 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Tuning SAM: From Generalist to Specialist with only 2048 Parameters and 16 Training Images
Apr 23, 2025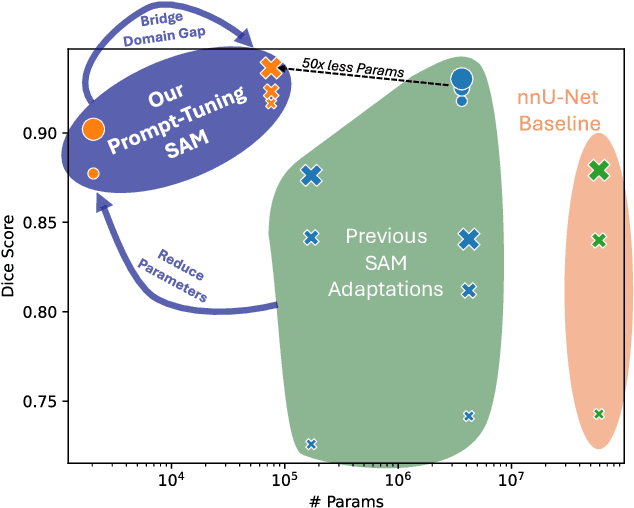
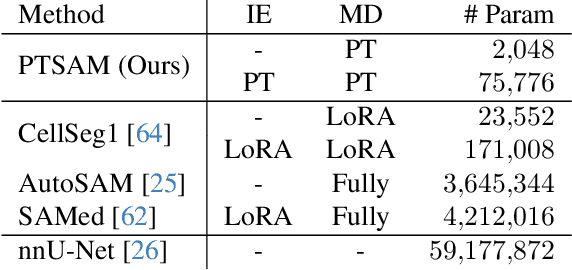
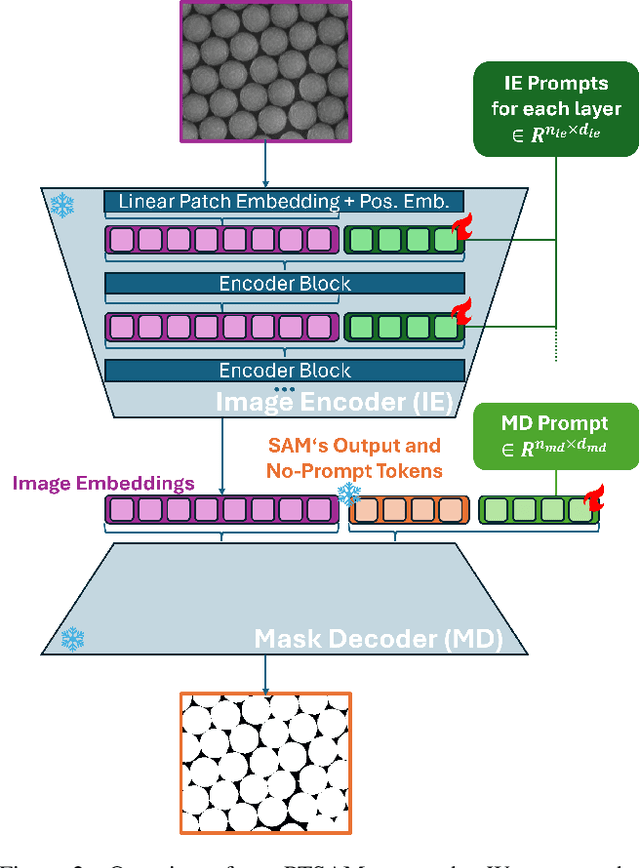
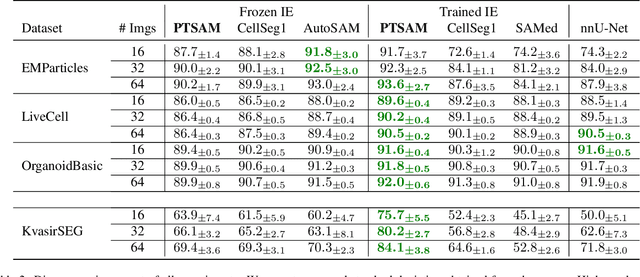
The Segment Anything Model (SAM) is widely used for segmenting a diverse range of objects in natural images from simple user prompts like points or bounding boxes. However, SAM's performance decreases substantially when applied to non-natural domains like microscopic imaging. Furthermore, due to SAM's interactive design, it requires a precise prompt for each image and object, which is unfeasible in many automated biomedical applications. Previous solutions adapt SAM by training millions of parameters via fine-tuning large parts of the model or of adapter layers. In contrast, we show that as little as 2,048 additional parameters are sufficient for turning SAM into a use-case specialist for a certain downstream task. Our novel PTSAM (prompt-tuned SAM) method uses prompt-tuning, a parameter-efficient fine-tuning technique, to adapt SAM for a specific task. We validate the performance of our approach on multiple microscopic and one medical dataset. Our results show that prompt-tuning only SAM's mask decoder already leads to a performance on-par with state-of-the-art techniques while requiring roughly 2,000x less trainable parameters. For addressing domain gaps, we find that additionally prompt-tuning SAM's image encoder is beneficial, further improving segmentation accuracy by up to 18% over state-of-the-art results. Since PTSAM can be reliably trained with as little as 16 annotated images, we find it particularly helpful for applications with limited training data and domain shifts.
