 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaccadic Vision for Fine-Grained Visual Classification
Sep 19, 2025Fine-grained visual classification (FGVC) requires distinguishing between visually similar categories through subtle, localized features - a task that remains challenging due to high intra-class variability and limited inter-class differences. Existing part-based methods often rely on complex localization networks that learn mappings from pixel to sample space, requiring a deep understanding of image content while limiting feature utility for downstream tasks. In addition, sampled points frequently suffer from high spatial redundancy, making it difficult to quantify the optimal number of required parts. Inspired by human saccadic vision, we propose a two-stage process that first extracts peripheral features (coarse view) and generates a sample map, from which fixation patches are sampled and encoded in parallel using a weight-shared encoder. We employ contextualized selective attention to weigh the impact of each fixation patch before fusing peripheral and focus representations. To prevent spatial collapse - a common issue in part-based methods - we utilize non-maximum suppression during fixation sampling to eliminate redundancy. Comprehensive evaluation on standard FGVC benchmarks (CUB-200-2011, NABirds, Food-101 and Stanford-Dogs) and challenging insect datasets (EU-Moths, Ecuador-Moths and AMI-Moths) demonstrates that our method achieves comparable performance to state-of-the-art approaches while consistently outperforming our baseline encoder.
Probabilistic Embeddings for Frozen Vision-Language Models: Uncertainty Quantification with Gaussian Process Latent Variable Models
May 08, 2025Vision-Language Models (VLMs) learn joint representations by mapping images and text into a shared latent space. However, recent research highlights that deterministic embeddings from standard VLMs often struggle to capture the uncertainties arising from the ambiguities in visual and textual descriptions and the multiple possible correspondences between images and texts. Existing approaches tackle this by learning probabilistic embeddings during VLM training, which demands large datasets and does not leverage the powerful representations already learned by large-scale VLMs like CLIP. In this paper, we propose GroVE, a post-hoc approach to obtaining probabilistic embeddings from frozen VLMs. GroVE builds on Gaussian Process Latent Variable Model (GPLVM) to learn a shared low-dimensional latent space where image and text inputs are mapped to a unified representation, optimized through single-modal embedding reconstruction and cross-modal alignment objectives. Once trained, the Gaussian Process model generates uncertainty-aware probabilistic embeddings. Evaluation shows that GroVE achieves state-of-the-art uncertainty calibration across multiple downstream tasks, including cross-modal retrieval, visual question answering, and active learning.
Deep Learning Pipeline for Automated Visual Moth Monitoring: Insect Localization and Species Classification
Jul 28, 2023



Biodiversity monitoring is crucial for tracking and counteracting adverse trends in population fluctuations. However, automatic recognition systems are rarely applied so far, and experts evaluate the generated data masses manually. Especially the support of deep learning methods for visual monitoring is not yet established in biodiversity research, compared to other areas like advertising or entertainment. In this paper, we present a deep learning pipeline for analyzing images captured by a moth scanner, an automated visual monitoring system of moth species developed within the AMMOD project. We first localize individuals with a moth detector and afterward determine the species of detected insects with a classifier. Our detector achieves up to 99.01% mean average precision and our classifier distinguishes 200 moth species with an accuracy of 93.13% on image cutouts depicting single insects. Combining both in our pipeline improves the accuracy for species identification in images of the moth scanner from 79.62% to 88.05%.
Automated Visual Monitoring of Nocturnal Insects with Light-based Camera Traps
Jul 28, 2023Automatic camera-assisted monitoring of insects for abundance estimations is crucial to understand and counteract ongoing insect decline. In this paper, we present two datasets of nocturnal insects, especially moths as a subset of Lepidoptera, photographed in Central Europe. One of the datasets, the EU-Moths dataset, was captured manually by citizen scientists and contains species annotations for 200 different species and bounding box annotations for those. We used this dataset to develop and evaluate a two-stage pipeline for insect detection and moth species classification in previous work. We further introduce a prototype for an automated visual monitoring system. This prototype produced the second dataset consisting of more than 27,000 images captured on 95 nights. For evaluation and bootstrapping purposes, we annotated a subset of the images with bounding boxes enframing nocturnal insects. Finally, we present first detection and classification baselines for these datasets and encourage other scientists to use this publicly available data.
