 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Causal Bottleneck Models
Mar 09, 2026We introduce structural causal bottleneck models (SCBMs), a novel class of structural causal models. At the core of SCBMs lies the assumption that causal effects between high-dimensional variables only depend on low-dimensional summary statistics, or bottlenecks, of the causes. SCBMs provide a flexible framework for task-specific dimension reduction while being estimable via standard, simple learning algorithms in practice. We analyse identifiability in SCBMs, connect them to information bottlenecks in the sense of Tishby & Zaslavsky (2015), and illustrate how to estimate them experimentally. We also demonstrate the benefit of bottlenecks for effect estimation in low-sample transfer learning settings. We argue that SCBMs provide an alternative to existing causal dimension reduction frameworks like causal representation learning or causal abstraction learning.
Multidata Causal Discovery for Statistical Hurricane Intensity Forecasting
Oct 02, 2025Improving statistical forecasts of Atlantic hurricane intensity is limited by complex nonlinear interactions and difficulty in identifying relevant predictors. Conventional methods prioritize correlation or fit, often overlooking confounding variables and limiting generalizability to unseen tropical storms. To address this, we leverage a multidata causal discovery framework with a replicated dataset based on Statistical Hurricane Intensity Prediction Scheme (SHIPS) using ERA5 meteorological reanalysis. We conduct multiple experiments to identify and select predictors causally linked to hurricane intensity changes. We train multiple linear regression models to compare causal feature selection with no selection, correlation, and random forest feature importance across five forecast lead times from 1 to 5 days (24 to 120 hours). Causal feature selection consistently outperforms on unseen test cases, especially for lead times shorter than 3 days. The causal features primarily include vertical shear, mid-tropospheric potential vorticity and surface moisture conditions, which are physically significant yet often underutilized in hurricane intensity predictions. Further, we build an extended predictor set (SHIPS+) by adding selected features to the standard SHIPS predictors. SHIPS+ yields increased short-term predictive skill at lead times of 24, 48, and 72 hours. Adding nonlinearity using multilayer perceptron further extends skill to longer lead times, despite our framework being purely regional and not requiring global forecast data. Operational SHIPS tests confirm that three of the six added causally discovered predictors improve forecasts, with the largest gains at longer lead times. Our results demonstrate that causal discovery improves hurricane intensity prediction and pave the way toward more empirical forecasts.
Using Time Structure to Estimate Causal Effects
Apr 15, 2025There exist several approaches for estimating causal effects in time series when latent confounding is present. Many of these approaches rely on additional auxiliary observed variables or time series such as instruments, negative controls or time series that satisfy the front- or backdoor criterion in certain graphs. In this paper, we present a novel approach for estimating direct (and via Wright's path rule total) causal effects in a time series setup which does not rely on additional auxiliary observed variables or time series. This approach assumes that the underlying time series is a Structural Vector Autoregressive (SVAR) process and estimates direct causal effects by solving certain linear equation systems made up of different covariances and model parameters. We state sufficient graphical criteria in terms of the so-called full time graph under which these linear equations systems are uniquely solvable and under which their solutions contain the to-be-identified direct causal effects as components. We also state sufficient lag-based criteria under which the previously mentioned graphical conditions are satisfied and, thus, under which direct causal effects are identifiable. Several numerical experiments underline the correctness and applicability of our results.