Domain Adaptation and Active Learning for Fine-Grained Recognition in the Field of Biodiversity
Oct 22, 2021
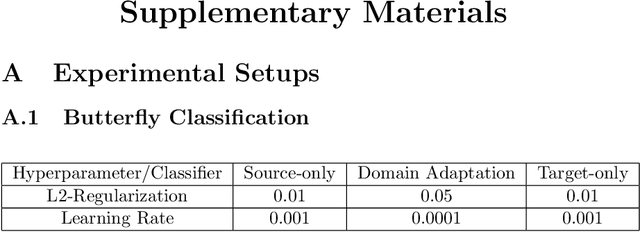


Deep-learning methods offer unsurpassed recognition performance in a wide range of domains, including fine-grained recognition tasks. However, in most problem areas there are insufficient annotated training samples. Therefore, the topic of transfer learning respectively domain adaptation is particularly important. In this work, we investigate to what extent unsupervised domain adaptation can be used for fine-grained recognition in a biodiversity context to learn a real-world classifier based on idealized training data, e.g. preserved butterflies and plants. Moreover, we investigate the influence of different normalization layers, such as Group Normalization in combination with Weight Standardization, on the classifier. We discovered that domain adaptation works very well for fine-grained recognition and that the normalization methods have a great influence on the results. Using domain adaptation and Transferable Normalization, the accuracy of the classifier could be increased by up to 12.35 % compared to the baseline. Furthermore, the domain adaptation system is combined with an active learning component to improve the results. We compare different active learning strategies with each other. Surprisingly, we found that more sophisticated strategies provide better results than the random selection baseline for only one of the two datasets. In this case, the distance and diversity strategy performed best. Finally, we present a problem analysis of the datasets.
