 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPIC: Amortized Physics-Informed Calibration using Neural Processes
Jun 02, 2026Physics models are inherently imperfect due to misspecified or missing mechanisms, resulting in systematic discrepancies between model predictions and real-world observations. The Kennedy-O'Hagan (KOH) framework addresses this issue through explicit discrepancy modeling. However, its non-amortized, per-instance formulation limits scalability across families of related systems. We introduce Amortized Physics-Informed Calibration (APIC), a population-level extension of KOH that leverages Neural Processes to perform scalable Bayesian inference across realizations. Our framework employs a two-branch latent architecture to disentangle instance-specific physical parameters from shared, state-dependent structural discrepancies. By integrating differentiable physics into an amortized inference backbone, APIC enables rapid calibration of unseen realizations from sparse observations while quantifying uncertainty. Experiments on the damped spring oscillator, the Lotka-Volterra system, and the advection-diffusion PDE with misspecified physics demonstrate improved parameter recovery and consistent identification of the systemic discrepancy structure compared to other calibration approaches.
TCD-Arena: Assessing Robustness of Time Series Causal Discovery Methods Against Assumption Violations
May 04, 2026Causal Discovery (CD) is a powerful framework for scientific inquiry. Yet, its practical adoption is hindered by a reliance on strong, often unverifiable assumptions and a lack of robust performance assessment. To address these limitations and advance empirical CD evaluation, we present TCD-Arena, a modularized, highly customizable, and extendable testing kit to assess the robustness of time series CD algorithms against stepwise more severe assumption violations. For demonstration, we conduct an extensive empirical study comprising around 30 million individual CD attempts and reveal nuanced robustness profiles for 33 distinct assumption violations. Further, we investigate CD ensembles and find that they have the potential to improve general robustness, which has implications for real-world applications. With this, we strive to ultimately facilitate the development of CD methods that are reliable for a diverse range of synthetic and potentially real-world data conditions.
Beyond Subtokens: A Rich Character Embedding for Low-resource and Morphologically Complex Languages
Feb 24, 2026Tokenization and sub-tokenization based models like word2vec, BERT and the GPTs are the state-of-the-art in natural language processing. Typically, these approaches have limitations with respect to their input representation. They fail to fully capture orthographic similarities and morphological variations, especially in highly inflected and under-resource languages. To mitigate this problem, we propose to computes word vectors directly from character strings, integrating both semantic and syntactic information. We denote this transformer-based approach Rich Character Embeddings (RCE). Furthermore, we propose a hybrid model that combines transformer and convolutional mechanisms. Both vector representations can be used as a drop-in replacement for dictionary- and subtoken-based word embeddings in existing model architectures. It has the potential to improve performance for both large context-based language models like BERT and small models like word2vec for under-resourced and morphologically rich languages. We evaluate our approach on various tasks like the SWAG, declension prediction for inflected languages, metaphor and chiasmus detection for various languages. Our experiments show that it outperforms traditional token-based approaches on limited data using OddOneOut and TopK metrics.
Realistic Face Reconstruction from Facial Embeddings via Diffusion Models
Feb 13, 2026With the advancement of face recognition (FR) systems, privacy-preserving face recognition (PPFR) systems have gained popularity for their accurate recognition, enhanced facial privacy protection, and robustness to various attacks. However, there are limited studies to further verify privacy risks by reconstructing realistic high-resolution face images from embeddings of these systems, especially for PPFR. In this work, we propose the face embedding mapping (FEM), a general framework that explores Kolmogorov-Arnold Network (KAN) for conducting the embedding-to-face attack by leveraging pre-trained Identity-Preserving diffusion model against state-of-the-art (SOTA) FR and PPFR systems. Based on extensive experiments, we verify that reconstructed faces can be used for accessing other real-word FR systems. Besides, the proposed method shows the robustness in reconstructing faces from the partial and protected face embeddings. Moreover, FEM can be utilized as a tool for evaluating safety of FR and PPFR systems in terms of privacy leakage. All images used in this work are from public datasets.
Mitigating Spurious Correlations in Patch-wise Tumor Classification on High-Resolution Multimodal Images
Nov 17, 2025Patch-wise multi-label classification provides an efficient alternative to full pixel-wise segmentation on high-resolution images, particularly when the objective is to determine the presence or absence of target objects within a patch rather than their precise spatial extent. This formulation substantially reduces annotation cost, simplifies training, and allows flexible patch sizing aligned with the desired level of decision granularity. In this work, we focus on a special case, patch-wise binary classification, applied to the detection of a single class of interest (tumor) on high-resolution multimodal nonlinear microscopy images. We show that, although this simplified formulation enables efficient model development, it can introduce spurious correlations between patch composition and labels: tumor patches tend to contain larger tissue regions, whereas non-tumor patches often consist mostly of background with small tissue areas. We further quantify the bias in model predictions caused by this spurious correlation, and propose to use a debiasing strategy to mitigate its effect. Specifically, we apply GERNE, a debiasing method that can be adapted to maximize worst-group accuracy (WGA). Our results show an improvement in WGA by approximately 7% compared to ERM for two different thresholds used to binarize the spurious feature. This enhancement boosts model performance on critical minority cases, such as tumor patches with small tissues and non-tumor patches with large tissues, and underscores the importance of spurious correlation-aware learning in patch-wise classification problems.
