 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizability of Code Clone Detection on CodeBERT
Sep 01, 2022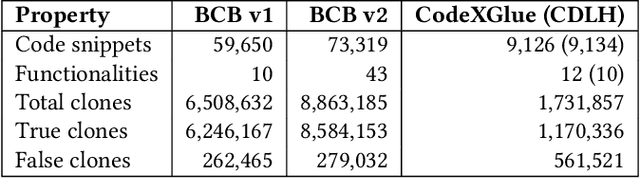
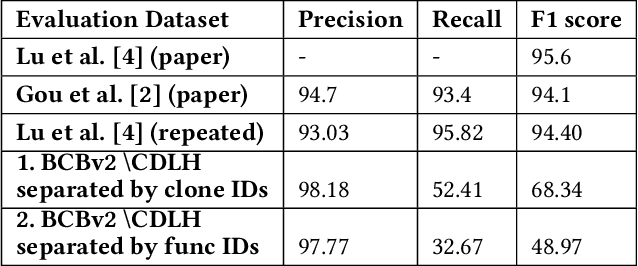
Transformer networks such as CodeBERT already achieve outstanding results for code clone detection in benchmark datasets, so one could assume that this task has already been solved. However, code clone detection is not a trivial task. Semantic code clones, in particular, are challenging to detect. We show that the generalizability of CodeBERT decreases by evaluating two different subsets of Java code clones from BigCloneBench. We observe a significant drop in F1 score when we evaluate different code snippets and functionality IDs than those used for model building.
Cross-Domain Evaluation of a Deep Learning-Based Type Inference System
Aug 19, 2022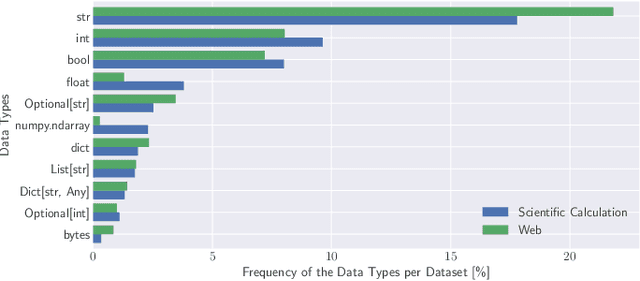
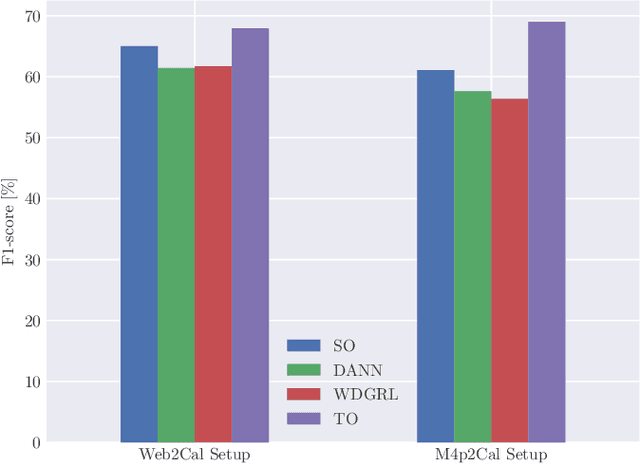
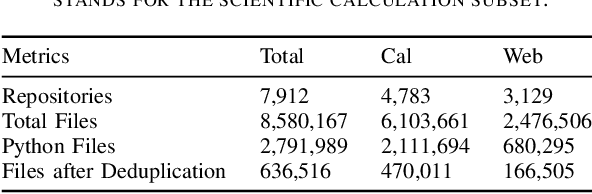

Optional type annotations allow for enriching dynamic programming languages with static typing features like better Integrated Development Environment (IDE) support, more precise program analysis, and early detection and prevention of type-related runtime errors. Machine learning-based type inference promises interesting results for automating this task. However, the practical usage of such systems depends on their ability to generalize across different domains, as they are often applied outside their training domain. In this work, we investigate the generalization ability of Type4Py as a representative for state-of-the-art deep learning-based type inference systems, by conducting extensive cross-domain experiments. Thereby, we address the following problems: dataset shifts, out-of-vocabulary words, unknown classes, and rare classes. To perform such experiments, we use the datasets ManyTypes4Py and CrossDomainTypes4Py. The latter we introduce in this paper. Our dataset has over 1,000,000 type annotations and enables cross-domain evaluation of type inference systems in different domains of software projects using data from the two domains web development and scientific calculation. Through our experiments, we detect shifts in the dataset and that it has a long-tailed distribution with many rare and unknown data types which decreases the performance of the deep learning-based type inference system drastically. In this context, we test unsupervised domain adaptation methods and fine-tuning to overcome the issues. Moreover, we investigate the impact of out-of-vocabulary words.
Domain Adaptation and Active Learning for Fine-Grained Recognition in the Field of Biodiversity
Oct 22, 2021
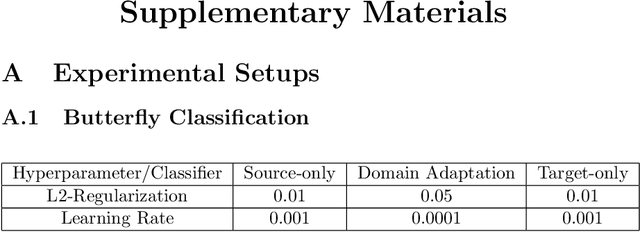


Deep-learning methods offer unsurpassed recognition performance in a wide range of domains, including fine-grained recognition tasks. However, in most problem areas there are insufficient annotated training samples. Therefore, the topic of transfer learning respectively domain adaptation is particularly important. In this work, we investigate to what extent unsupervised domain adaptation can be used for fine-grained recognition in a biodiversity context to learn a real-world classifier based on idealized training data, e.g. preserved butterflies and plants. Moreover, we investigate the influence of different normalization layers, such as Group Normalization in combination with Weight Standardization, on the classifier. We discovered that domain adaptation works very well for fine-grained recognition and that the normalization methods have a great influence on the results. Using domain adaptation and Transferable Normalization, the accuracy of the classifier could be increased by up to 12.35 % compared to the baseline. Furthermore, the domain adaptation system is combined with an active learning component to improve the results. We compare different active learning strategies with each other. Surprisingly, we found that more sophisticated strategies provide better results than the random selection baseline for only one of the two datasets. In this case, the distance and diversity strategy performed best. Finally, we present a problem analysis of the datasets.