A Strong Baseline for the VIPriors Data-Efficient Image Classification Challenge
Sep 28, 2021
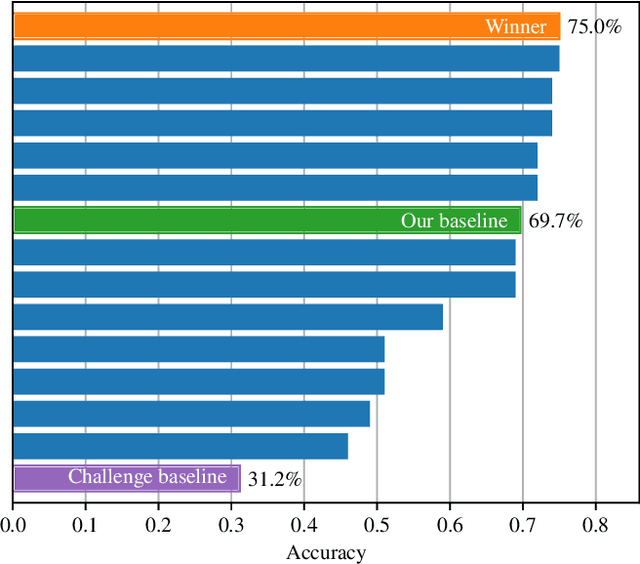
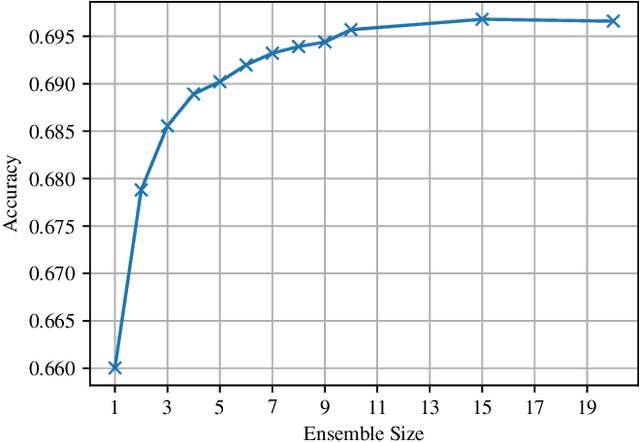
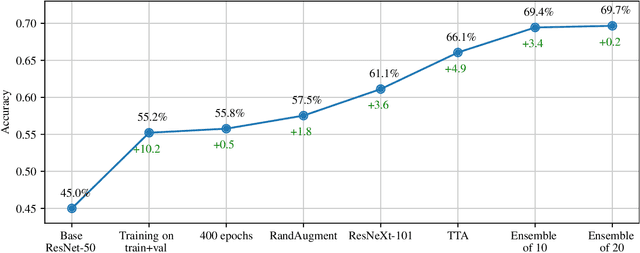
Learning from limited amounts of data is the hallmark of intelligence, requiring strong generalization and abstraction skills. In a machine learning context, data-efficient methods are of high practical importance since data collection and annotation are prohibitively expensive in many domains. Thus, coordinated efforts to foster progress in this area emerged recently, e.g., in the form of dedicated workshops and competitions. Besides a common benchmark, measuring progress requires strong baselines. We present such a strong baseline for data-efficient image classification on the VIPriors challenge dataset, which is a sub-sampled version of ImageNet-1k with 100 images per class. We do not use any methods tailored to data-efficient classification but only standard models and techniques as well as common competition tricks and thorough hyper-parameter tuning. Our baseline achieves 69.7% accuracy on the VIPriors image classification dataset and outperforms 50% of submissions to the VIPriors 2021 challenge.
