test unsupervised domain adaptation methods and fine-tuning to overcome the issues. Moreover, we investigate the impact of out-of-vocabulary words.
Self-Supervised Learning from Semantically Imprecise Data
Apr 22, 2021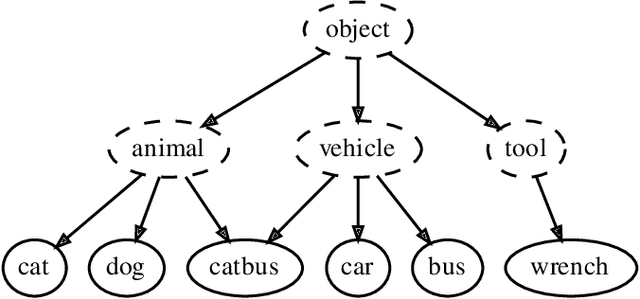
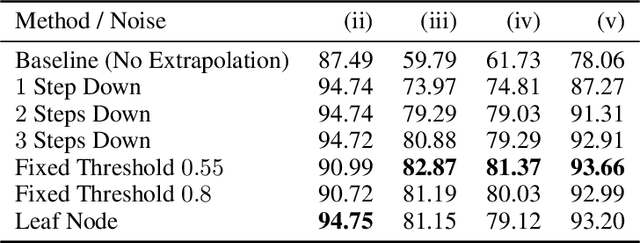

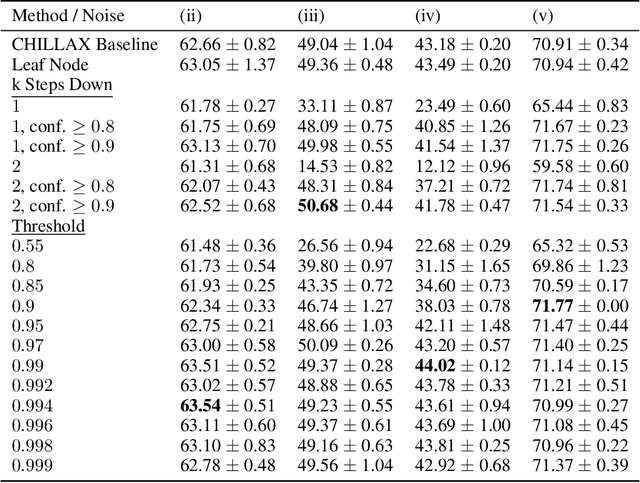
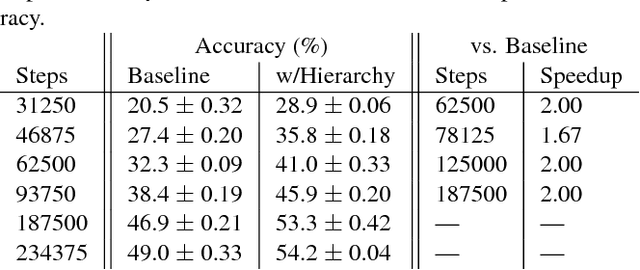
Learning from imprecise labels such as "animal" or "bird", but making precise predictions like "snow bunting" at test time is an important capability when expertly labeled training data is scarce. Contributions by volunteers or results of web crawling lack precision in this manner, but are still valuable. And crucially, these weakly labeled examples are available in larger quantities for lower cost than high-quality bespoke training data. CHILLAX, a recently proposed method to tackle this task, leverages a hierarchical classifier to learn from imprecise labels. However, it has two major limitations. First, it is not capable of learning from effectively unlabeled examples at the root of the hierarchy, e.g. "object". Second, an extrapolation of annotations to precise labels is only performed at test time, where confident extrapolations could be already used as training data. In this work, we extend CHILLAX with a self-supervised scheme using constrained extrapolation to generate pseudo-labels. This addresses the second concern, which in turn solves the first problem, enabling an even weaker supervision requirement than CHILLAX. We evaluate our approach empirically and show that our method allows for a consistent accuracy improvement of 0.84 to 1.19 percent points over CHILLAX and is suitable as a drop-in replacement without any negative consequences such as longer training times.