Automatic Plant Cover Estimation with Convolutional Neural Networks
Jul 02, 2021



Monitoring the responses of plants to environmental changes is essential for plant biodiversity research. This, however, is currently still being done manually by botanists in the field. This work is very laborious, and the data obtained is, though following a standardized method to estimate plant coverage, usually subjective and has a coarse temporal resolution. To remedy these caveats, we investigate approaches using convolutional neural networks (CNNs) to automatically extract the relevant data from images, focusing on plant community composition and species coverages of 9 herbaceous plant species. To this end, we investigate several standard CNN architectures and different pretraining methods. We find that we outperform our previous approach at higher image resolutions using a custom CNN with a mean absolute error of 5.16%. In addition to these investigations, we also conduct an error analysis based on the temporal aspect of the plant cover images. This analysis gives insight into where problems for automatic approaches lie, like occlusion and likely misclassifications caused by temporal changes.
Towards Learning an Unbiased Classifier from Biased Data via Conditional Adversarial Debiasing
Mar 10, 2021
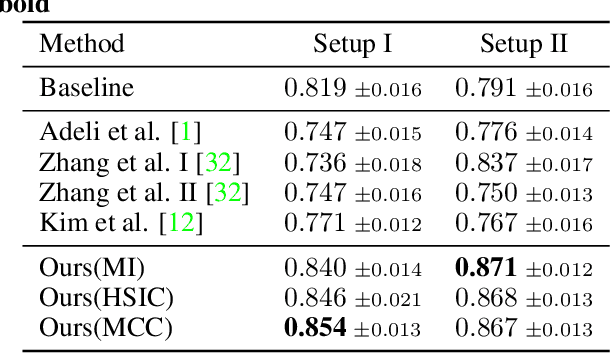

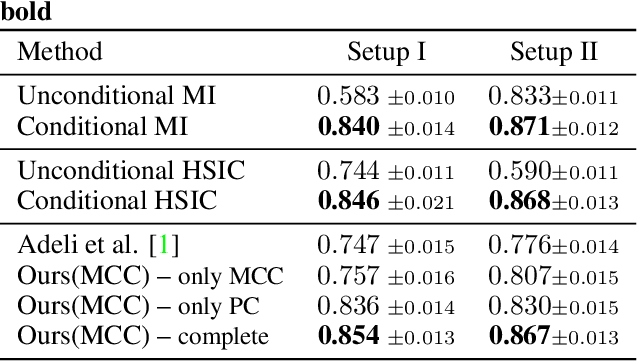
Bias in classifiers is a severe issue of modern deep learning methods, especially for their application in safety- and security-critical areas. Often, the bias of a classifier is a direct consequence of a bias in the training dataset, frequently caused by the co-occurrence of relevant features and irrelevant ones. To mitigate this issue, we require learning algorithms that prevent the propagation of bias from the dataset into the classifier. We present a novel adversarial debiasing method, which addresses a feature that is spuriously connected to the labels of training images but statistically independent of the labels for test images. Thus, the automatic identification of relevant features during training is perturbed by irrelevant features. This is the case in a wide range of bias-related problems for many computer vision tasks, such as automatic skin cancer detection or driver assistance. We argue by a mathematical proof that our approach is superior to existing techniques for the abovementioned bias. Our experiments show that our approach performs better than state-of-the-art techniques on a well-known benchmark dataset with real-world images of cats and dogs.