Sanity Checking Causal Representation Learning on a Simple Real-World System
Feb 27, 2025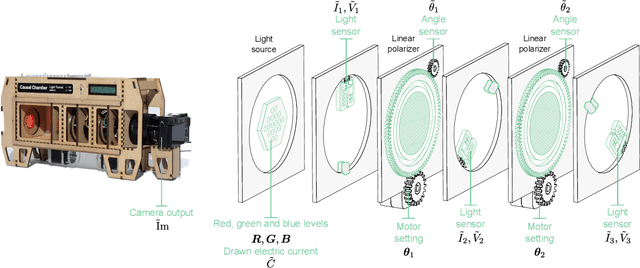


We evaluate methods for causal representation learning (CRL) on a simple, real-world system where these methods are expected to work. The system consists of a controlled optical experiment specifically built for this purpose, which satisfies the core assumptions of CRL and where the underlying causal factors (the inputs to the experiment) are known, providing a ground truth. We select methods representative of different approaches to CRL and find that they all fail to recover the underlying causal factors. To understand the failure modes of the evaluated algorithms, we perform an ablation on the data by substituting the real data-generating process with a simpler synthetic equivalent. The results reveal a reproducibility problem, as most methods already fail on this synthetic ablation despite its simple data-generating process. Additionally, we observe that common assumptions on the mixing function are crucial for the performance of some of the methods but do not hold in the real data. Our efforts highlight the contrast between the theoretical promise of the state of the art and the challenges in its application. We hope the benchmark serves as a simple, real-world sanity check to further develop and validate methodology, bridging the gap towards CRL methods that work in practice. We make all code and datasets publicly available at github.com/simonbing/CRLSanityCheck
Internal Incoherency Scores for Constraint-based Causal Discovery Algorithms
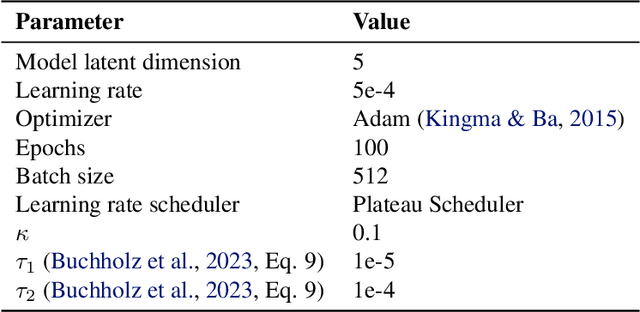
Feb 20, 2025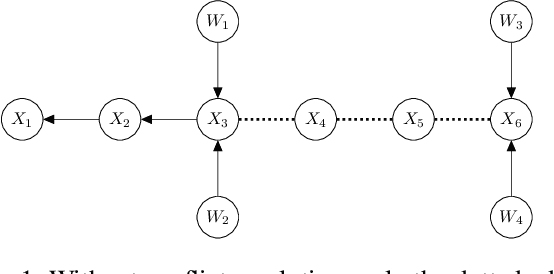
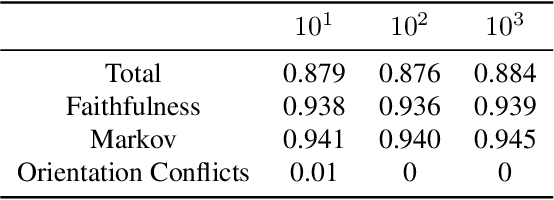
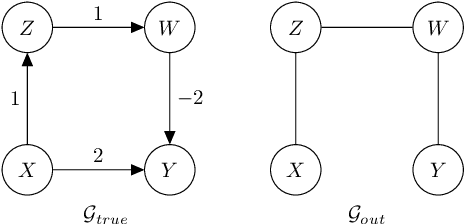
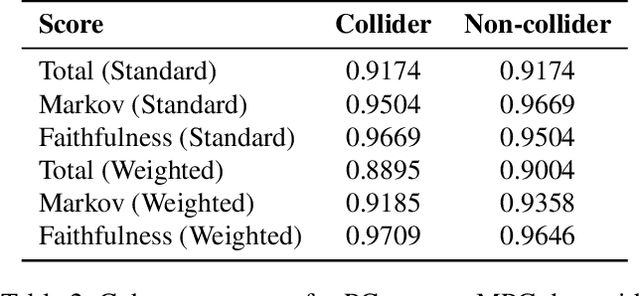
Causal discovery aims to infer causal graphs from observational or experimental data. Methods such as the popular PC algorithm are based on conditional independence testing and utilize enabling assumptions, such as the faithfulness assumption, for their inferences. In practice, these assumptions, as well as the functional assumptions inherited from the chosen conditional independence test, are typically taken as a given and not further tested for their validity on the data. In this work, we propose internal coherency scores that allow testing for assumption violations and finite sample errors, whenever detectable without requiring ground truth or further statistical tests. We provide a complete classification of erroneous results, including a distinction between detectable and undetectable errors, and prove that the detectable erroneous results can be measured by our scores. We illustrate our coherency scores on the PC algorithm with simulated and real-world datasets, and envision that testing for internal coherency can become a standard tool in applying constraint-based methods, much like a suite of tests is used to validate the assumptions of classical regression analysis.