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Oct 13, 2020
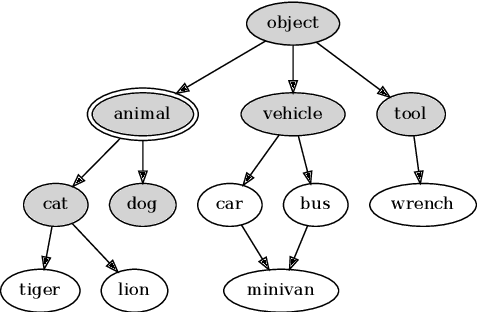


Noisy data, crawled from the web or supplied by volunteers such as Mechanical Turkers or citizen scientists, is considered an alternative to professionally labeled data. There has been research focused on mitigating the effects of label noise. It is typically modeled as inaccuracy, where the correct label is replaced by an incorrect label from the same set. We consider an additional dimension of label noise: imprecision. For example, a non-breeding snow bunting is labeled as a bird. This label is correct, but not as precise as the task requires. Standard softmax classifiers cannot learn from such a weak label because they consider all classes mutually exclusive, which non-breeding snow bunting and bird are not. We propose CHILLAX (Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation), a method based on hierarchical classification, to fully utilize labels of any precision. Experiments on noisy variants of NABirds and ILSVRC2012 show that our method outperforms strong baselines by as much as 16.4 percentage points, and the current state of the art by up to 3.9 percentage points.
Active and Incremental Learning with Weak Supervision
Jan 20, 2020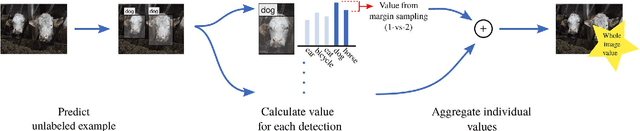
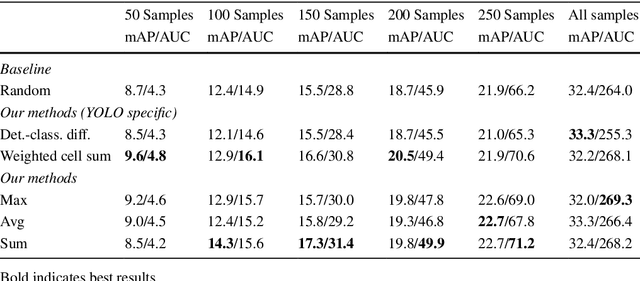

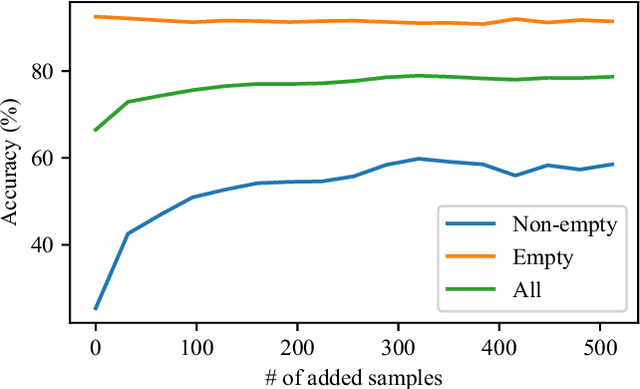
Large amounts of labeled training data are one of the main contributors to the great success that deep models have achieved in the past. Label acquisition for tasks other than benchmarks can pose a challenge due to requirements of both funding and expertise. By selecting unlabeled examples that are promising in terms of model improvement and only asking for respective labels, active learning can increase the efficiency of the labeling process in terms of time and cost. In this work, we describe combinations of an incremental learning scheme and methods of active learning. These allow for continuous exploration of newly observed unlabeled data. We describe selection criteria based on model uncertainty as well as expected model output change (EMOC). An object detection task is evaluated in a continuous exploration context on the PASCAL VOC dataset. We also validate a weakly supervised system based on active and incremental learning in a real-world biodiversity application where images from camera traps are analyzed. Labeling only 32 images by accepting or rejecting proposals generated by our method yields an increase in accuracy from 25.4% to 42.6%.