Uncertainty-aware Physics-informed Neural Networks for Robust CARS-to-Raman Signal Reconstruction
Nov 17, 2025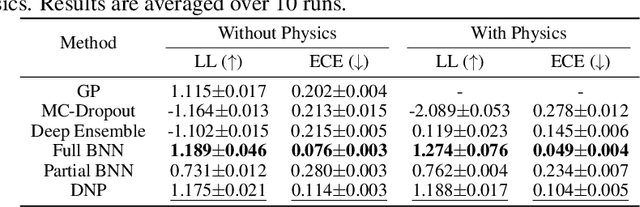
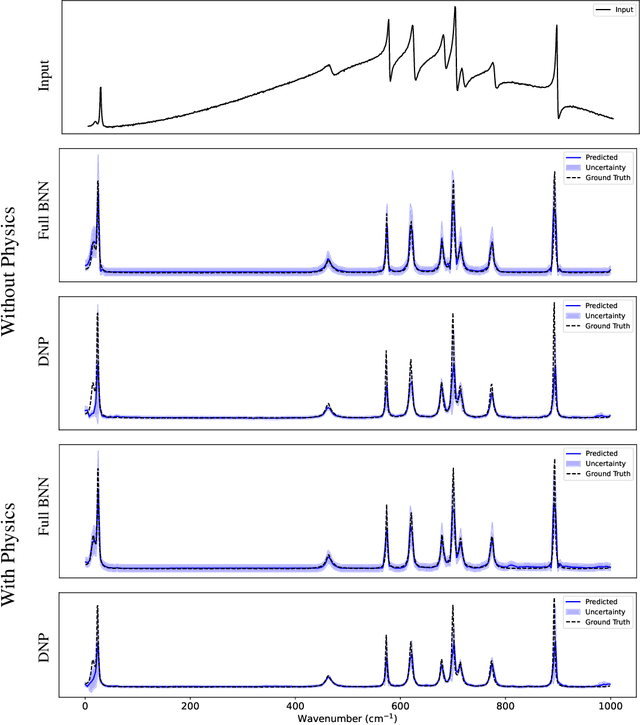
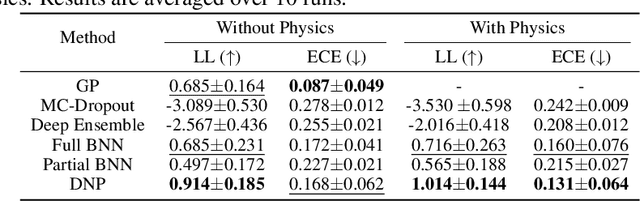
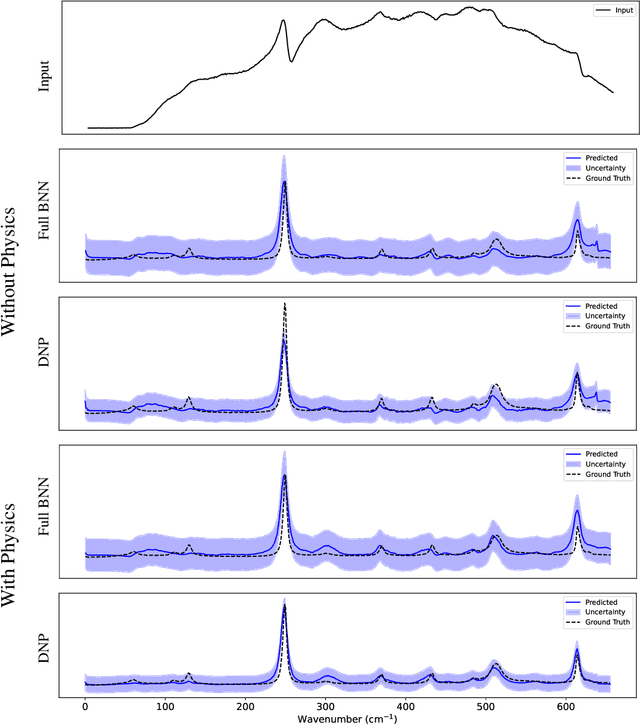
Coherent anti-Stokes Raman scattering (CARS) spectroscopy is a powerful and rapid technique widely used in medicine, material science, and chemical analyses. However, its effectiveness is hindered by the presence of a non-resonant background that interferes with and distorts the true Raman signal. Deep learning methods have been employed to reconstruct the true Raman spectrum from measured CARS data using labeled datasets. A more recent development integrates the domain knowledge of Kramers-Kronig relationships and smoothness constraints in the form of physics-informed loss functions. However, these deterministic models lack the ability to quantify uncertainty, an essential feature for reliable deployment in high-stakes scientific and biomedical applications. In this work, we evaluate and compare various uncertainty quantification (UQ) techniques within the context of CARS-to-Raman signal reconstruction. Furthermore, we demonstrate that incorporating physics-informed constraints into these models improves their calibration, offering a promising path toward more trustworthy CARS data analysis.
