 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Tuning SAM: From Generalist to Specialist with only 2048 Parameters and 16 Training Images
Apr 23, 2025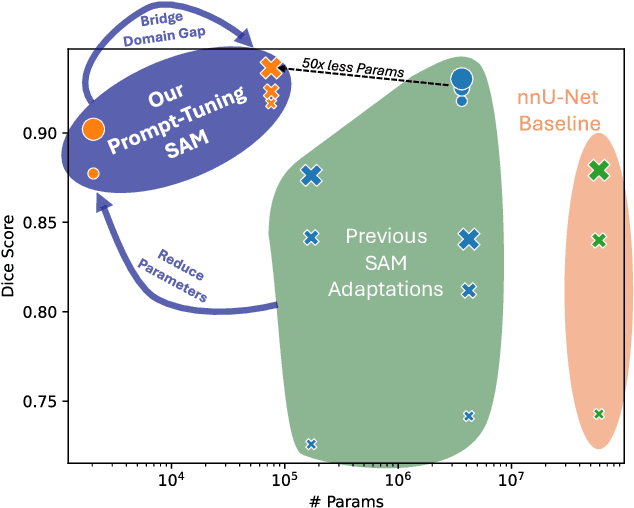
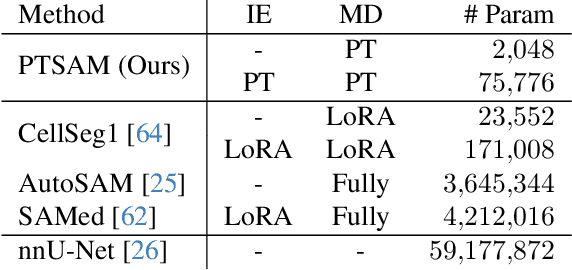
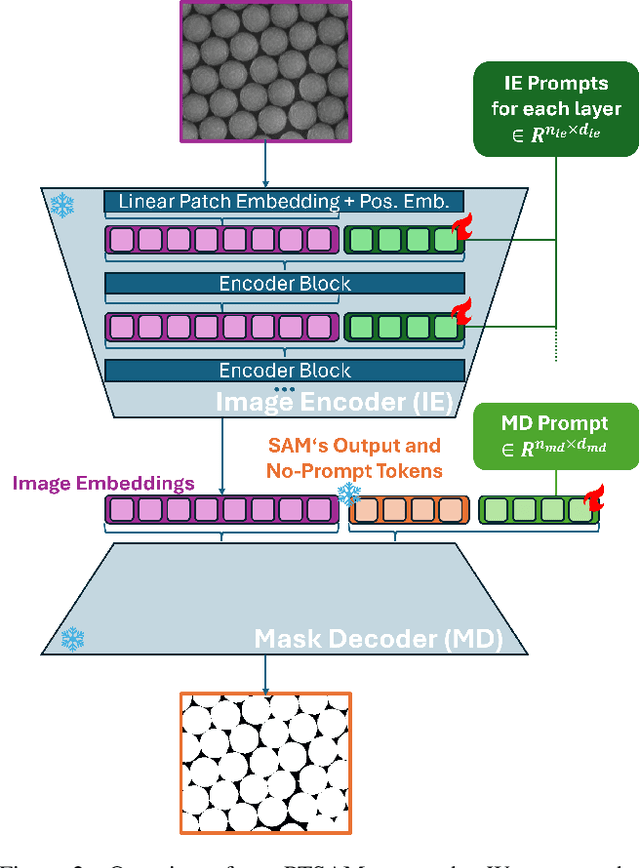
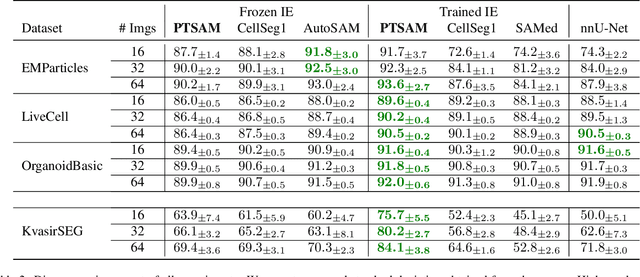
The Segment Anything Model (SAM) is widely used for segmenting a diverse range of objects in natural images from simple user prompts like points or bounding boxes. However, SAM's performance decreases substantially when applied to non-natural domains like microscopic imaging. Furthermore, due to SAM's interactive design, it requires a precise prompt for each image and object, which is unfeasible in many automated biomedical applications. Previous solutions adapt SAM by training millions of parameters via fine-tuning large parts of the model or of adapter layers. In contrast, we show that as little as 2,048 additional parameters are sufficient for turning SAM into a use-case specialist for a certain downstream task. Our novel PTSAM (prompt-tuned SAM) method uses prompt-tuning, a parameter-efficient fine-tuning technique, to adapt SAM for a specific task. We validate the performance of our approach on multiple microscopic and one medical dataset. Our results show that prompt-tuning only SAM's mask decoder already leads to a performance on-par with state-of-the-art techniques while requiring roughly 2,000x less trainable parameters. For addressing domain gaps, we find that additionally prompt-tuning SAM's image encoder is beneficial, further improving segmentation accuracy by up to 18% over state-of-the-art results. Since PTSAM can be reliably trained with as little as 16 annotated images, we find it particularly helpful for applications with limited training data and domain shifts.