Integrating domain knowledge: using hierarchies to improve deep classifiers
Nov 17, 2018


One of the most prominent problems in machine learning in the age of deep learning is the availability of sufficiently large annotated datasets. While for standard problem domains (ImageNet classification), appropriate datasets exist, for specific domains, \eg classification of animal species, a long-tail distribution means that some classes are observed and annotated insufficiently. Challenges like iNaturalist show that there is a strong interest in species recognition. Acquiring additional labels can be prohibitively expensive. First, since domain experts need to be involved, and second, because acquisition of new data might be costly. Although there exist methods for data augmentation, which not always lead to better performance of the classifier, there is more additional information available that is to the best of our knowledge not exploited accordingly. In this paper, we propose to make use of existing class hierarchies like WordNet to integrate additional domain knowledge into classification. We encode the properties of such a class hierarchy into a probabilistic model. From there, we derive a special label encoding together with a corresponding loss function. Using a convolutional neural network, on the ImageNet and NABirds datasets our method offers a relative improvement of 10.4% and 9.6% in accuracy over the baseline respectively. After less than a third of training time, it is already able to match the baseline's fine-grained recognition performance. Both results show that our suggested method is efficient and effective.
Not just a matter of semantics: the relationship between visual similarity and semantic similarity
Nov 17, 2018



Knowledge transfer, zero-shot learning and semantic image retrieval are methods that aim at improving accuracy by utilizing semantic information, e.g. from WordNet. It is assumed that this information can augment or replace missing visual data in the form of labeled training images because semantic similarity somewhat aligns with visual similarity. This assumption may seem trivial, but is crucial for the application of such semantic methods. Any violation can cause mispredictions. Thus, it is important to examine the visual-semantic relationship for a certain target problem. In this paper, we use five different semantic and visual similarity measures each to thoroughly analyze the relationship without