End-to-end Learning of a Fisher Vector Encoding for Part Features in Fine-grained Recognition
Jul 04, 2020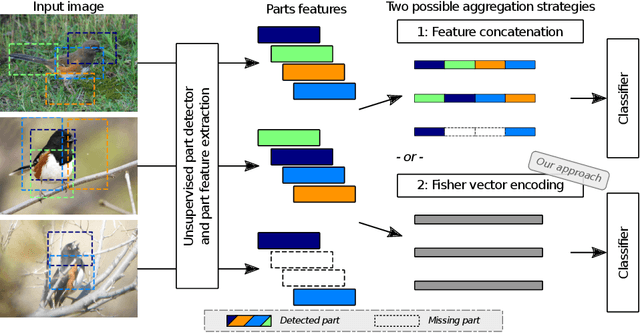
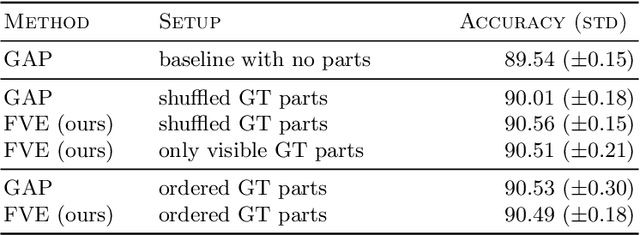
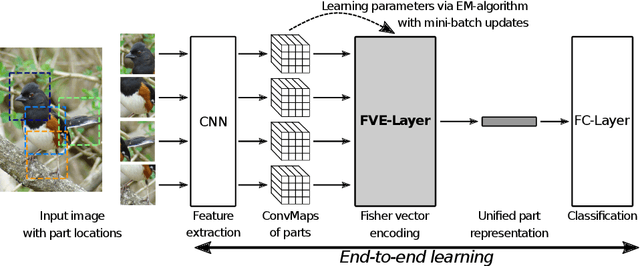
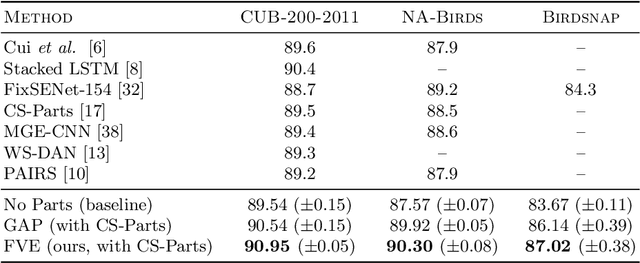
Part-based approaches for fine-grained recognition do not show the expected performance gain over global methods, although being able to explicitly focus on small details that are relevant for distinguishing highly similar classes. We assume that part-based methods suffer from a missing representation of local features, which is invariant to the order of parts and can handle a varying number of visible parts appropriately. The order of parts is artificial and often only given by ground-truth annotations, whereas viewpoint variations and occlusions result in parts that are not observable. Therefore, we propose integrating a Fisher vector encoding of part features into convolutional neural networks. The parameters for this encoding are estimated jointly with those of the neural network in an end-to-end manner. Our approach improves state-of-the-art accuracies for bird species classification on CUB-200-2011 from 90.40\% to 90.95\%, on NA-Birds from 89.20\% to 90.30\%, and on Birdsnap from 84.30\% to 86.97\%.
Classification-Specific Parts for Improving Fine-Grained Visual Categorization
Sep 16, 2019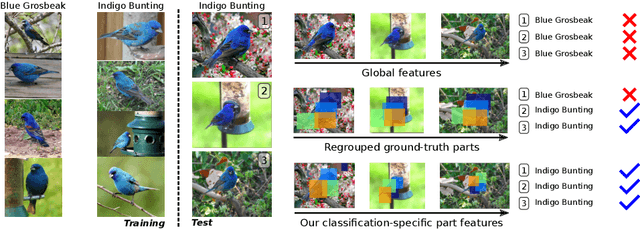
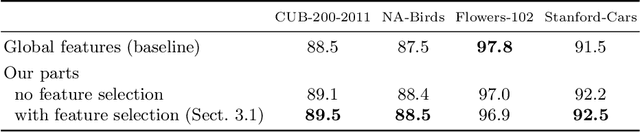
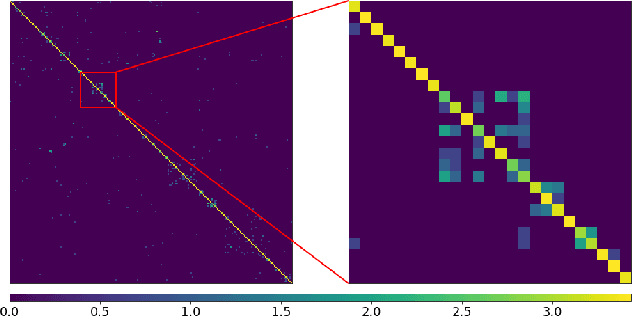
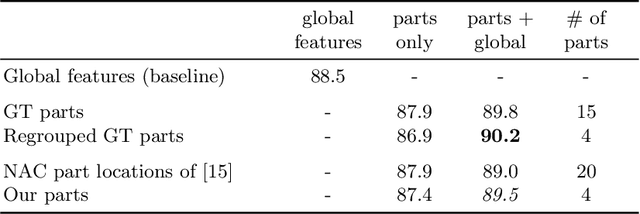
Fine-grained visual categorization is a classification task for distinguishing categories with high intra-class and small inter-class variance. While global approaches aim at using the whole image for performing the classification, part-based solutions gather additional local information in terms of attentions or parts. We propose a novel classification-specific part estimation that uses an initial prediction as well as back-propagation of feature importance via gradient computations in order to estimate relevant image regions. The subsequently detected parts are then not only selected by a-posteriori classification knowledge, but also have an intrinsic spatial extent that is determined automatically. This is in contrast to most part-based approaches and even to available ground-truth part annotations, which only provide point coordinates and no additional scale information. We show in our experiments on various widely-used fine-grained datasets the effectiveness of the mentioned part selection method in conjunction with the extracted part features.