Saccadic Vision for Fine-Grained Visual Classification
Sep 19, 2025Fine-grained visual classification (FGVC) requires distinguishing between visually similar categories through subtle, localized features - a task that remains challenging due to high intra-class variability and limited inter-class differences. Existing part-based methods often rely on complex localization networks that learn mappings from pixel to sample space, requiring a deep understanding of image content while limiting feature utility for downstream tasks. In addition, sampled points frequently suffer from high spatial redundancy, making it difficult to quantify the optimal number of required parts. Inspired by human saccadic vision, we propose a two-stage process that first extracts peripheral features (coarse view) and generates a sample map, from which fixation patches are sampled and encoded in parallel using a weight-shared encoder. We employ contextualized selective attention to weigh the impact of each fixation patch before fusing peripheral and focus representations. To prevent spatial collapse - a common issue in part-based methods - we utilize non-maximum suppression during fixation sampling to eliminate redundancy. Comprehensive evaluation on standard FGVC benchmarks (CUB-200-2011, NABirds, Food-101 and Stanford-Dogs) and challenging insect datasets (EU-Moths, Ecuador-Moths and AMI-Moths) demonstrates that our method achieves comparable performance to state-of-the-art approaches while consistently outperforming our baseline encoder.
Distance-informed Neural Processes
Aug 26, 2025We propose the Distance-informed Neural Process (DNP), a novel variant of Neural Processes that improves uncertainty estimation by combining global and distance-aware local latent structures. Standard Neural Processes (NPs) often rely on a global latent variable and struggle with uncertainty calibration and capturing local data dependencies. DNP addresses these limitations by introducing a global latent variable to model task-level variations and a local latent variable to capture input similarity within a distance-preserving latent space. This is achieved through bi-Lipschitz regularization, which bounds distortions in input relationships and encourages the preservation of relative distances in the latent space. This modeling approach allows DNP to produce better-calibrated uncertainty estimates and more effectively distinguish in- from out-of-distribution data. Empirical results demonstrate that DNP achieves strong predictive performance and improved uncertainty calibration across regression and classification tasks.
FastCAV: Efficient Computation of Concept Activation Vectors for Explaining Deep Neural Networks
May 23, 2025Concepts such as objects, patterns, and shapes are how humans understand the world. Building on this intuition, concept-based explainability methods aim to study representations learned by deep neural networks in relation to human-understandable concepts. Here, Concept Activation Vectors (CAVs) are an important tool and can identify whether a model learned a concept or not. However, the computational cost and time requirements of existing CAV computation pose a significant challenge, particularly in large-scale, high-dimensional architectures. To address this limitation, we introduce FastCAV, a novel approach that accelerates the extraction of CAVs by up to 63.6x (on average 46.4x). We provide a theoretical foundation for our approach and give concrete assumptions under which it is equivalent to established SVM-based methods. Our empirical results demonstrate that CAVs calculated with FastCAV maintain similar performance while being more efficient and stable. In downstream applications, i.e., concept-based explanation methods, we show that FastCAV can act as a replacement leading to equivalent insights. Hence, our approach enables previously infeasible investigations of deep models, which we demonstrate by tracking the evolution of concepts during model training.
Probabilistic Embeddings for Frozen Vision-Language Models: Uncertainty Quantification with Gaussian Process Latent Variable Models
May 08, 2025Vision-Language Models (VLMs) learn joint representations by mapping images and text into a shared latent space. However, recent research highlights that deterministic embeddings from standard VLMs often struggle to capture the uncertainties arising from the ambiguities in visual and textual descriptions and the multiple possible correspondences between images and texts. Existing approaches tackle this by learning probabilistic embeddings during VLM training, which demands large datasets and does not leverage the powerful representations already learned by large-scale VLMs like CLIP. In this paper, we propose GroVE, a post-hoc approach to obtaining probabilistic embeddings from frozen VLMs. GroVE builds on Gaussian Process Latent Variable Model (GPLVM) to learn a shared low-dimensional latent space where image and text inputs are mapped to a unified representation, optimized through single-modal embedding reconstruction and cross-modal alignment objectives. Once trained, the Gaussian Process model generates uncertainty-aware probabilistic embeddings. Evaluation shows that GroVE achieves state-of-the-art uncertainty calibration across multiple downstream tasks, including cross-modal retrieval, visual question answering, and active learning.