Anomaly Attribution of Multivariate Time Series using Counterfactual Reasoning
Sep 14, 2021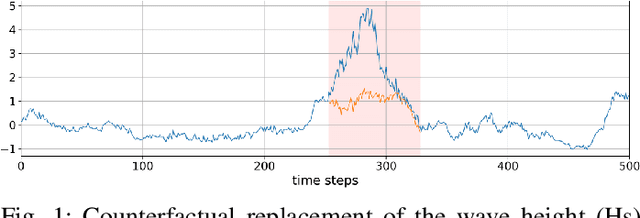
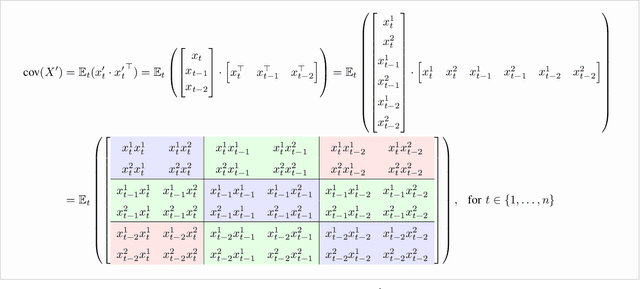
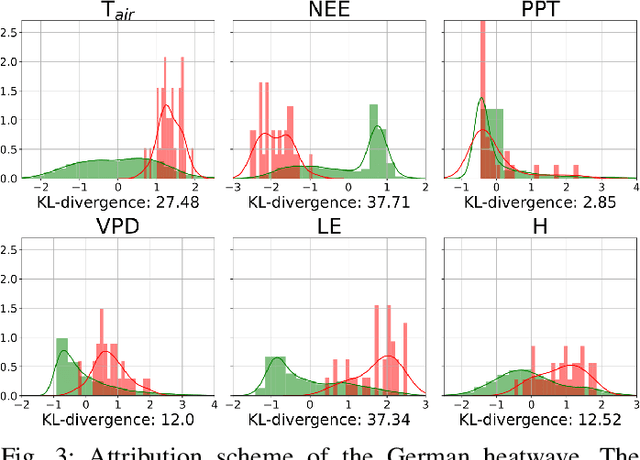
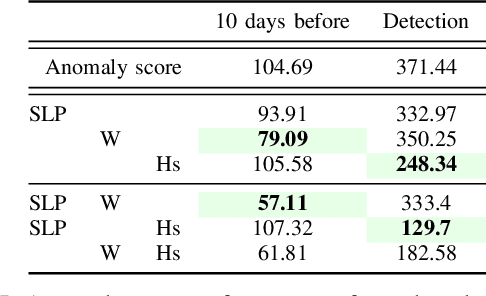
There are numerous methods for detecting anomalies in time series, but that is only the first step to understanding them. We strive to exceed this by explaining those anomalies. Thus we develop a novel attribution scheme for multivariate time series relying on counterfactual reasoning. We aim to answer the counterfactual question of would the anomalous event have occurred if the subset of the involved variables had been more similarly distributed to the data outside of the anomalous interval. Specifically, we detect anomalous intervals using the Maximally Divergent Interval (MDI) algorithm, replace a subset of variables with their in-distribution values within the detected interval and observe if the interval has become less anomalous, by re-scoring it with MDI. We evaluate our method on multivariate temporal and spatio-temporal data and confirm the accuracy of our anomaly attribution of multiple well-understood extreme climate events such as heatwaves and hurricanes.
Tune It or Don't Use It: Benchmarking Data-Efficient Image Classification
Aug 30, 2021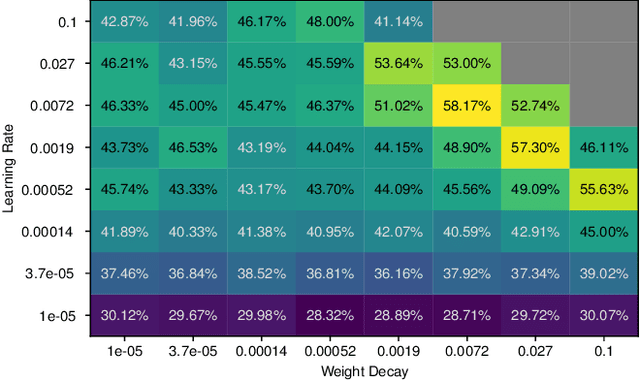
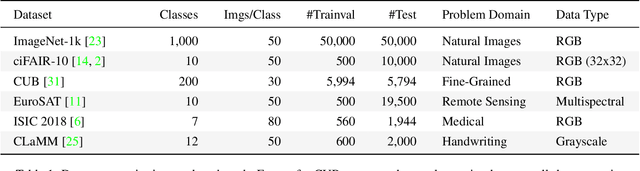

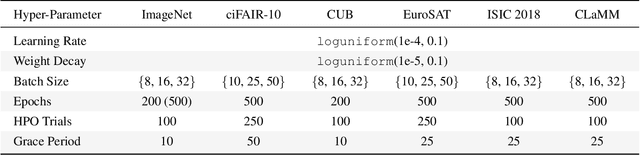
Data-efficient image classification using deep neural networks in settings, where only small amounts of labeled data are available, has been an active research area in the recent past. However, an objective comparison between published methods is difficult, since existing works use different datasets for evaluation and often compare against untuned baselines with default hyper-parameters. We design a benchmark for data-efficient image classification consisting of six diverse datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). Using this benchmark, we re-evaluate the standard cross-entropy baseline and eight methods for data-efficient deep learning published between 2017 and 2021 at renowned venues. For a fair and realistic comparison, we carefully tune the hyper-parameters of all methods on each dataset. Surprisingly, we find that tuning learning rate, weight decay, and batch size on a separate validation split results in a highly competitive baseline, which outperforms all but one specialized method and performs competitively to the remaining one.