When Medical Imaging Met Self-Attention: A Love Story That Didn't Quite Work Out
Apr 18, 2024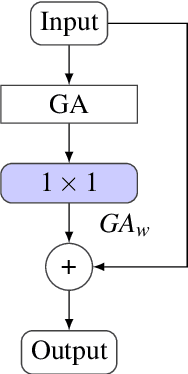
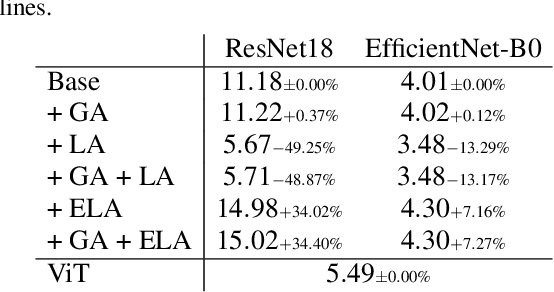
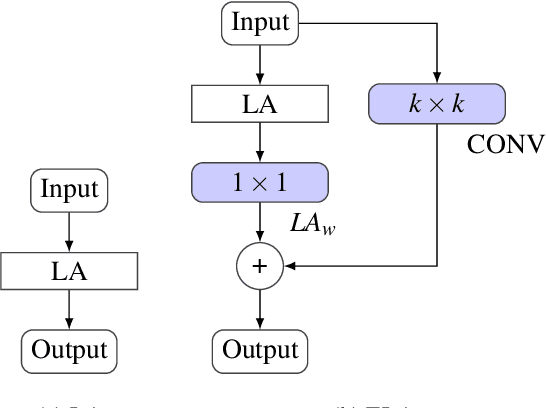
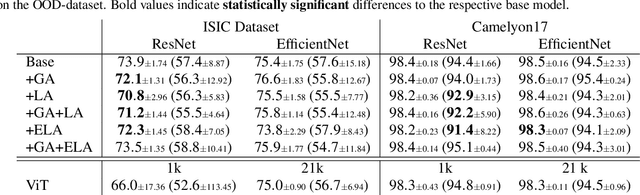
A substantial body of research has focused on developing systems that assist medical professionals during labor-intensive early screening processes, many based on convolutional deep-learning architectures. Recently, multiple studies explored the application of so-called self-attention mechanisms in the vision domain. These studies often report empirical improvements over fully convolutional approaches on various datasets and tasks. To evaluate this trend for medical imaging, we extend two widely adopted convolutional architectures with different self-attention variants on two different medical datasets. With this, we aim to specifically evaluate the possible advantages of additional self-attention. We compare our models with similarly sized convolutional and attention-based baselines and evaluate performance gains statistically. Additionally, we investigate how including such layers changes the features learned by these models during the training. Following a hyperparameter search, and contrary to our expectations, we observe no significant improvement in balanced accuracy over fully convolutional models. We also find that important features, such as dermoscopic structures in skin lesion images, are still not learned by employing self-attention. Finally, analyzing local explanations, we confirm biased feature usage. We conclude that merely incorporating attention is insufficient to surpass the performance of existing fully convolutional methods.
* 10 pages, 2 figures, 5 tables, presented at VISAPP 2024