relying too much on any single definition. We postulate and verify three highly consequential hypotheses on the relationship. Our results show that it indeed exists and that WordNet semantic similarity carries more information about visual similarity than just the knowledge of "different classes look different". They suggest that classification is not the ideal application for semantic methods and that wrong semantic information is much worse than none.
Active Learning for Deep Object Detection
Sep 26, 2018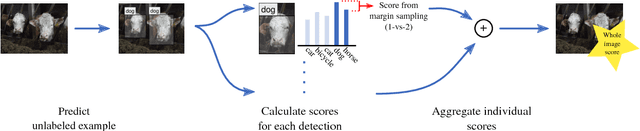
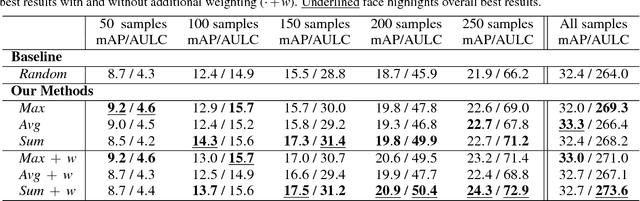
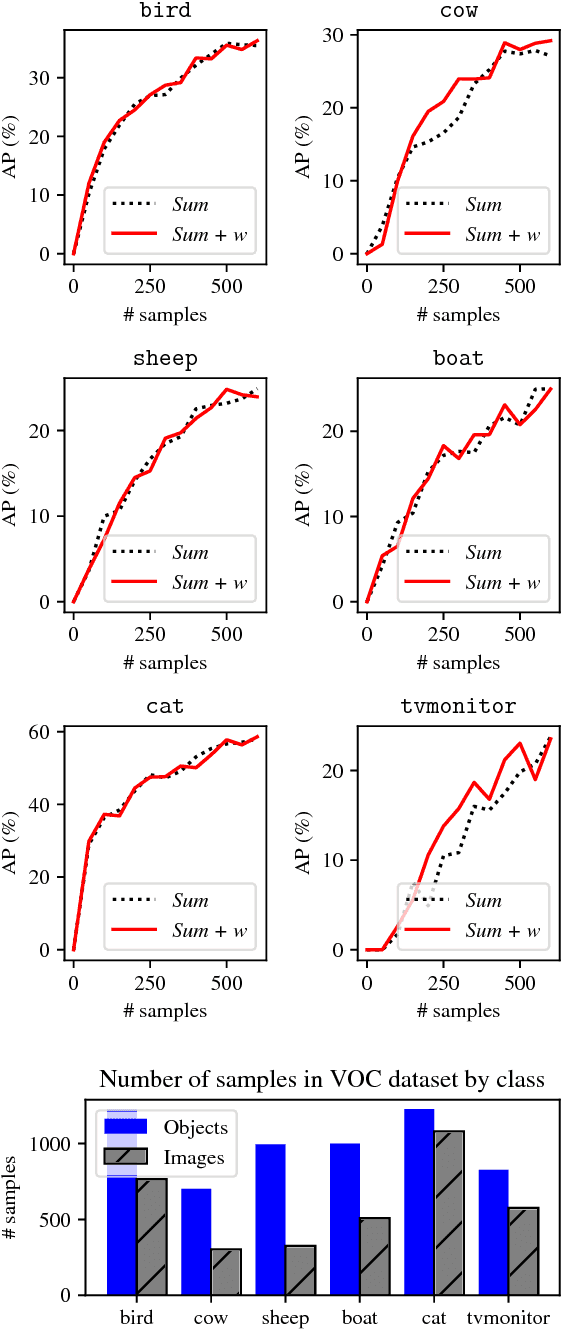

The great success that deep models have achieved in the past is mainly owed to large amounts of labeled training data. However, the acquisition of labeled data for new tasks aside from existing benchmarks is both challenging and costly. Active learning can make the process of labeling new data more efficient by selecting unlabeled samples which, when labeled, are expected to improve the model the most. In this paper, we combine a novel method of active learning for object detection with an incremental learning scheme to enable continuous exploration of new unlabeled datasets. We propose a set of uncertainty-based active learning metrics suitable for most object detectors. Furthermore, we present an approach to leverage class imbalances during sample selection. All methods are evaluated systematically in a continuous exploration context on the PASCAL VOC 2012 dataset.
Neither Quick Nor Proper -- Evaluation of QuickProp for Learning Deep Neural Networks
Jun 15, 2016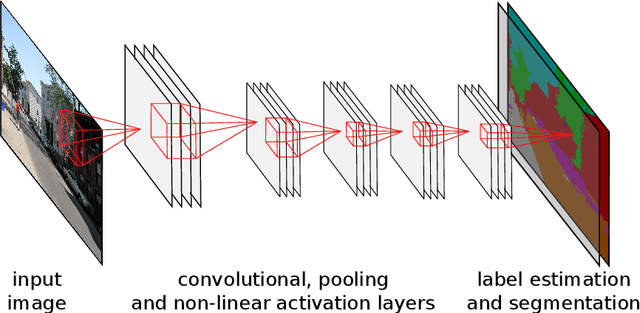

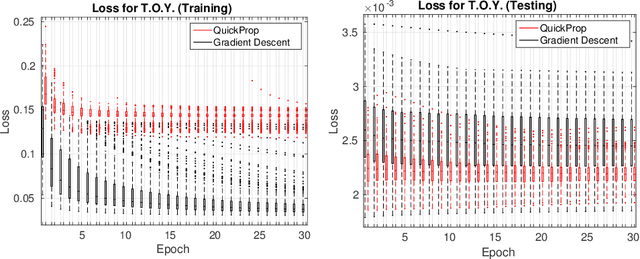
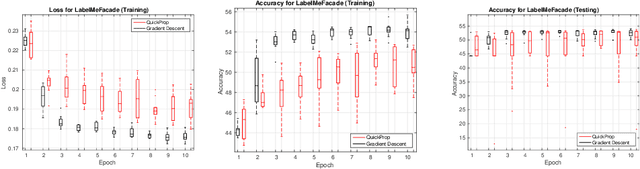
Neural networks and especially convolutional neural networks are of great interest in current computer vision research. However, many techniques, extensions, and modifications have been published in the past, which are not yet used by current approaches. In this paper, we study the application of a method called QuickProp for training of deep neural networks. In particular, we apply QuickProp during learning and testing of fully convolutional networks for the task of semantic segmentation. We compare QuickProp empirically with gradient descent, which is the current standard method. Experiments suggest that QuickProp can not compete with standard gradient descent techniques for complex computer vision tasks like semantic segmentation.
Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding
Feb 23, 2015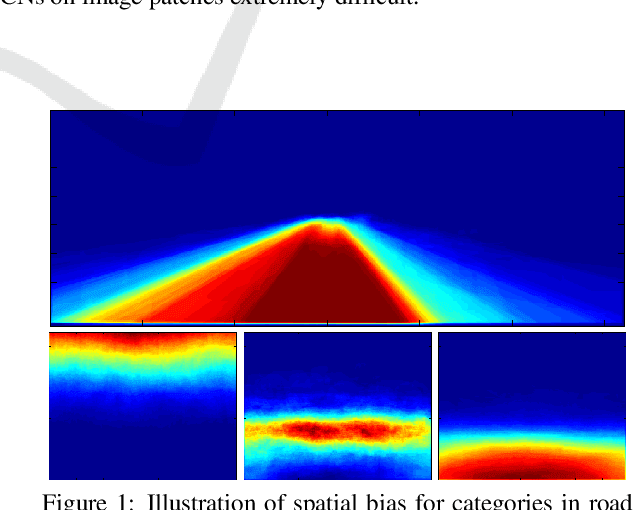
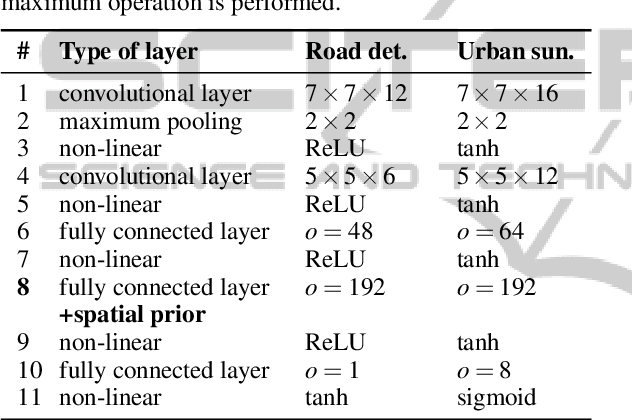
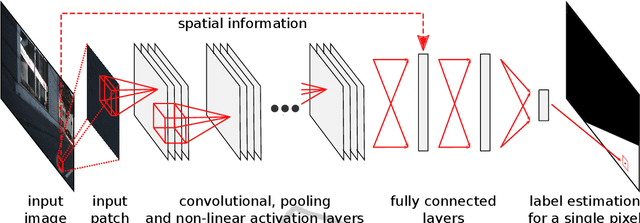
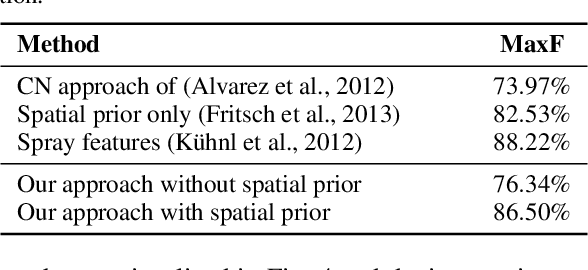
Classifying single image patches is important in many different applications, such as road detection or scene understanding. In this paper, we present convolutional patch networks, which are convolutional networks learned to distinguish different image patches and which can be used for pixel-wise labeling. We also show how to incorporate spatial information of the patch as an input to the network, which allows for learning spatial priors for certain categories jointly with an appearance model. In particular, we focus on road detection and urban scene understanding, two application areas where we are able to achieve state-of-the-art results on the KITTI as well as on the LabelMeFacade dataset. Furthermore, our paper offers a guideline for people working in the area and desperately wandering through all the painstaking details that render training CNs on image patches extremely difficult.