WikiChurches: A Fine-Grained Dataset of Architectural Styles with Real-World Challenges
Aug 16, 2021

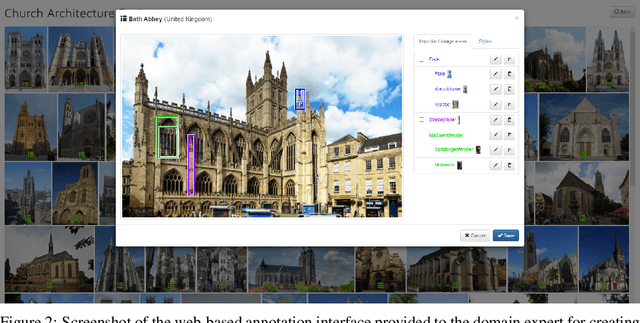

We introduce a novel dataset for architectural style classification, consisting of 9,485 images of church buildings. Both images and style labels were sourced from Wikipedia. The dataset can serve as a benchmark for various research fields, as it combines numerous real-world challenges: fine-grained distinctions between classes based on subtle visual features, a comparatively small sample size, a highly imbalanced class distribution, a high variance of viewpoints, and a hierarchical organization of labels, where only some images are labeled at the most precise level. In addition, we provide 631 bounding box annotations of characteristic visual features for 139 churches from four major categories. These annotations can, for example, be useful for research on fine-grained classification, where additional expert knowledge about distinctive object parts is often available. Images and annotations are available at: https://doi.org/10.5281/zenodo.5166987
Self-Supervised Learning from Semantically Imprecise Data
Apr 22, 2021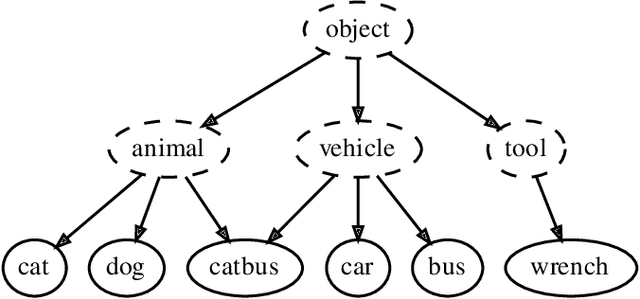
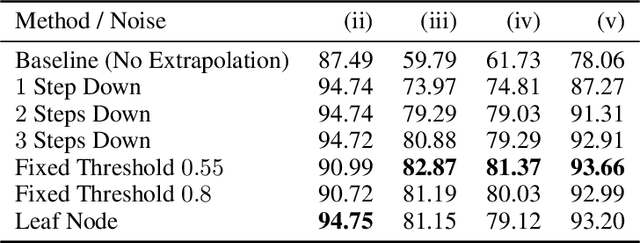

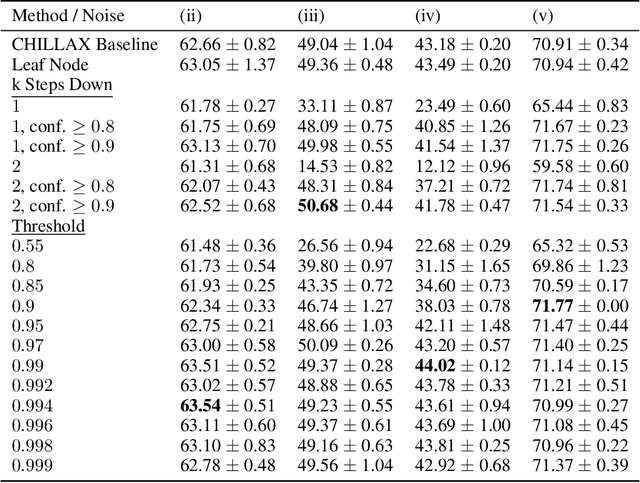
Learning from imprecise labels such as "animal" or "bird", but making precise predictions like "snow bunting" at test time is an important capability when expertly labeled training data is scarce. Contributions by volunteers or results of web crawling lack precision in this manner, but are still valuable. And crucially, these weakly labeled examples are available in larger quantities for lower cost than high-quality bespoke training data. CHILLAX, a recently proposed method to tackle this task, leverages a hierarchical classifier to learn from imprecise labels. However, it has two major limitations. First, it is not capable of learning from effectively