Causal discovery with endogenous context variables
Dec 06, 2024



Causal systems often exhibit variations of the underlying causal mechanisms between the variables of the system. Often, these changes are driven by different environments or internal states in which the system operates, and we refer to context variables as those variables that indicate this change in causal mechanisms. An example are the causal relations in soil moisture-temperature interactions and their dependence on soil moisture regimes: Dry soil triggers a dependence of soil moisture on latent heat, while environments with wet soil do not feature such a feedback, making it a context-specific property. Crucially, a regime or context variable such as soil moisture need not be exogenous and can be influenced by the dynamical system variables - precipitation can make a dry soil wet - leading to joint systems with endogenous context variables. In this work we investigate the assumptions for constraint-based causal discovery of context-specific information in systems with endogenous context variables. We show that naive approaches such as learning different regime graphs on masked data, or pooling all data, can lead to uninformative results. We propose an adaptive constraint-based discovery algorithm and give a detailed discussion on the connection to structural causal models, including sufficiency assumptions, which allow to prove the soundness of our algorithm and to interpret the results causally. Numerical experiments demonstrate the performance of the proposed method over alternative baselines, but they also unveil current limitations of our method.
Causal Modeling in Multi-Context Systems: Distinguishing Multiple Context-Specific Causal Graphs which Account for Observational Support
Oct 27, 2024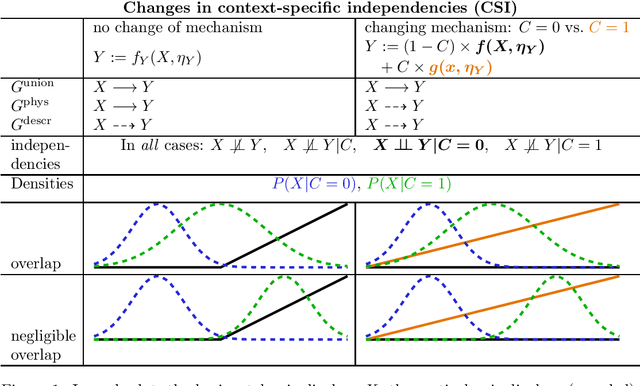
Causal structure learning with data from multiple contexts carries both opportunities and challenges. Opportunities arise from considering shared and context-specific causal graphs enabling to generalize and transfer causal knowledge across contexts. However, a challenge that is currently understudied in the literature is the impact of differing observational support between contexts on the identifiability of causal graphs. Here we study in detail recently introduced [6] causal graph objects that capture both causal mechanisms and data support, allowing for the analysis of a larger class of context-specific changes, characterizing distribution shifts more precisely. We thereby extend results on the identifiability of context-specific causal structures and propose a framework to model context-specific independence (CSI) within structural causal models (SCMs) in a refined way that allows to explore scenarios where these graph objects differ. We demonstrate how this framework can help explaining phenomena like anomalies or extreme events, where causal mechanisms change or appear to change under different conditions. Our results contribute to the theoretical foundations for understanding causal relations in multi-context systems, with implications for generalization, transfer learning, and anomaly detection. Future work may extend this approach to more complex data types, such as time-series.