Maximally Divergent Intervals for Anomaly Detection
Oct 21, 2016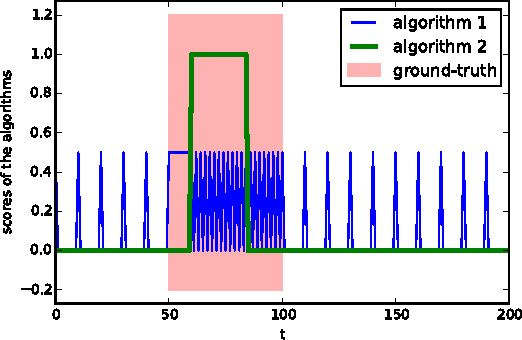
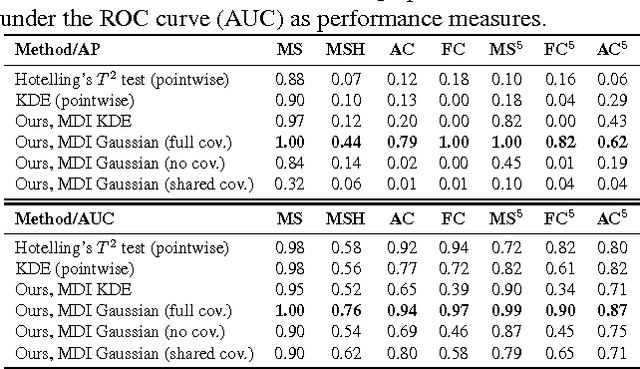
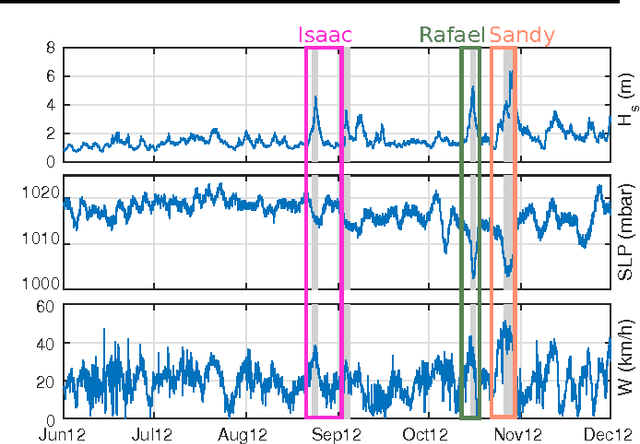
We present new methods for batch anomaly detection in multivariate time series. Our methods are based on maximizing the Kullback-Leibler divergence between the data distribution within and outside an interval of the time series. An empirical analysis shows the benefits of our algorithms compared to methods that treat each time step independently from each other without optimizing with respect to all possible intervals.
Seeing through bag-of-visual-word glasses: towards understanding quantization effects in feature extraction methods
Aug 20, 2014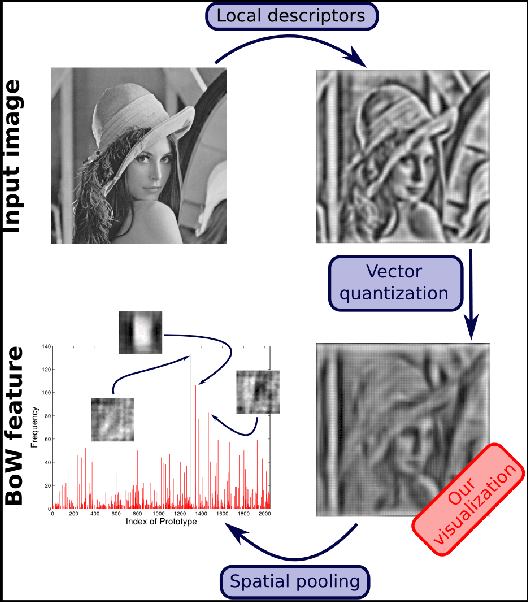



Vector-quantized local features frequently used in bag-of-visual-words approaches are the backbone of popular visual recognition systems due to both their simplicity and their performance. Despite their success, bag-of-words-histograms basically contain low-level image statistics (e.g., number of edges of different orientations). The question remains how much visual information is "lost in quantization" when mapping visual features to code words? To answer this question, we present an in-depth analysis of the effect of local feature quantization on human recognition performance. Our analysis is based on recovering the visual information by inverting quantized local features and presenting these visualizations with different codebook sizes to human observers. Although feature inversion techniques are around for quite a while, to the best of our knowledge, our technique is the first visualizing especially the effect of feature quantization. Thereby, we are now able to compare single steps in common image classification pipelines to human counterparts.