unlabeled examples at the root of the hierarchy, e.g. "object". Second, an extrapolation of annotations to precise labels is only performed at test time, where confident extrapolations could be already used as training data. In this work, we extend CHILLAX with a self-supervised scheme using constrained extrapolation to generate pseudo-labels. This addresses the second concern, which in turn solves the first problem, enabling an even weaker supervision requirement than CHILLAX. We evaluate our approach empirically and show that our method allows for a consistent accuracy improvement of 0.84 to 1.19 percent points over CHILLAX and is suitable as a drop-in replacement without any negative consequences such as longer training times.
Content-based Image Retrieval and the Semantic Gap in the Deep Learning Era
Nov 12, 2020

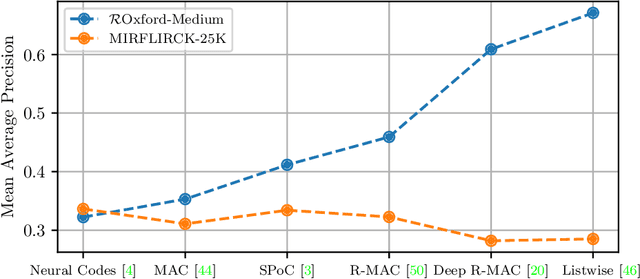
Content-based image retrieval has seen astonishing progress over the past decade, especially for the task of retrieving images of the same object that is depicted in the query image. This scenario is called instance or object retrieval and requires matching fine-grained visual patterns between images. Semantics, however, do not play a crucial role. This brings rise to the question: Do the recent advances in instance retrieval transfer to more generic image retrieval scenarios? To answer this question, we first provide a brief overview of the most relevant milestones of instance retrieval. We then apply them to a semantic image retrieval task and find that they perform inferior to much less sophisticated and more generic methods in a setting that requires image understanding. Following this, we review existing approaches to closing this so-called semantic gap by integrating prior world knowledge. We conclude that the key problem for the further advancement of semantic image retrieval lies in the lack of a standardized task definition and an appropriate benchmark dataset.