Causal Representation Learning in Temporal Data via Single-Parent Decoding
Oct 09, 2024



Scientific research often seeks to understand the causal structure underlying high-level variables in a system. For example, climate scientists study how phenomena, such as El Ni\~no, affect other climate processes at remote locations across the globe. However, scientists typically collect low-level measurements, such as geographically distributed temperature readings. From these, one needs to learn both a mapping to causally-relevant latent variables, such as a high-level representation of the El Ni\~no phenomenon and other processes, as well as the causal model over them. The challenge is that this task, called causal representation learning, is highly underdetermined from observational data alone, requiring other constraints during learning to resolve the indeterminacies. In this work, we consider a temporal model with a sparsity assumption, namely single-parent decoding: each observed low-level variable is only affected by a single latent variable. Such an assumption is reasonable in many scientific applications that require finding groups of low-level variables, such as extracting regions from geographically gridded measurement data in climate research or capturing brain regions from neural activity data. We demonstrate the identifiability of the resulting model and propose a differentiable method, Causal Discovery with Single-parent Decoding (CDSD), that simultaneously learns the underlying latents and a causal graph over them. We assess the validity of our theoretical results using simulated data and showcase the practical validity of our method in an application to real-world data from the climate science field.
Metrics on Markov Equivalence Classes for Evaluating Causal Discovery Algorithms
Feb 07, 2024
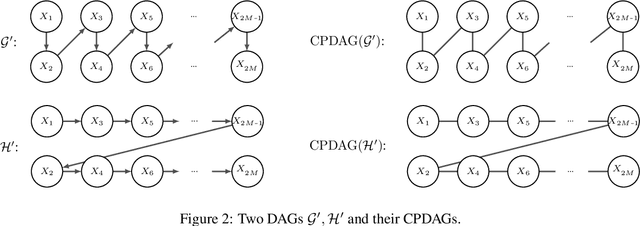
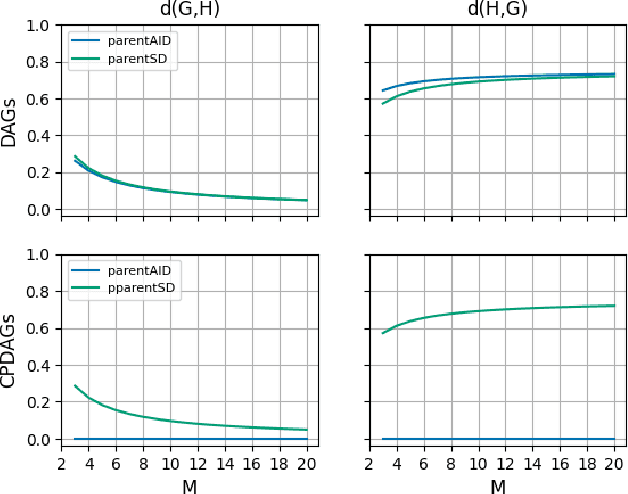
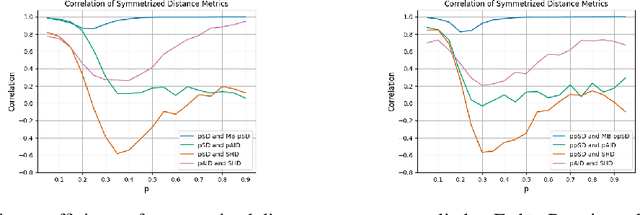
Many state-of-the-art causal discovery methods aim to generate an output graph that encodes the graphical separation and connection statements of the causal graph that underlies the data-generating process. In this work, we argue that an evaluation of a causal discovery method against synthetic data should include an analysis of how well this explicit goal is achieved by measuring how closely the separations/connections of the method's output align with those of the ground truth. We show that established evaluation measures do not accurately capture the difference in separations/connections of two causal graphs, and we introduce three new measures of distance called s/c-distance, Markov distance and Faithfulness distance that address this shortcoming. We complement our theoretical analysis with toy examples, empirical experiments and pseudocode.
Invariance & Causal Representation Learning: Prospects and Limitations
Dec 06, 2023In causal models, a given mechanism is assumed to be invariant to changes of other mechanisms. While this principle has been utilized for inference in settings where the causal variables are observed, theoretical insights when the variables of interest are latent are largely missing. We assay the connection between invariance and causal representation learning by establishing impossibility results which show that invariance alone is insufficient to identify latent causal variables. Together with practical considerations, we use these theoretical findings to highlight the need for additional constraints in order to identify representations by exploiting invariance.