Finding Relevant Flood Images on Twitter using Content-based Filters
Nov 11, 2020
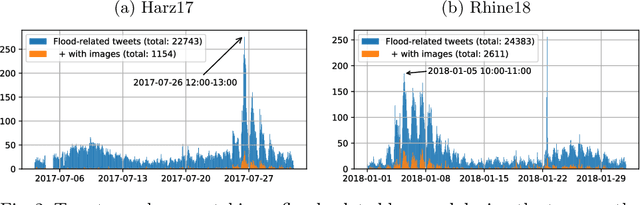
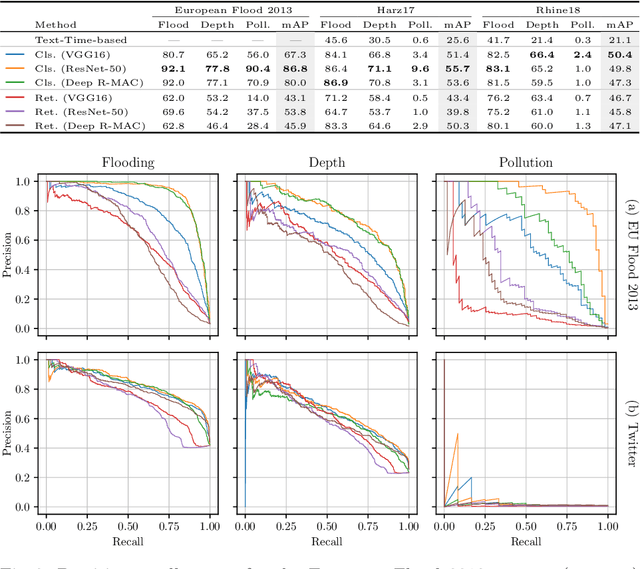
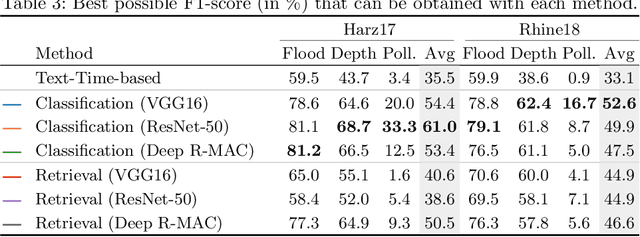
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to coarsely distributed sensors or sensor failures. At the same time, a plethora of information is buried in an abundance of images of the event posted on social media platforms such as Twitter. These images could be used to document and rapidly assess the situation and derive proxy-data not available from sensors, e.g., the degree of water pollution. However, not all images posted online are suitable or informative enough for this purpose. Therefore, we propose an automatic filtering approach using machine learning techniques for finding Twitter images that are relevant for one of the following information objectives: assessing the flooded area, the inundation depth, and the degree of water pollution. Instead of relying on textual information present in the tweet, the filter analyzes the image contents directly. We evaluate the performance of two different approaches and various features on a case-study of two major flooding events. Our image-based filter is able to enhance the quality of the results substantially compared with a keyword-based filter, improving the mean average precision from 23% to 53% on average.
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Oct 13, 2020
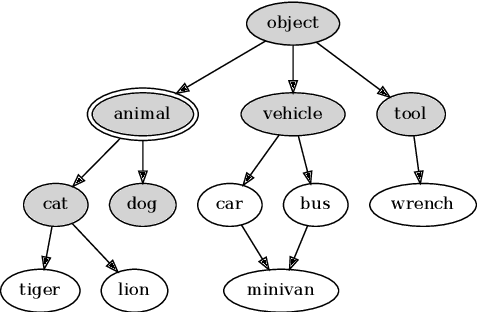


Noisy data, crawled from the web or supplied by volunteers such as Mechanical Turkers or citizen scientists, is considered an alternative to professionally labeled data. There has been research focused on mitigating the effects of label noise. It is typically modeled as inaccuracy, where the correct label is replaced by an incorrect label from the same set. We consider an additional dimension of label noise: imprecision. For example, a non-breeding snow bunting is labeled as a bird. This label is correct, but not as precise as the task requires. Standard softmax classifiers cannot learn from such a weak label because they consider all classes mutually exclusive, which non-breeding snow bunting and bird are not. We propose CHILLAX (Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation), a method based on hierarchical classification, to fully utilize labels of any precision. Experiments on noisy variants of NABirds and ILSVRC2012 show that our method outperforms strong baselines by as much as 16.4 percentage points, and the current state of the art by up to 3.9 percentage points.